Topic 6: The Normal Distribution
About
This activity covers working with normally distributed data, including the calculation of probabilities and percentiles, and introduces the notion of the z-score.
Note. The button above resets multiple choice and checkbox questions. Currently, resetting code cells must be done manually via hitting the Start Over button on each individual interactive cell.
The Normal Distribution
Throughout this activity we’ll investigate the probability distribution that is most central to our study of statistics: the normal distribution. If we are confident that our data are nearly normal, that opens the door for us to leverage many powerful statistical methods. This activity gives you practice working with normally distributed data.
Objectives
Workbook Objectives: After completing this workbook you should be able to:
- Compute probabilities of events from populations well-modeled by a normal distribution.
- Given a variable \(X\) which follows an assumed normal distribution, compute and interpret various percentile thresholds for \(X\).
- Identify scenarios to which the normal or binomial distributions can be applied, and use the appropriate distribution to answer various probability-related questions.
The Normal Distribution
Definition: If a random variable \(X\) is normally distributed with mean \(\mu\) and standard deviation \(\sigma\), we often write \(X\sim N\left(\mu, \sigma\right)\). Three different normal distributions appear below.
- In blue is a normal distribution with \(\mu = 0\) and \(\sigma = 5\)
- In red is a normal distribution with \(\mu = 0\) and \(\sigma = 0.5\)
- In black is a normal distribution with \(\mu = 0\) and \(\sigma = 1\) (the so-called Standard Normal Distribution)
Notice that all three distributions are bell-shaped and are centered at their mean (\(\mu = 0\)). The larger the standard deviation, the shorter and wider the curve, while the smaller the standard deviation, the taller and more narrow the curve.
Given that \(X\sim N\left(\mu, \sigma\right)\), we can compute probabilities associated with observed values of \(X\) by finding the corresponding area beneath the normal curve having mean \(\mu\) and standard deviation \(\sigma\).
Properties of the Normal Distribution: Consider \(X\sim N\left(\mu, \sigma\right)\).
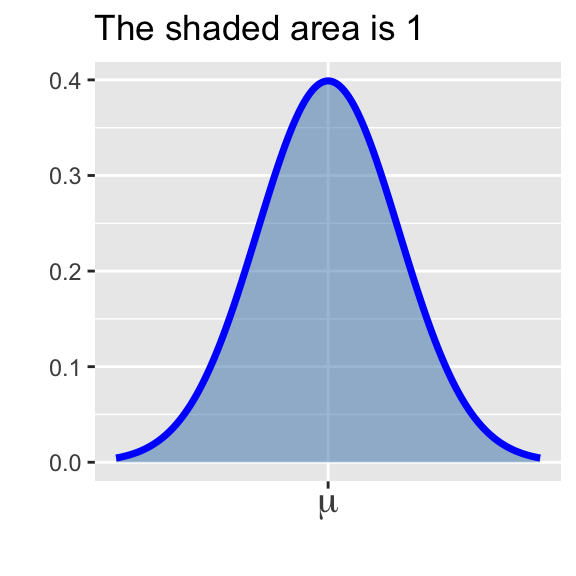
- The area beneath the entire distribution is 1 (since this is equivalent to the probability that \(X\) takes on any of its possible values).
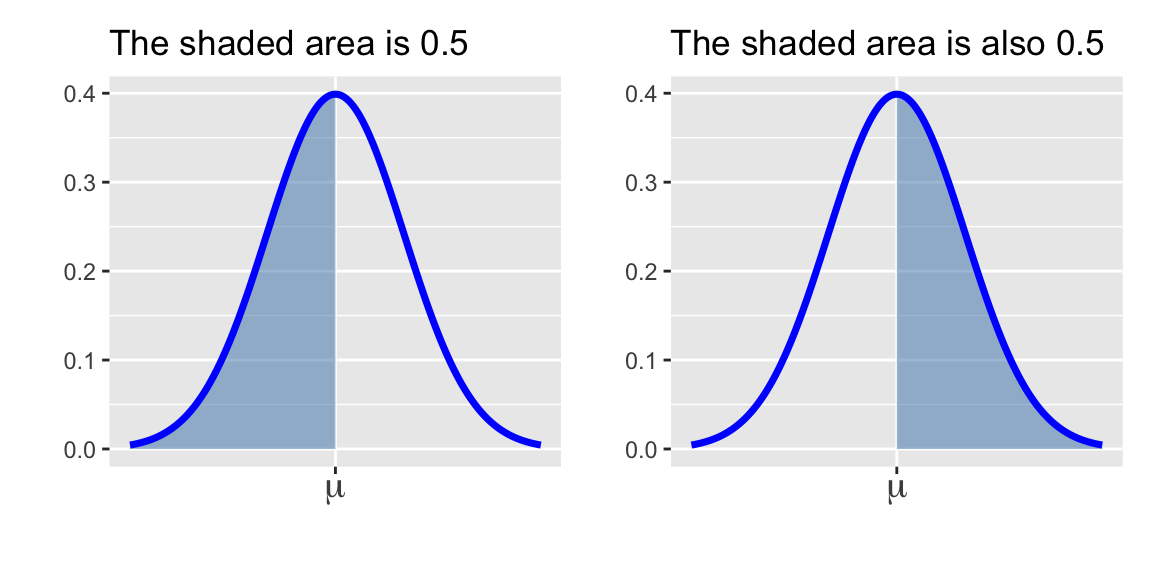
- \(\displaystyle{\mathbb{P}\left[X\leq \mu\right] = \mathbb{P}\left[X\geq \mu\right] = 0.5}\) (the area underneath a full half of the distribution is 0.5)
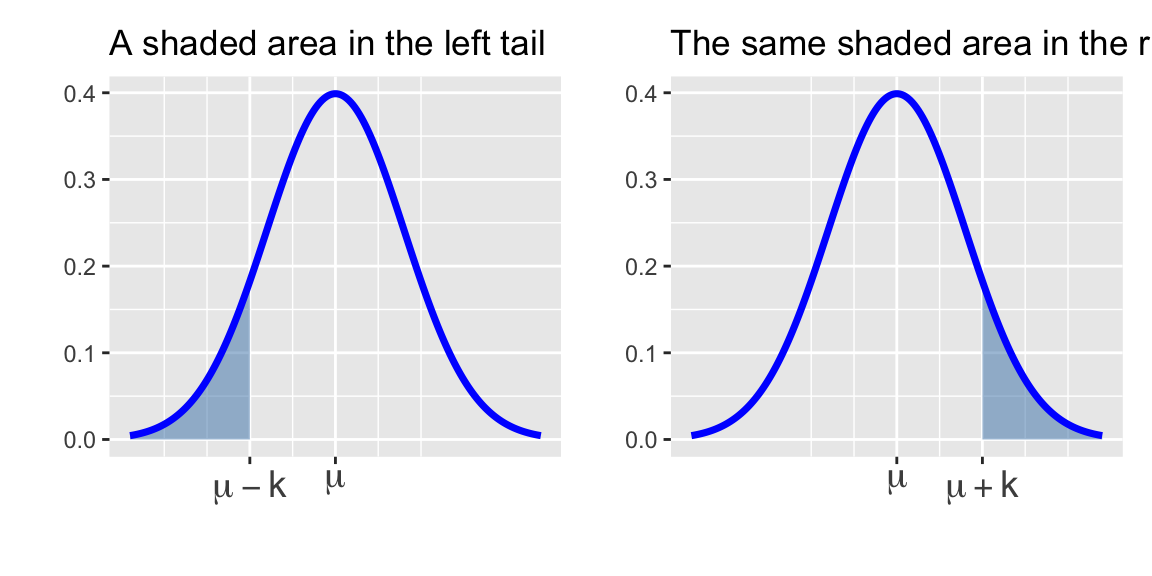
- The distribution is symmetric. In symbols, we write \(\mathbb{P}\left[X\leq \mu - k\right] = \mathbb{P}\left[X \geq \mu + k\right]\) for any \(k\). Geometrically, this means that corresponding lower-tail (left-tail) and upper-tail (right-tail) areas are equal.
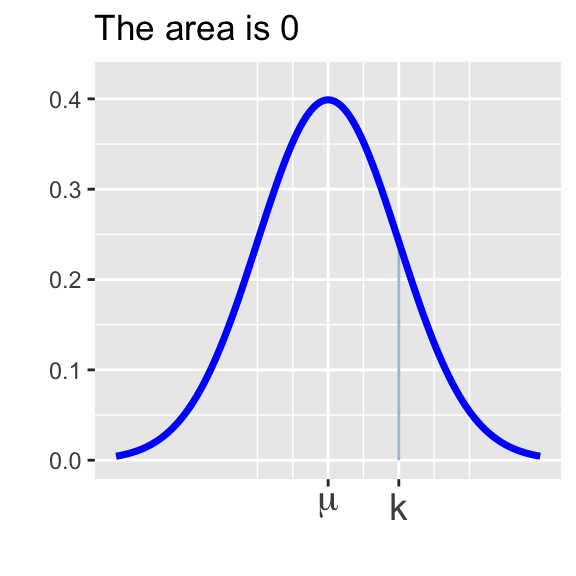
- \(\displaystyle{\mathbb{P}\left[X = k\right] = 0}\) (the probability that \(X\) takes on any prescribed value exactly is \(0\))
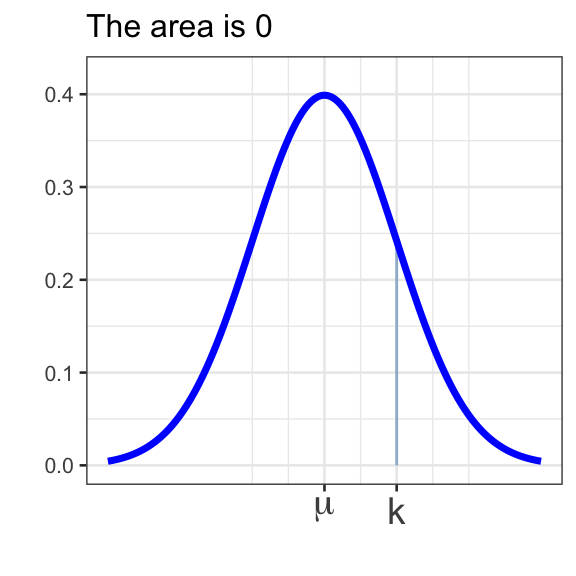
Important
Unlike the binomial distribution, where the distinction between at least and more than required careful adjustment, the probability that a continuous variable \(X\) takes on any prescribed value exactly is \(0\) (that is, \(\mathbb{P}\left[X = k\right] = 0\)). This means there is no difference between \(\mathbb{P}\left[X \leq k\right]\) and \(\mathbb{P}\left[X < k\right]\). Similarly, there is no difference between \(\mathbb{P}\left[X \geq k\right]\) and \(\mathbb{P}\left[X > k\right]\).
Sometimes it is useful to be able to estimate probabilities or to estimate the proportion of a population that falls into a range. As long as the population is nearly normal, a convenient set of rough estimates come from the Empirical Rule.
The Empirical Rule
If \(X\sim N\left(\mu, \sigma\right)\), then
- \(\mathbb{P}\left[\mu - \sigma \leq X\leq \mu + \sigma\right] \approx 0.67\) — that is, about 67% of observations lie within one standard deviation of the mean.
- \(\mathbb{P}\left[\mu - 2\sigma \leq X\leq \mu + 2\sigma\right] \approx 0.95\) — that is, about 95% of observations lie within two standard deviations of the mean.
- \(\mathbb{P}\left[\mu - 3\sigma \leq X\leq \mu + 3\sigma\right] \approx 0.997\) — that is, about 99.7% of observations lie within three standard deviations of the mean.
For each of the following, assume that \(X\sim N\left(\mu = 85, \sigma = 5\right)\).
Check Your Understanding: The Empirical Rule I
Use the Empirical Rule to approximate \(\mathbb{P}\left[80\leq X\leq 90\right]\).
Check Your Understanding: The Empirical Rule II
According to the Empirical Rule, which of the following are boundary values for which we expect about 95% of observed values of \(X\) to fall between?
Standardization and \(z\)-Scores
Scenario: Two students, Bob and Sally, are trying to compare how well they did on a college entrance exam. The difficulty comes in that Bob took the SAT which is known to follow an approximate normal distribution with a mean score of 1068 and a standard deviation of 210, while Sally took the ACT which also follows an approximately normal distribution but with a mean score of 20.8 and a standard deviation of 5.8. If Bob scored a 1400 on the SAT and Sally scored a 31 on the ACT, who scored relatively higher?
How do we answer this question? We’ll see two methods.
Method 1: We can standardize the test scores so that they have comparable units.
Definition (z-score): If an observation \(x\) comes from a nearly normal population with mean \(\mu\) and standard deviation \(\sigma\), then we compute the \(z\)-score associated with \(x\) as follows:
\[\displaystyle{z = \frac{x - \mu}{\sigma}}\]
An observation’s \(z\)-score is simply the number of standard deviations it falls above or below the mean.
Use the code block below to compute Bob and Sally’s \(z\)-scores and answer the questions that follow.
Hint 1
Use the \(z\)-score formula above: \((x - \mu) / \sigma\).
Hint 2
Fill in the blanks:
(___ - ___) / ___
Hint 3
Bob took the SAT exam, where the mean score (\(\mu\)) was 1068.
(___ - 1068) / ___
Hint 4
The standard deviation (\(\sigma\)) on the SAT exam was 210.
(___ - 1068) / 210
Hint 5
Bob’s score on the SAT exam was 1400.
(1400 - 1068) / 210
Hint 6
Now do the same for Sally, but be sure to use the mean (\(\mu\)) and standard deviation (\(\sigma\)) from the ACT exam, since that’s the exam she completed.
# Bob
(1400 - 1068) / 210
# Sally
(___ - ___) / ___
Hint 7
The average score for the ACT was 20.8.
# Bob
(1400 - 1068) / 210
# Sally
(___ - 20.8) / ___
Hint 8
The standard deviation in ACT scores was 5.8.
# Bob
(1400 - 1068) / 210
# Sally
(___ - 20.8) / 5.8
Hint 9 (Solved)
Sally’s score on the ACT was 31.
# Bob
(1400 - 1068) / 210
# Sally
(31 - 20.8) / 5.8
Check Your Understanding: \(z\)-Scores I
Which of the following is the \(z\)-score corresponding to Bob? (round to two decimal places)
Check Your Understanding: \(z\)-Scores II
Which of the following is the \(z\)-score corresponding to Sally? (round to two decimal places)
Check Your Understanding: \(z\)-Scores III
Who did relatively better on their standardized exam, Bob or Sally? Why?
A Recap on \(z\)-Scores
We can use \(z\)-scores as a common unit for comparing observations from completely different populations (such as SAT scores and ACT scores). Here’s a recap of the most important information so far:
- If an observation \(x\) comes from a nearly normal population with mean \(\mu\) and standard deviation \(\sigma\), we can compute its \(z\)-score using the formula: \(\displaystyle{z = \frac{x - \mu}{\sigma}}\).
- A \(z\)-score measures the number of standard deviations which an observation falls above or below the mean.
- A positive \(z\)-score means that an observation was above the mean.
- A negative \(z\)-score means that an observation was below the mean.
- The larger a \(z\)-score is in absolute value, the further the corresponding observation falls from the mean.
Method 2: We can compute the percentile corresponding to Bob’s SAT score and the percentile corresponding to Sally’s ACT score.
Definition (percentile): Given an observation \(x\) from a population, the percentile corresponding to \(x\) is the proportion of the population which falls at or below \(x\).
In the images below, Bob’s percentile is shown as the shaded area in the distribution on the left, while Sally’s is shown in the distribution on the right.
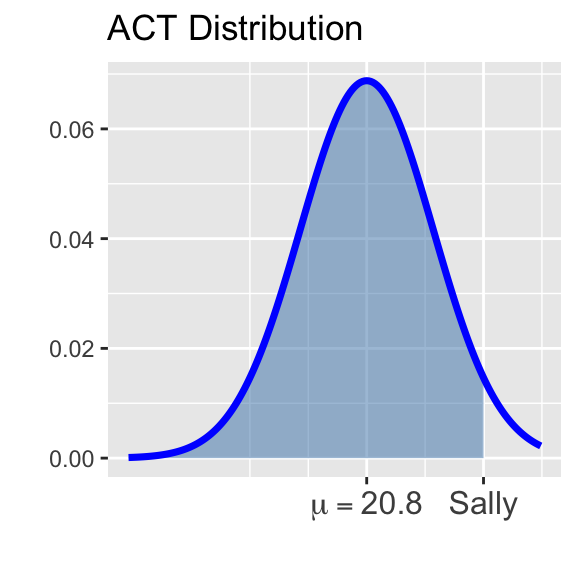
There are many ways to compute percentiles. Before the widespread availability of statistical software, people converted observed values to \(z\)-scores and then looked up the percentile in a table. Luckily R provides nice functionality for computing percentiles.
Computing Percentiles in R
If \(X\sim N\left(\mu, \sigma\right)\), then \[\mathbb{P}\left[X\leq q\right] \approx \tt{pnorm(q, mean = \mu, sd = \sigma)}\]
The block below is preset to compute Bob’s percentile. Execute the code cell and then adapt the code to find Sally’s percentile. Use your results to answer the questions below.
Hint 1
Run this code to compute Bob’s percentile, then adapt it for Sally.
pnorm(1400, 1068, 210)
Hint 2
The arguments for pnorm() are, in order: the boundary value, the distribution mean (\(\mu\)), and the distribution standard deviation (\(\sigma\)).
Hint 3
Fill in the blanks using Sally’s ACT score, the mean ACT score, and the standard deviation in ACT scores.
# Bob
pnorm(1400, 1068, 210)
# Sally
pnorm(___, ___, ___)
Check Your Understanding: Percentiles I
Which of the following is the percentile corresponding to Bob? (round to four decimal places)
Check Your Understanding: Percentiles II
Which of the following is the percentile corresponding to Sally? (round to four decimal places)
Check Your Understanding: Percentiles III
Who did relatively better on their standardized exam, Bob or Sally? Why?
We’ll make good use of this second method for a while, but don’t forget about standardization and \(z\)-scores. We’ll need that strategy quite often later in our course! For now, let’s move on to practicing with finding probabilities from a normal distribution using R’s pnorm() function.
Computing Probability from a Normal Distribution
Through this section you’ll be getting practice finding probabilities by using R’s pnorm() function to compute areas. Remember that the pnorm() function takes three arguments — the first is a boundary value, the second is the mean of the distribution, and the third is the standard deviation. The value returned by pnorm() is the area to the left of the provided boundary value in the distribution with the mean and standard deviation you provided.
For these first few questions I’ll draw pictures for you, but you should be prepared to draw your own shortly.
Question 1: Use the code block below to find \(\mathbb{P}\left[Z <\right.\) \(\left.\right]\) — remember that \(Z\sim N\left(\mu = 0, \sigma = 1\right)\).
Hint 1
Be sure you can answer: “why does the picture to the right correspond to the probability requested?”
Hint 2
Use the pnorm() function with the boundary of the shaded region as the first argument, the mean (\(\mu\)) of the normal distribution as the second, and the standard deviation (\(\sigma\)) as the third.
pnorm(___, ___, ___)
Hint 3
The notation \(Z \sim N(\mu = 0, \sigma = 1)\) indicates that the mean is 0 and the standard deviation is 1. The boundary value is .
pnorm(___, 0, 1)
pnorm(boundary1, 0, 1)
pnorm(boundary1, 0, 1)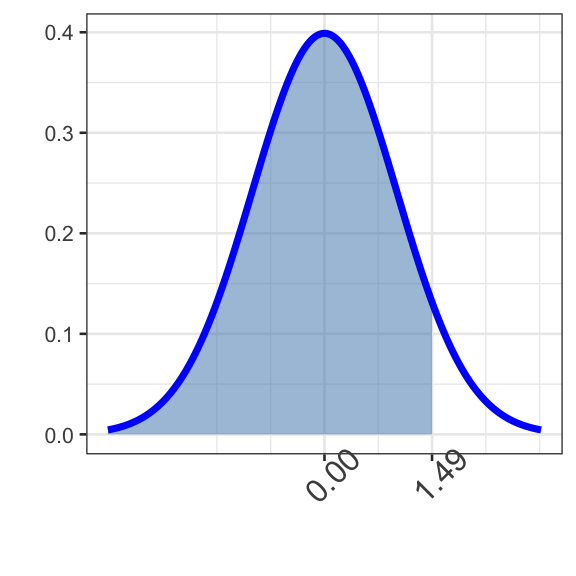
Question 2: Find \(\mathbb{P}\left[Z <\right.\) \(\left.\right]\).
Hint 1
Would you be able to draw the picture if I hadn’t provided it? Try practicing this picture-drawing skill because it will serve you well.
Hint 2
How “big” do you expect this probability to be? Should it be more than 0.5? Less than 0.5? Why?
Hint 3
Remembering that the entire area under this normal distribution is 1 and that the distribution is symmetric, we should expect our answer to be less than 0.5, since the shaded area covers less than half of the entire distribution.
Hint 4
Answer this question exactly the way you answered the previous one. The boundary value here is .The pnorm() function will always give you the area to the left of your provided boundary value — which is what you want here.
pnorm(___, ___, ___)
pnorm(boundary2, 0, 1)
pnorm(boundary2, 0, 1)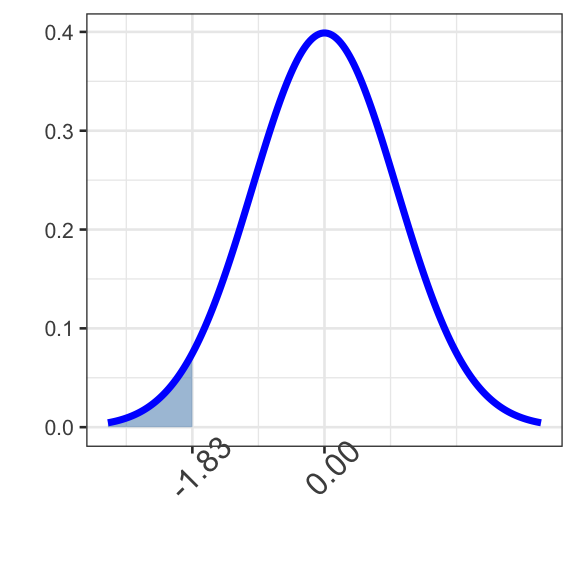
Question 3: Find \(\mathbb{P}\left[Z >\right.\) \(\left.\right]\).
Hint 1
This one is similar to the previous two questions — but what is different about it?
Hint 2
The shaded area is to the right of the boundary value.
Hint 3
The pnorm() function gives us the area to the left of our boundary value, not the area to the right. Can we still find a way to use pnorm()?
Hint 4
When encountering a similar scenario with the binomial distribution, we started with a probability that was too big and removed the probability associated with events we weren’t interested in. Can we apply those same ideas here?
Hint 5
If we start with the entire area under the normal curve and remove the unshaded area, we should be left with just the shaded area.
Hint 6
Fill in the blanks:
___ - pnorm(___, ___, ___)
Hint 7
The total area under the entire normal distribution is 1. That’s your starting point — what do you subtract from it?
1 - pnorm(___, ___, ___)
Hint 8
This is still the standard normal distribution \(N\left(\mu = 0, \sigma = 1\right)\). We just want to remove the unshaded area in the lower (left) tail of the distribution.
1 - pnorm(___, 0, 1)
Hint 9 (Solved)
That’s the area to the left of . Fill in the blank below with .
1 - pnorm(___, 0, 1)
1 - pnorm(boundary3, 0, 1)
1 - pnorm(boundary3, 0, 1)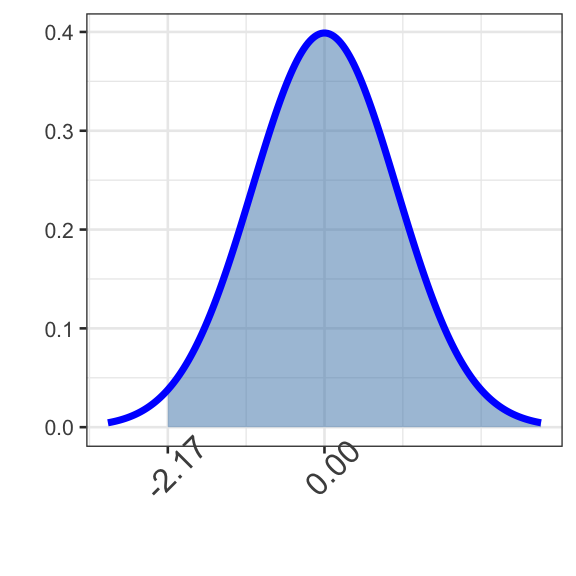
Question 4: Find \(\mathbb{P}\left[Z >\right.\) \(\left.\right]\).
Hint 1
Take the same approach as you used to answer the previous question.
Hint 2
How “big” should your answer be? More than 0.5? Less than 0.5? How do you know?
Hint 3
To compute the probability to the right of your boundary value, subtract the probability to the left of the boundary value away from 1.
___ - pnorm(___, ___, ___)
Hint 4 (Solved)
The boundary value is and the distribution is \(N(0, 1)\). Fill in the blank below with .
1 - pnorm(___, 0, 1)
1 - pnorm(boundary4, 0, 1)
1 - pnorm(boundary4, 0, 1)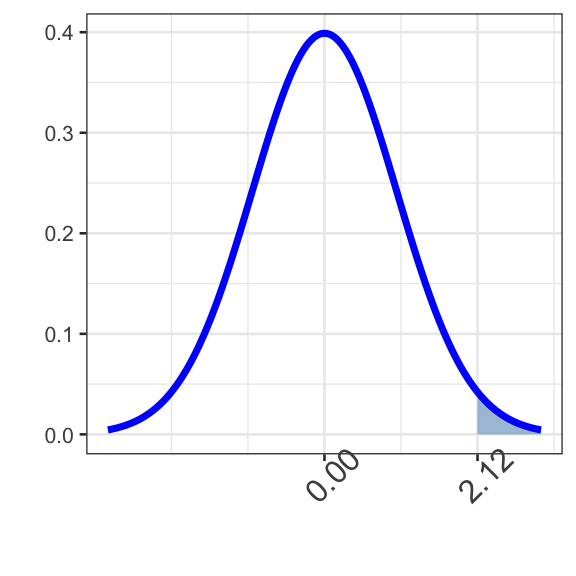
Question 5: Find \(\mathbb{P}\left[\right.\) \(< Z <\) \(\left.\right]\).
Hint 1
What makes this one different from all of the previous questions?
Hint 2
Even our “subtract-from-one” trick won’t work easily here, because pnorm() computes the area into the tail of the distribution from a single boundary value.
Hint 3
Is there a way to compute an area (probability) that is too big to start, where that bigger area shares a boundary with the shaded area we ultimately want to find?
Hint 4
Filling the first argument of pnorm(___, 0, 1) with gives an area larger than what we want. It shares a right-side boundary with our target area. Can we subtract something from it?
pnorm(___, 0, 1) - ___
Hint 5
Fill in the blanks — the first blank is :
pnorm(___, 0, 1) - pnorm(___, 0, 1)
Hint 6 (Solved)
Subtract the area to the left of the left-most boundary value. The two values are (first blank) and (second blank).
pnorm(___, 0, 1) - pnorm(___, 0, 1)
pnorm(boundary5b, 0, 1) - pnorm(boundary5a, 0, 1)
pnorm(boundary5b, 0, 1) - pnorm(boundary5a, 0, 1)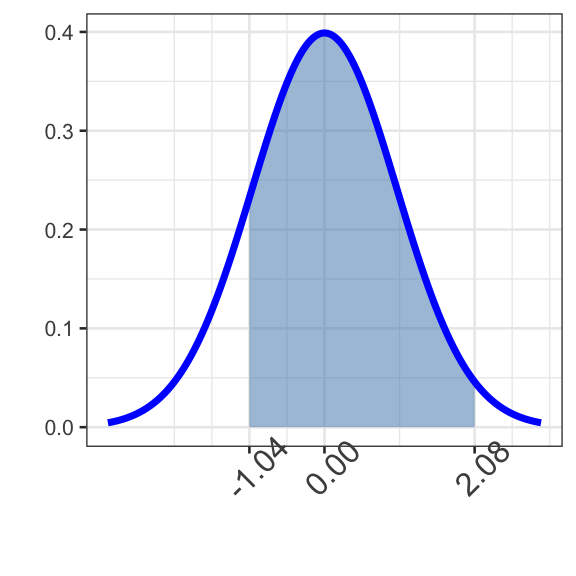
Question 6: Find \(\mathbb{P}\left[Z <\right.\) \(\text{ or } Z >\) \(\left.\right]\).
Hint 1
Something is slightly different here. How is this question different from — and similar to — the questions you’ve previously answered?
Hint 2
There are lots of ways to approach this one. A natural approach is to compute the two shaded areas separately and then add them together.
Hint 3
First, calculate the area to the left of . Then calculate the area to the right of — you’ll need the “subtract-from-one” approach for that second piece.
Hint 4 (Solved)
Once you have both areas, add them together. The two boundary values are (left) and (right).
pnorm(___, 0, 1) + (1 - pnorm(___, 0, 1))
pnorm(boundary6a, 0, 1) + (1 - pnorm(boundary6b, 0, 1))
pnorm(boundary6a, 0, 1) + (1 - pnorm(boundary6b, 0, 1))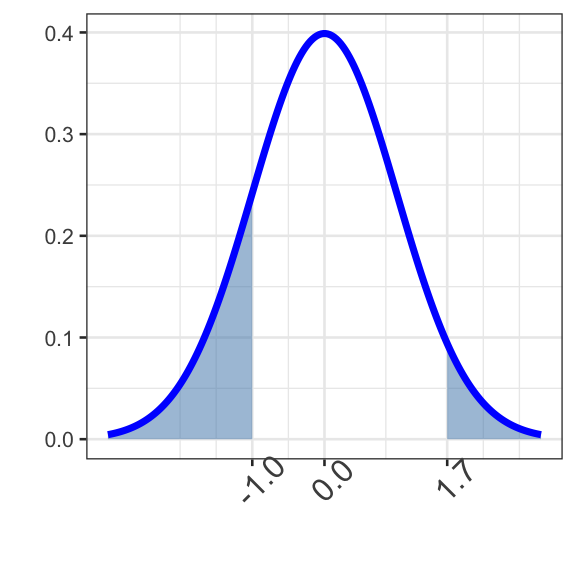
Question 7: Find \(\mathbb{P}\left[\left|Z\right| >\right.\) \(\left.\right]\).
Hint 1
Recall that \(|Z|\) denotes the absolute value of \(Z\), which measures distance from 0. We are interested in values of \(Z\) whose distance from 0 exceeds .
See how this description aligns with the picture drawn on the right?
Hint 2
You can answer this question in the same way as the previous question. Use the picture to guide you.
Hint 3
It can actually be made a little easier than the previous question if you remember that our distribution is symmetric (though that previous approach works perfectly, still). What must be true about the area in the left tail and the area in the right tail?
Hint 4
Since the two tail areas are equal, just calculate one of them and double it. The two boundary values are (left) and (right).
2 * pnorm(___, 0, 1)
Hint 5 (Solved)
Since the two tail areas are equal, just calculate one of them and double it. The two boundary values are (left) and (right).
Use the lower tail (left) boundary () as the first argument to pnorm() below, since pnorm() calculates the area to the left of a given boundary value.
2 * pnorm(___, 0, 1)
2 * pnorm(-boundary7, 0, 1)
2 * pnorm(-boundary7, 0, 1)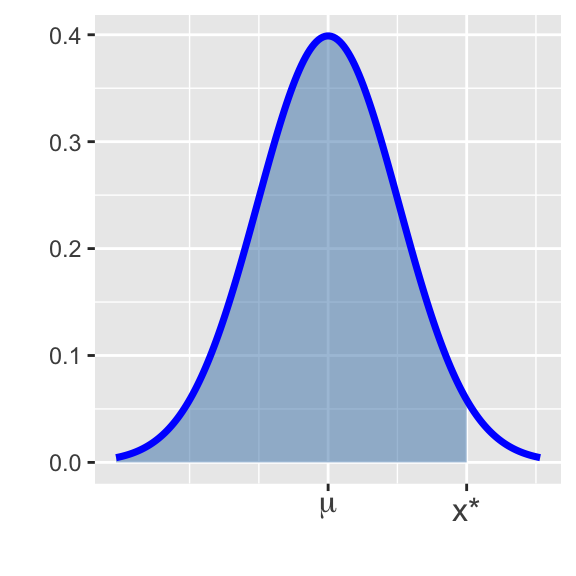
Probabilities from Other Normal Distributions
Through the last seven problems you only worked with the standard normal distribution — that’s the \(Z\)-distribution, which is \(N\left(\mu = 0, \sigma = 1\right)\). We can find probabilities from arbitrary normal distributions using R’s pnorm() functionality — just supply the appropriate mean and sd arguments instead of the 0 and 1 we used in these problems.
Finding Percentile Cutoffs on a Normal Distribution
Recall from earlier that the \(p^{th}\) percentile of a random variable \(X\) is the value \(x^*\) such that \(\mathbb{P}\left[X < x^*\right] = p\).
If \(X\sim N\left(\mu, \sigma\right)\), then to find the cutoff \(x^*\) for which \(\mathbb{P}\left[X < x^*\right] = p\), we can use R’s qnorm() function. Similar to pnorm(), this function takes three arguments. The first is the area to the left of the desired cutoff, the second is the mean of the distribution, and the third is the standard deviation.
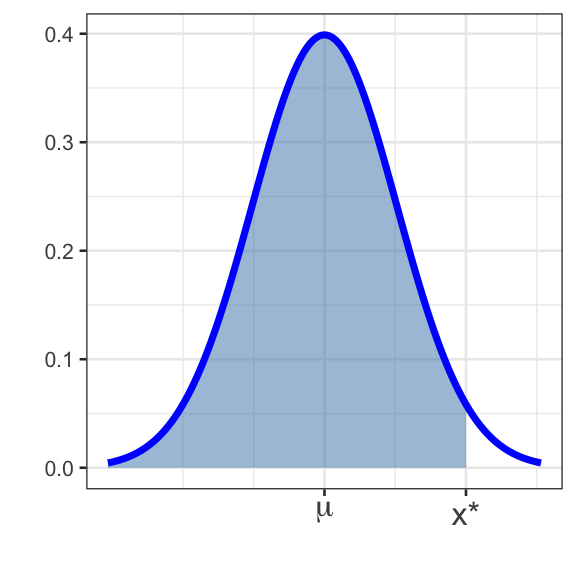
Recall from earlier that SAT scores followed \(N\left(\mu = 1068, \sigma = 210\right)\) and ACT scores followed \(N\left(\mu = 20.8, \sigma = 5.8\right)\). The code block below is set up to find the minimum required SAT score to fall in the 95th percentile. Execute the code and note the required score. Then adapt the code to find the minimum ACT score required to fall into the top 10% of all ACT test takers. Does your answer seem right?
Hint 1
The arguments to qnorm() are, in order: the area to the left of the desired cutoff, the mean of the normal distribution, and the standard deviation.
Hint 2
Fill in the blanks for the ACT version:
# SAT 95th percentile
qnorm(0.95, 1068, 210)
# ACT top 10%
qnorm(___, 20.8, 5.8)
Hint 3
The first argument is the area to the left of the desired cutoff score. What should this area be if we want the top 10% of all scores?
# SAT 95th percentile
qnorm(0.95, 1068, 210)
# ACT top 10%
qnorm(___, 20.8, 5.8)
Hint 4 (Solved)
To be in the top 10%, a score must exceed 90% of all other scores, so the area to the left is 0.90. Use 0.90 as the first agument to the qnorm() function corresponding to ACT scores below.
# SAT 95th percentile
qnorm(0.95, 1068, 210)
# ACT top 10%
qnorm(0.90, 20.8, 5.8)
qnorm(0.95, 1068, 210)
qnorm(0.9, 20.8, 5.8)
qnorm(0.95, 1068, 210)
qnorm(0.9, 20.8, 5.8)Practice with the Normal and Binomial Distributions
Through this last section you’ll work through a set of problems, some of which use the normal distribution while others use the binomial distribution. It is up to you to determine which distribution should be applied in each problem. Below are a few helpful reminders:
Binomial and Normal Distributions Recap
- The binomial distribution can be applied to scenarios of repeated trials, where each trial has two possible outcomes and the probability of “success” on each trial remains constant. If \(X\) is the number of successes in a binomial experiment with \(n\) trials and probability of success \(p\):
- \(\mathbb{P}\left[X = k\right] = \tt{dbinom(k, n, p)}\)
- \(\mathbb{P}\left[X \leq k\right] = \tt{pbinom(k, n, p)}\)
- The normal distribution can be applied to scenarios where data follows at least a nearly-normal distribution. If \(X\sim N\left(\mu, \sigma\right)\):
- \(\mathbb{P}\left[X \leq k\right] = \tt{pnorm(k, mean = \mu, sd = \sigma)}\)
- The \(p^{th}\) percentile of \(X\) is given by \(\tt{qnorm(p, mean = \mu, sd = \sigma)}\)
Practice Problem 1: The National Vaccine Information Center estimates that 90% of Americans have had chickenpox by the time they reach adulthood. Suppose we take a random sample of American adults. Answer each of the following:
- Compute the expected number of adults in our sample who will have had chickenpox.
Hint 1
Is this scenario best-modeled by a binomial distribution, a normal distribution, or something else?
Hint 2
There are adults being surveyed, they are from a random sample (independent), and each is being asked a yes/no question — “have you had chickenpox?” This fits the assumptions of a binomial experiment.
Hint 3
At the end of the Topic 5 activity, you were introduced to the expected value formula for binomial random variables: \(\mathbb{E}[X] = n \cdot p\), where \(n\) is the total number of trials and \(p\) is the probability of success on any given trial.
Hint 4 (Solved)
There are trials and the probability that a randomly chosen adult has had chickenpox is 0.90.
___ * ___
chickPoxSampSize * 0.90
chickPoxSampSize * 0.90- Compute the standard deviation in number of adults who will have had chickenpox across samples of size .
Hint 1
You were introduced to the formula for the standard deviation of a binomial random variable at the end of the Topic 5 activity.
Hint 2
The formula is \(s_X = \sqrt{n \cdot p \cdot (1 - p)}\). Here \(n\) = and \(p\) = 0.90.
sqrt(___ * ___ * (1 - ___))
sqrt(chickPoxSampSize * 0.9 * 0.1)
sqrt(chickPoxSampSize * 0.9 * 0.1)
Check Your Understanding: Surprising Results?
Would you be surprised if your sample of adults contained at most adults who have had chickenpox? Why? Select all that are appropriate.
While you answer the following questions, it might be useful to refer back to the Game of Dreidel example and solution from the Topic 5 activity.
- Find the probability that exactly adults in your sample of will have had chickenpox.
Hint 1
We have four useful functions: dbinom(), pbinom(), pnorm(), and qnorm(). Are any of them useful here?
Hint 2
We can narrow it down to dbinom() or pbinom() since we know we’re working with a binomial random variable.
Hint 3
dbinom() is useful when we are interested in observing exactly some specific number of successes. pbinom() is most useful when we are interested in at most some number of successes.
Hint 4
There are adults in our sample, so the number of trials is . Fill in the second blank below with .
dbinom(___, ___, ___)
Hint 5
There are adults in our sample, so the number of trials is . Fill in the second blank below with .
The probability of an individual adult having had chickenpox is 0.90. Fill in the third blank with 0.90.
dbinom(___, ___, ___)
Hint 6 (Solved)
There are adults in our sample, so the number of trials is . Fill in the second blank below with .
The probability of an individual adult having had chickenpox is 0.90. Fill in the third blank with 0.90.
We are interested in exactly adults having had chickenpox, so fill in the first blank with .
dbinom(___, ___, ___)
dbinom(chickPox_exact1, chickPoxSampSize, 0.9)
dbinom(chickPox_exact1, chickPoxSampSize, 0.9)- Find the probability that exactly adults in your sample of will not have had chickenpox.
Hint 1
This is a lot like the previous question — but read carefully.
Hint 2
What is the probability that a randomly selected adult has not had chickenpox? That changes both the count of interest and the probability argument.
Hint 3 (Solved)
The number of adults who have not had chickenpox is , the sample size is , and the probability of not having had chickenpox is 0.10.
dbinom(___, ___, ___)
dbinom(chickPox_exact2, chickPoxSampSize, 0.1)
dbinom(chickPox_exact2, chickPoxSampSize, 0.1)- Find the probability that at most adults in your sample of will have had chickenpox.
Hint 1
Are you interested in exactly some number of successes here?
Hint 2
Use pbinom() instead of dbinom() — it handles “at most” scenarios.
Hint 3 (Solved)
The arguments are the maximum number of successes ( ), the sample size ( ), and the probability of success ( 0.90 ).
pbinom(___, ___, ___)
pbinom(chickPox_atmost, chickPoxSampSize, 0.9)
pbinom(chickPox_atmost, chickPoxSampSize, 0.9)- Find the probability that at least adults in your sample of will have had chickenpox.
Hint 1
We are interested in several possible outcomes here. pbinom() is better-suited to this scenario than dbinom().
Hint 2
pbinom() computes the probability of at most some number of successes, not at least. Draw a picture to help you, and use the “subtract-from-one” approach.
Hint 3 (Solved)
To get “at least ”, subtract the probability of “at most ” from 1. The sample size is and the probability of success is 0.90.
1 - pbinom(___, ___, ___)
1 - pbinom(chickPox_atleast - 1, chickPoxSampSize, 0.9)
1 - pbinom(chickPox_atleast - 1, chickPoxSampSize, 0.9)- Find the probability that more than but less than adults in your sample of will have had chickenpox.
Hint 1
Since multiple outcomes are of interest here, we’ll use pbinom().
Hint 2
Draw a picture to help you. You’ll need to use pbinom() twice — once for the upper boundary and once to subtract out the outcomes below the lower boundary.
Hint 3
The phrase “more than but less than ” means both boundaries are excluded. The sample size is and the probability of success is 0.90.
pbinom(___, ___, ___) - pbinom(___, ___, ___)
Hint 4
The phrase “more than but less than ” means both boundaries are excluded. The sample size is and the probability of success is 0.90.
The number of trials in both scenarios is and the probability of success is 0.90 for each as well. Use these as the second and third arguments for both instances of pbinom() below.
pbinom(___, ___, ___) - pbinom(___, ___, ___)
Hint 5
The phrase “more than but less than ” means both boundaries are excluded. The sample size is and the probability of success is 0.90.
The number of trials in both scenarios is and the probability of success is 0.90 for each as well. Use these as the second and third arguments for both instances of pbinom() below.
For the first call to pbinom() the maximum number of successful outcomes you are interested in is . Use this as the first argument to the first call to pbinom().
pbinom(___, ___, ___) - pbinom(___, ___, ___)
Hint 6 (Solved)
Pass , , and 0.90 as the arguments to the first call to pbinom(). Similarly, pass , , and 0.90 as the arguments to the second call to pbinom().
pbinom(___, ___, ___) - pbinom(___, ___, ___)
pbinom(chickPox_between_hi - 1, chickPoxSampSize, 0.9) - pbinom(chickPox_between_lo, chickPoxSampSize, 0.9)
pbinom(chickPox_between_hi - 1, chickPoxSampSize, 0.9) - pbinom(chickPox_between_lo, chickPoxSampSize, 0.9)Practice Problem 2: Sophia took the Graduate Record Examination (GRE) and scored 160 on the Verbal Reasoning section and 157 on the Quantitative Reasoning section. The mean score on the Verbal Reasoning section for all test takers was 151 with a standard deviation of 7, and the mean score for the Quantitative Reasoning section was 153 with a standard deviation of 7.67. Suppose we can assume that both score distributions are nearly normal.
- Use the code block below to compute Sophia’s \(z\)-score on the Quantitative Reasoning exam.
Hint 1
The \(z\)-score formula is \((x - \mu) / \sigma\).
Hint 2 (Solved)
The \(z\)-score formula is \((x - \mu) / \sigma\).
Sophia scored 157 on the Quantitative Reasoning exam, the mean is 153, and the standard deviation is 7.67.
(___ - ___) / ___
(157 - 153) / 7.67
(157 - 153) / 7.67- Use the code block below to compute Sophia’s \(z\)-score on the Verbal Reasoning exam.
Hint 1
Use the same approach as above, but with the Verbal Reasoning values: Sophia scored 160, the mean is 151, and the standard deviation is 7.
(___ - ___) / ___
(160 - 151) / 7
(160 - 151) / 7
Check Your Understanding: Comparing \(z\)-Scores
What do these \(z\)-scores tell you?
- Find the proportion of test takers that Sophia scored higher than on the Quantitative Reasoning exam (that is, find her percentile).
Hint 1
What distribution are we using — binomial or normal?
Hint 2
Since scores are approximately normally distributed, use pnorm() or qnorm(). Which is appropriate here, and why?
Hint 3
We want the proportion of test takers below Sophia’s score of 157 — that’s the area to the left, which is exactly what pnorm() gives us. The mean is 153 and the standard deviation is 7.67.
pnorm(___, ___, ___)
Hint 4 (Solved)
We want the proportion of test takers below Sophia’s score of 157 — that’s the area to the left, which is exactly what pnorm() gives us. The mean is 153 and the standard deviation is 7.67.
Fill the first argument of pnorm() with 157, the second with 153, and the third with 7.67.
pnorm(___, ___, ___)
pnorm(157, 153, 7.67)
pnorm(157, 153, 7.67)- Find the proportion of test takers doing better than Sophia on the Verbal Reasoning exam.
Hint 1
Draw a picture and use it to guide you. We want the area to the right of Sophia’s score — you’ll need the “subtract-from-one” approach.
Hint 2
Sophia’s Verbal Reasoning score is 160, the mean is 151, and the standard deviation is 7.
1 - pnorm(___, ___, ___)
Hint 3 (Solved)
Sophia’s Verbal Reasoning score is 160, the mean is 151, and the standard deviation is 7.
Use 160 as the first argument, 151 as the second, and 7 as the third in the call to pnorm() below.
1 - pnorm(___, ___, ___)
1 - pnorm(160, 151, 7)
1 - pnorm(160, 151, 7)Submit
If you are part of a course with an instructor who is grading your work on these activities, please copy and submit both of the hashes below using the method your instructor has requested.
Question Hash
The hash below encodes your responses to the multiple choice and checkbox questions in this activity.
Exercise Hash
Click the button below to generate your exercise submission code. This hash encodes your work on the graded code exercises in this activity.
You must have attempted the graded exercises before clicking — clicking generates a snapshot of your current results. If you have completed the activity over multiple sessions, please go back through and hit the Run Code button on each graded exercise before generating the hash below, to ensure your most recent results are recorded.
Summary
Main Takeaways
- A normal distribution is bell-shaped and fully described by its mean \(\mu\) and standard deviation \(\sigma\), written \(N(\mu, \sigma)\). Larger \(\sigma\) produces a shorter, wider curve; smaller \(\sigma\) produces a taller, narrower curve.
- The Empirical Rule for data following \(N(\mu, \sigma)\) states that approximately 67% of observations fall within one standard deviation of the mean, 95% within two, and 99.7% within three.
- For a continuous distribution, \(\mathbb{P}[X = k] = 0\), so there is no distinction between strict and non-strict inequalities. For example, \(\mathbb{P}[X \leq k] = \mathbb{P}[X < k]\).
- A \(z\)-score measures how many standard deviations an observation falls from the mean: \(z = (x - \mu)/\sigma\). Converting raw observed values to \(z\)-scores allow comparison across different normal distributions on a common scale.
pnorm(q, mean, sd)returns the area to the left of \(q\) — that is, \(\mathbb{P}[X \leq q]\). For right-tail and two-tail probabilities, draw a picture to inform how to use and combine calls topnorm()in order to find desired probabilities.qnorm(p, mean, sd)returns the value \(x^*\) such that \(\mathbb{P}[X \leq x^*] = p\). This is called the \(p^{th}\) percentile. Remember that \(p\) is the area to the left of the desired cutoff.- When a scenario involves repeated independent yes/no trials with constant probability, use the binomial distribution (
dbinom,pbinom). When data are approximately normally distributed, use the normal distribution (pnorm,qnorm).
Looking Ahead
The next activity is a discrete probability and simulation lab exploring the hot hand phenomenon in basketball — a fun application of the ideas we’ve encountered in our short study of probability. You’ll simulate data, compare distributions, and think carefully about what “random” actually looks like in practice.