Simple Linear Regression: Construction, Assessment, and Interpretation
February 8, 2026
What is Simple Linear Regression?
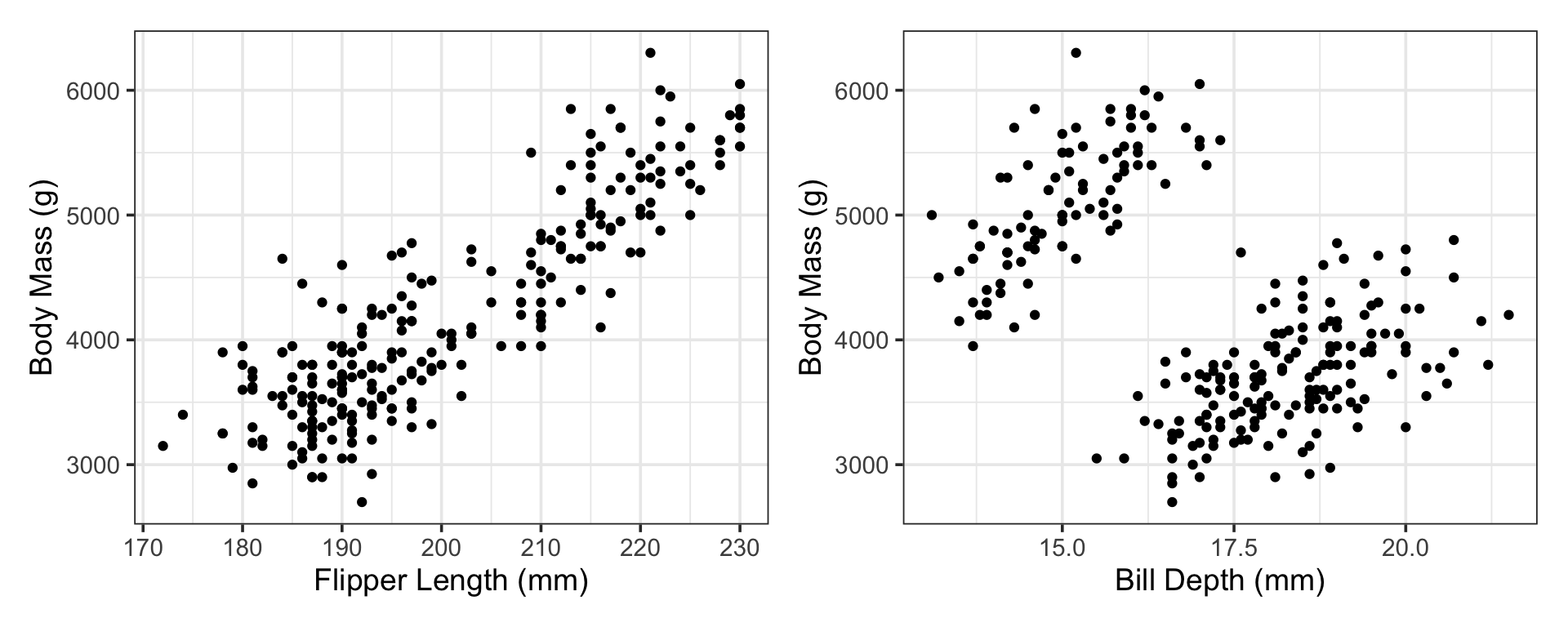
Question 1 (Inferential): What, if anything, is the relationship between penguin flipper length and body mass?
Question 1 (Predictive): Can we use penguin flipper length to predict body mass?
Question 2 (Inferential): What, if anything, is the relationship between penguin bill depth and body mass?
Question 2 (Predictive): Can we use penguin bill depth to predict body mass?
What is Simple Linear Regression?
Each of these questions can be answered by the construction and analysis of a model.
Simple linear regression predicts a response as a linear function of a single predictor variable.
\[\mathbb{E}\left[\text{body mass}\right] = \beta_0 + \beta_1\cdot \left(\text{flipper length}\right)\\ \textbf{or}\\ \mathbb{E}\left[\text{body mass}\right] = \beta_0 + \beta_1\cdot \left(\text{bill depth}\right)\]
What is Simple Linear Regression?
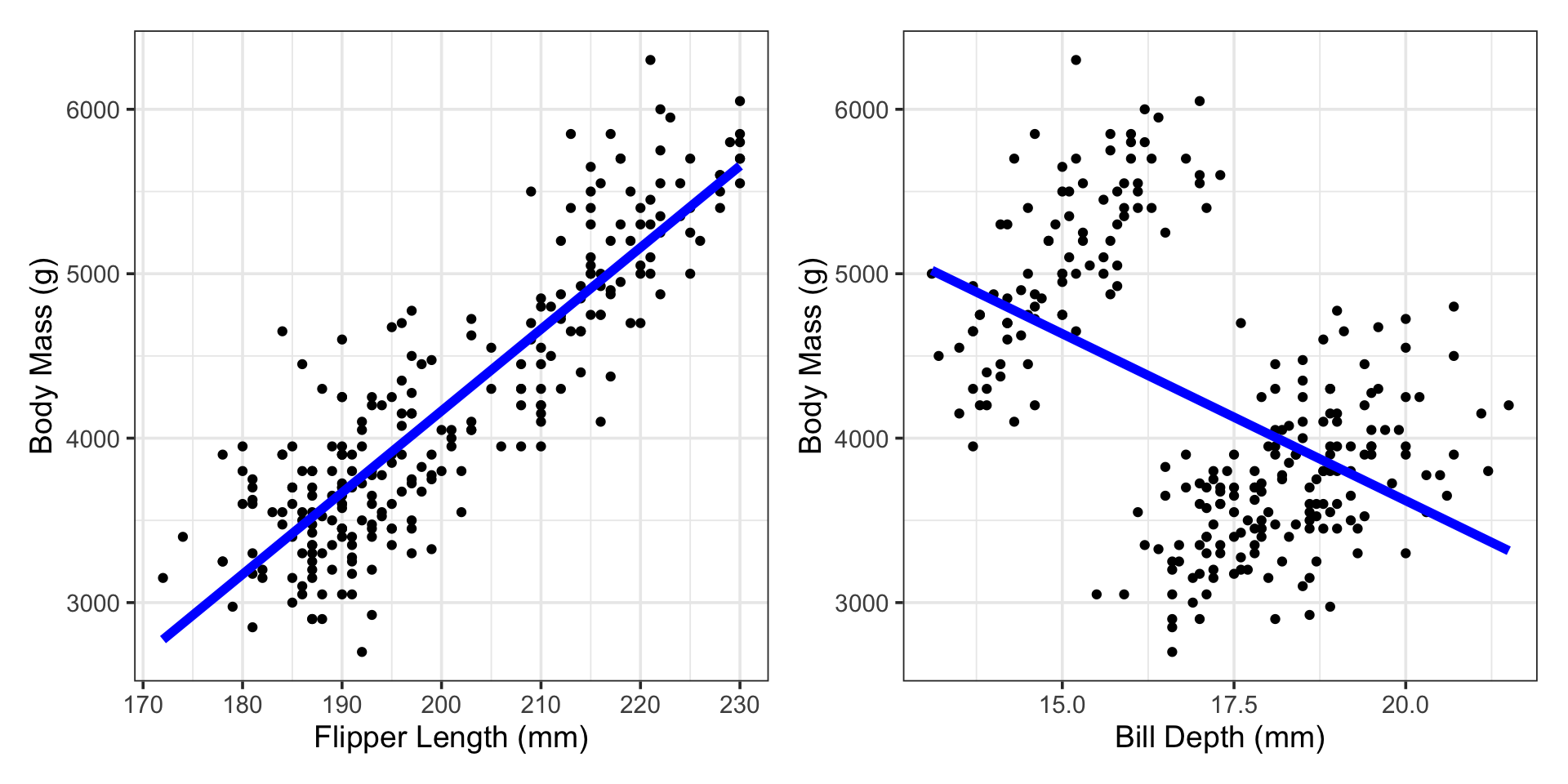
\[\mathbb{E}\left[\text{body mass}\right] = -5769 + 49.7\left(\text{flipper length}\right)\\ \textbf{or}\\ \mathbb{E}\left[\text{body mass}\right] = 7697 - 203\left(\text{bill depth}\right)\]
What Are We Assuming?
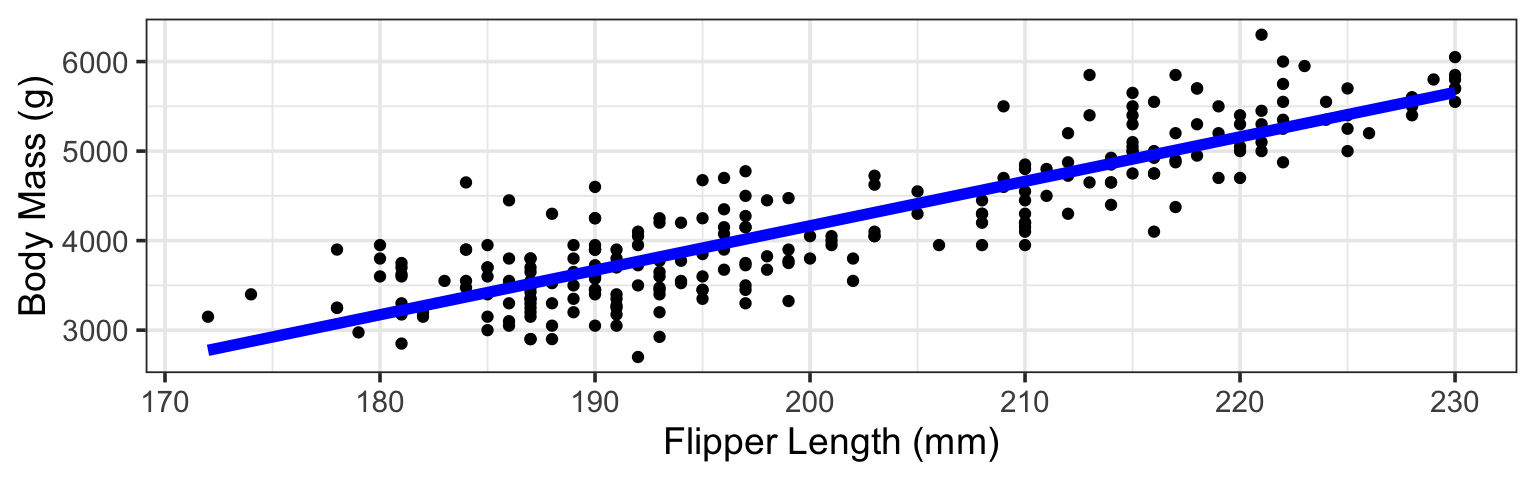
\[\mathbb{E}\left[\text{body mass}\right] = \beta_0 + \beta_1\cdot\left(\text{flipper length}\right)\]
Pre-Modeling Assumptions: The conditional mean of penguin body mass is approximately a linear function of flipper length, with other factors treated as unmodeled sources of variability.
Post-Modeling Assumptions: The following assumptions are made about model errors (residuals), to ensure that using and interpreting the model is appropriate.
- Residuals are independent across observations.
- Residuals have mean zero, conditional on the predictor.
- The variance of residuals is constant across values of the predictor (homoscedasticity).
- Residuals are approximately normally distributed (primarily to support inference).
Residual Analysis
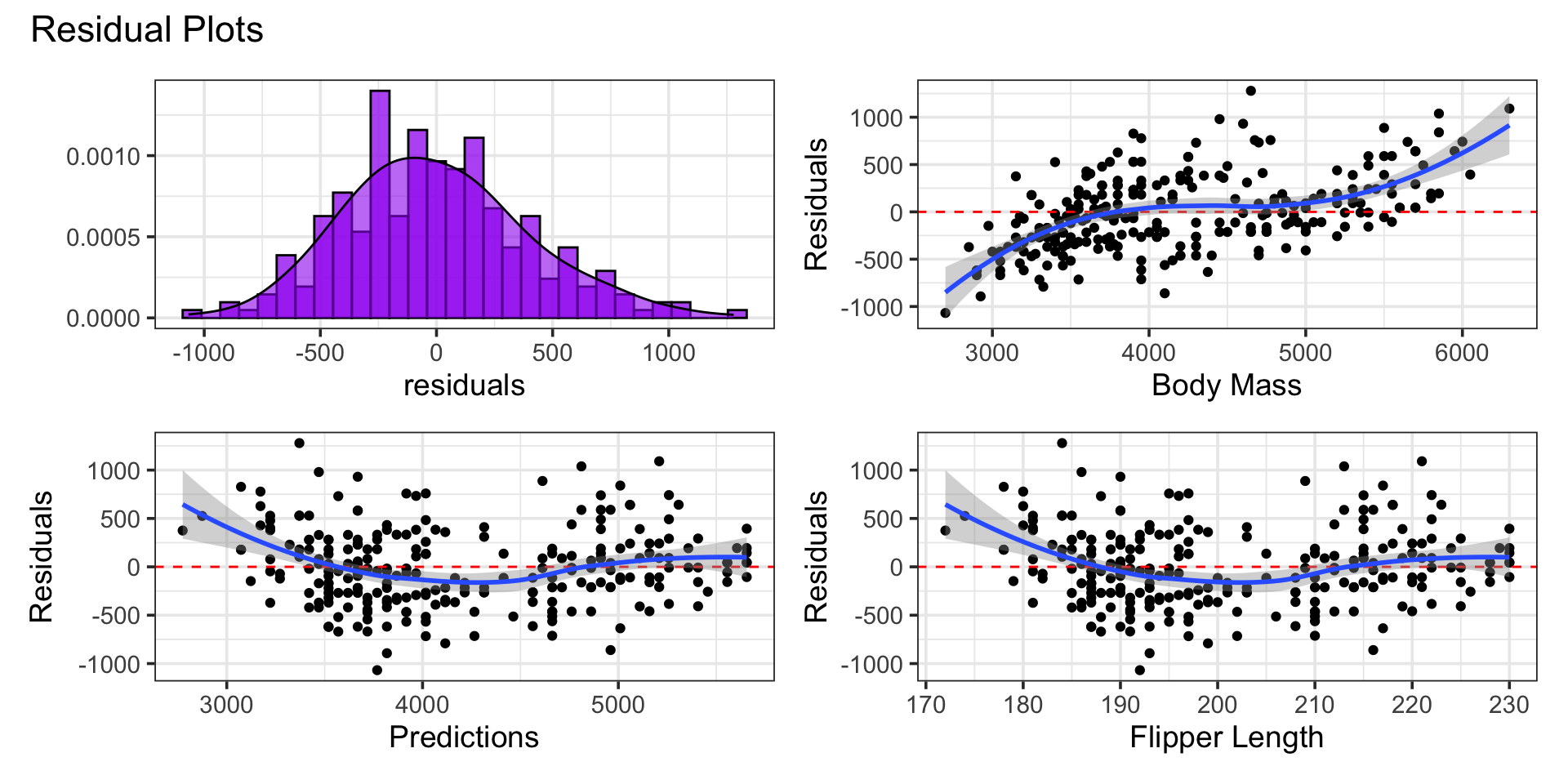
The residuals look approximately normal – with some right skew. There does seem to be an association between the residuals and response, predictions, and flipper length though.
Patterns in residual plots indicate that we could make a better model.
Using the Model to Make Predictions
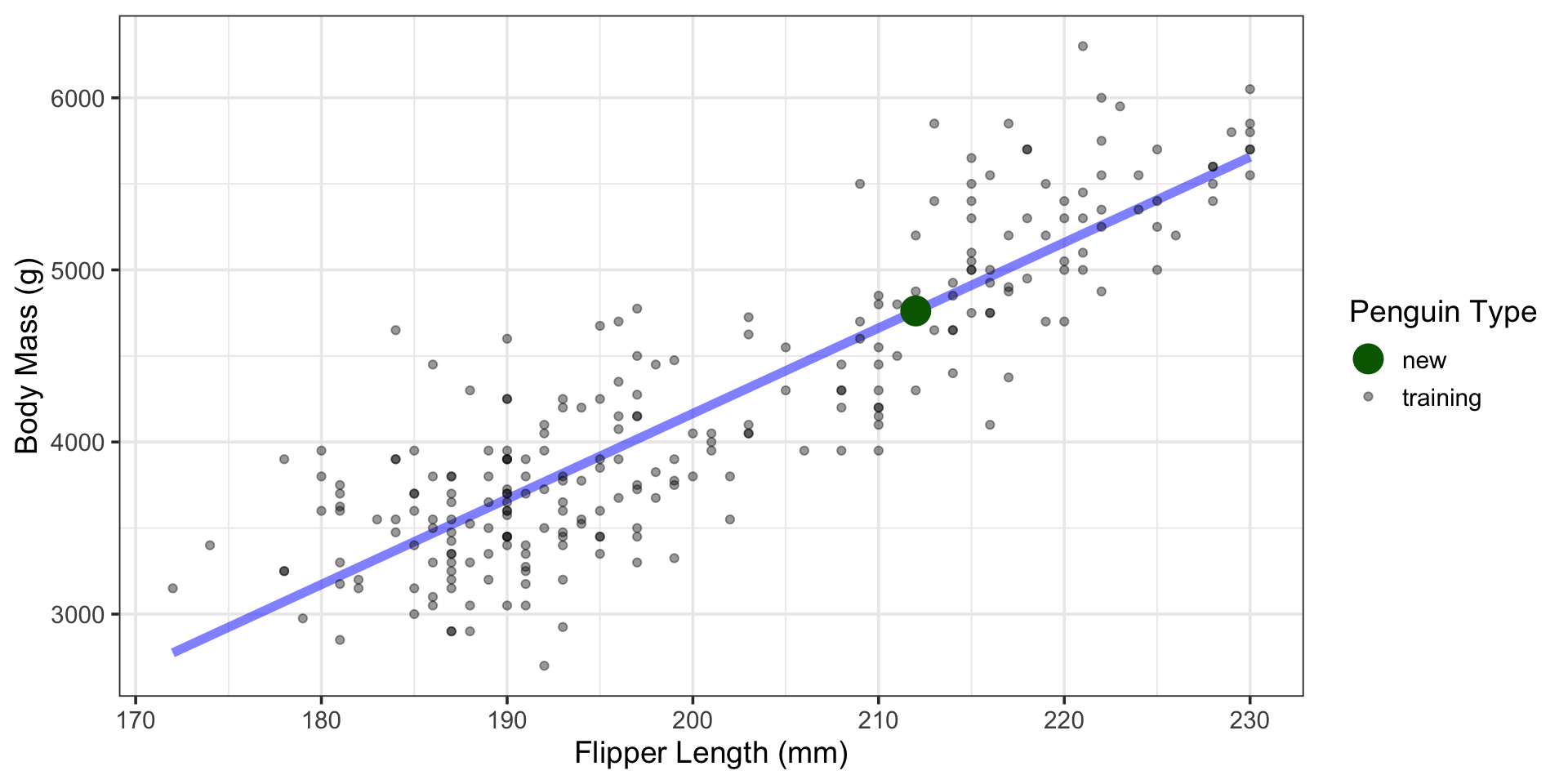
Using the Model to Make Predictions
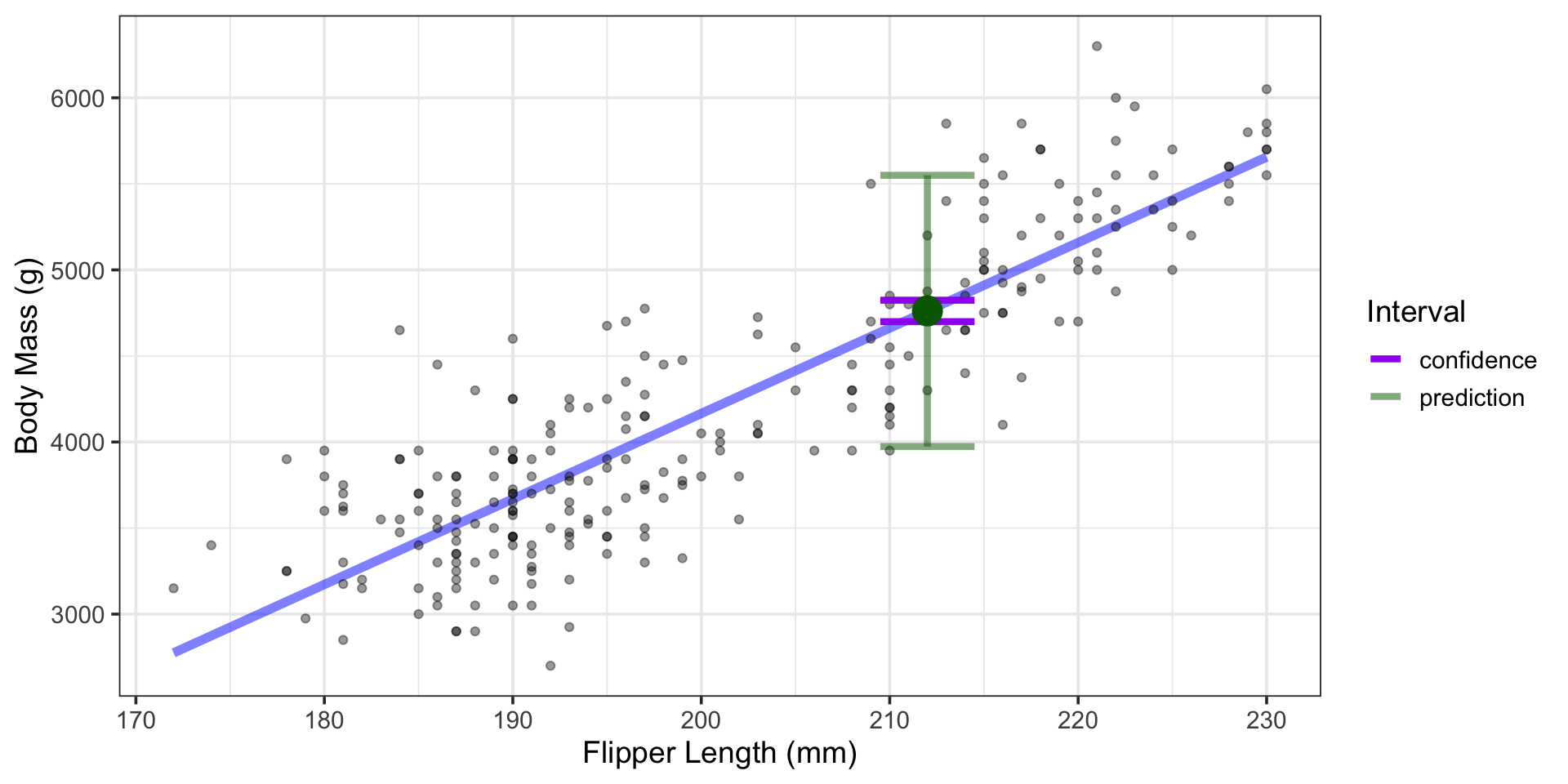
What is the body mass of a penguin whose flipper length is 212mm?
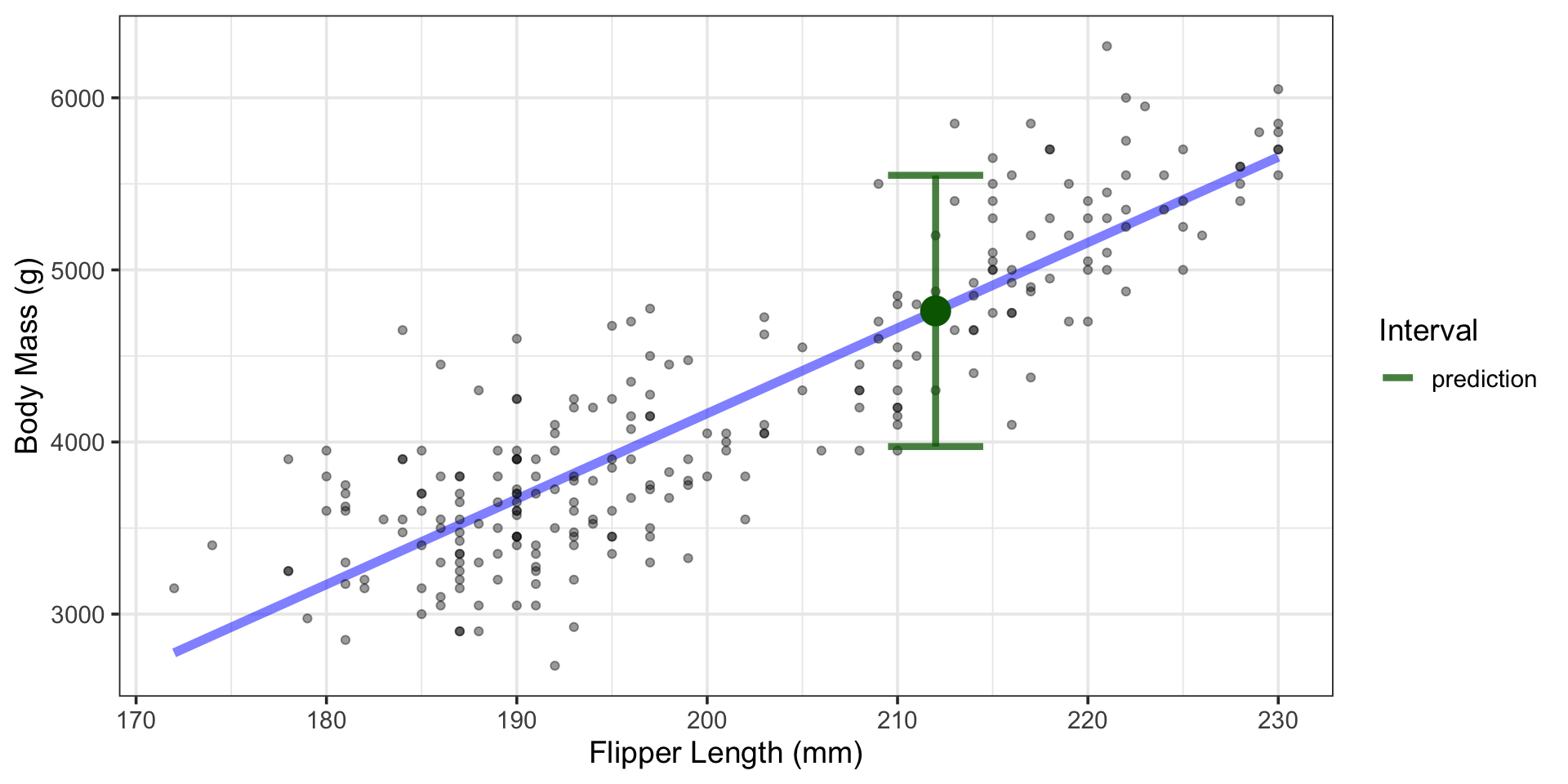
Using the Model to Make Predictions
What is the average body mass of all penguins whose flipper length is 212mm?
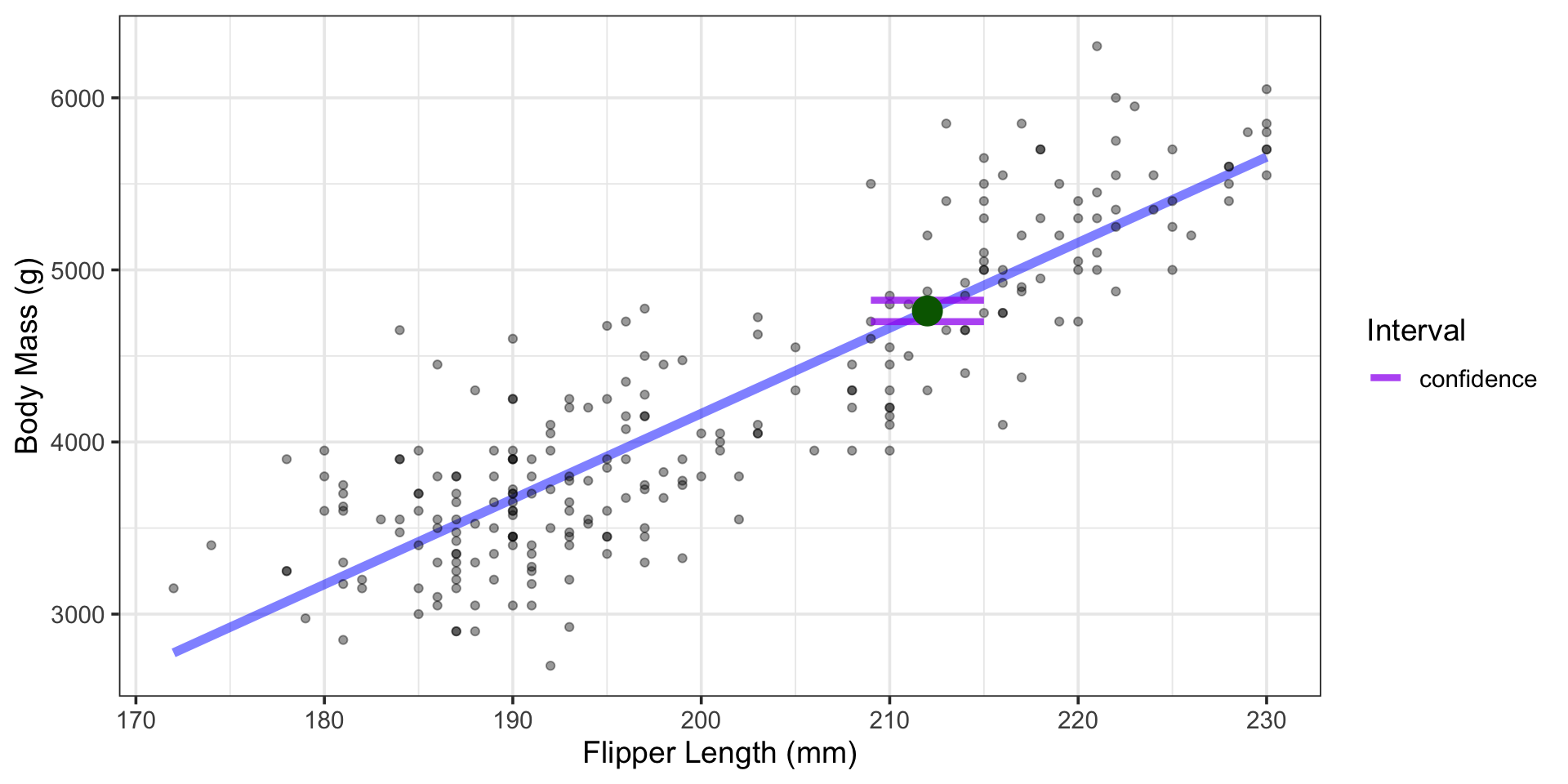
Using the Model to Make Predictions
What is the body mass of a penguin whose flipper length is 212mm?
- Somewhere between 3973.6g and 5549.6g, with 95% confidence.
What is the average body mass of all penguins whose flipper length is 212mm?
- Somewhere between 4699.4g and 4823.9g, with 95% confidence.