Overview of Statistical Learning (and Competition Overview)
January 6, 2026
Statistical Learning in Pictures
Statistical Learning in Pictures
Goal: Build a model \(\displaystyle{\mathbb{E}\left[y\right] = \beta_0 + \beta_1 x}\) to predict \(y\), given \(x\).
Generalized Goal: Build a model \(\displaystyle{\mathbb{E}\left[y\right] = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k}\) to predict \(y\) given features \(x_1, \cdots, x_k\).
- \(\beta_i\)’s are parameters, learned from training data.
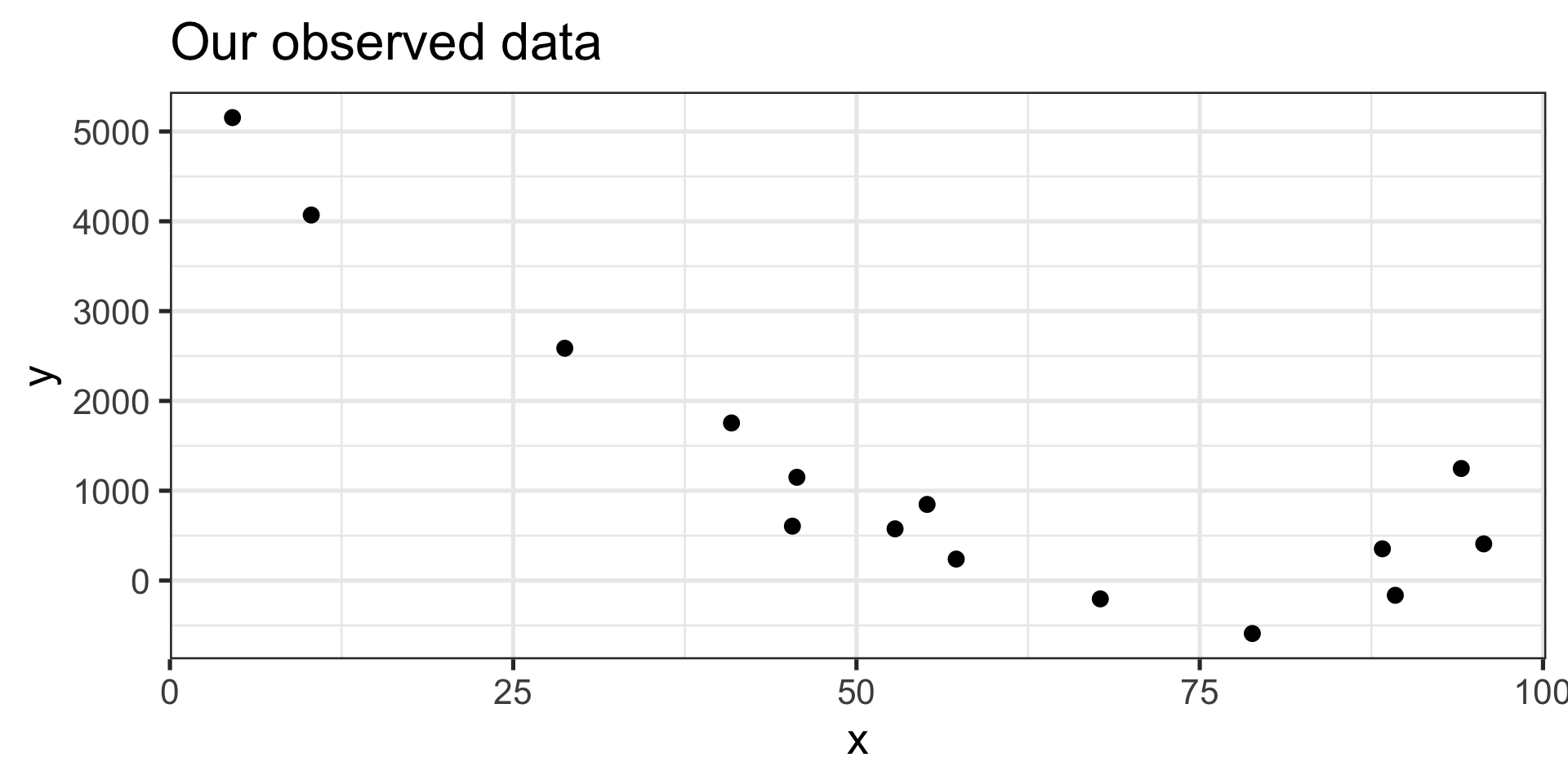
Statistical Learning in Pictures
- This model doesn’t capture the general trend between our observed \(x\) and \(y\) pairs.
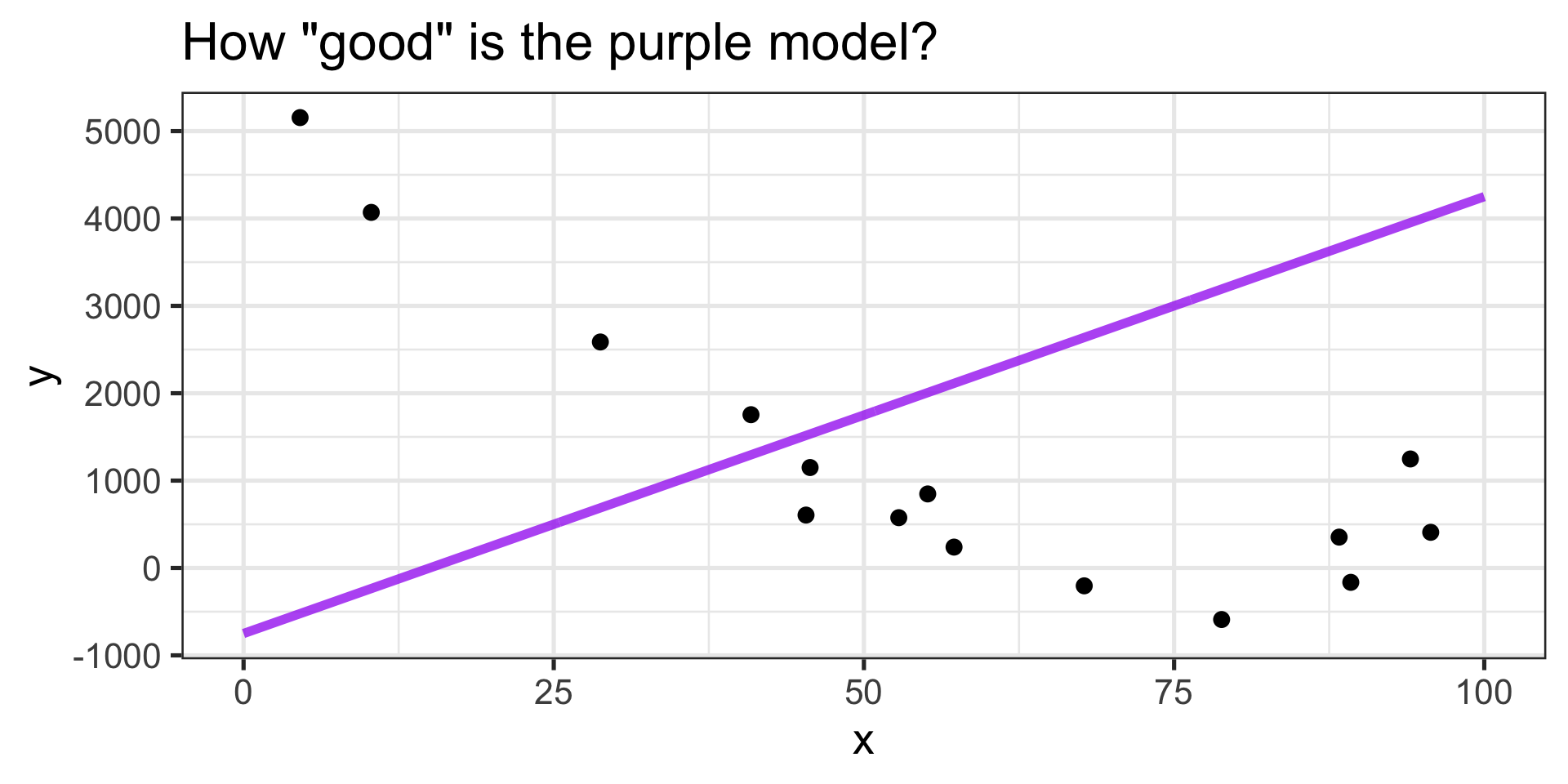
Statistical Learning in Pictures
- Better job capturing the general trend (sort of).
- Larger \(x\) values are associated with smaller \(y\) values.
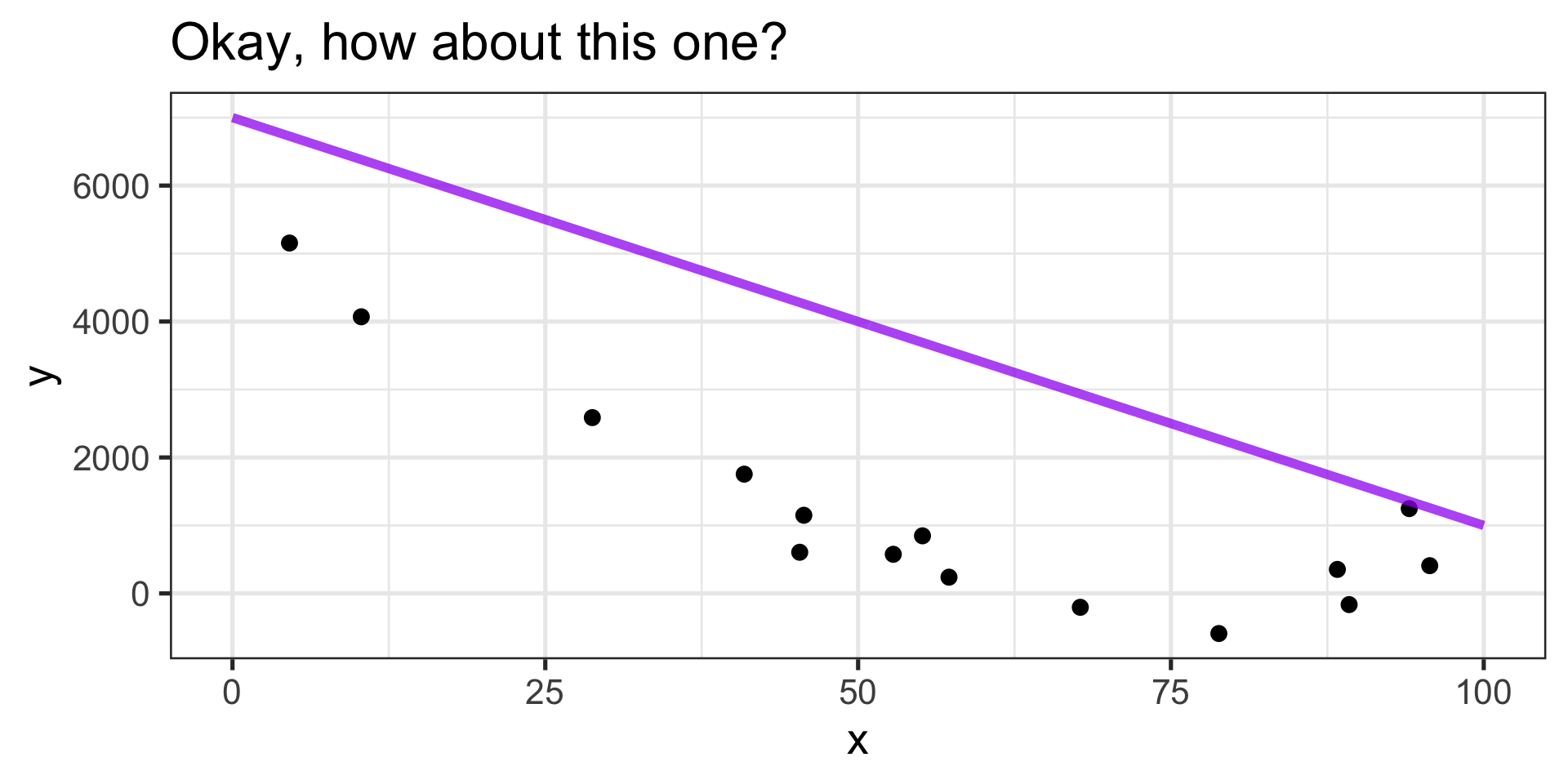
Statistical Learning in Pictures
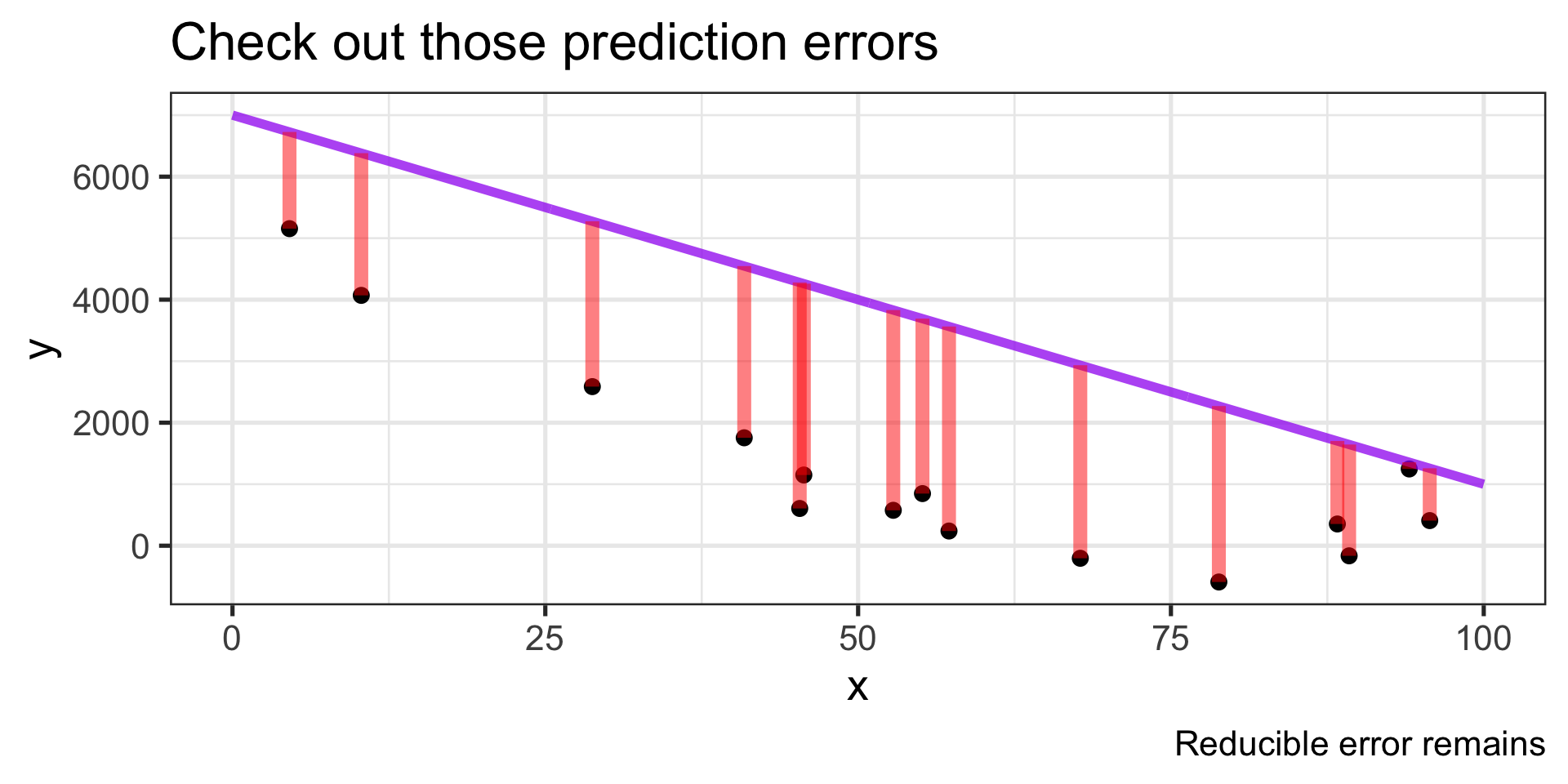
Statistical Learning in Pictures
Always predicting too high!
- We should overpredict sometimes and underpredict others. The average error should be \(0\).
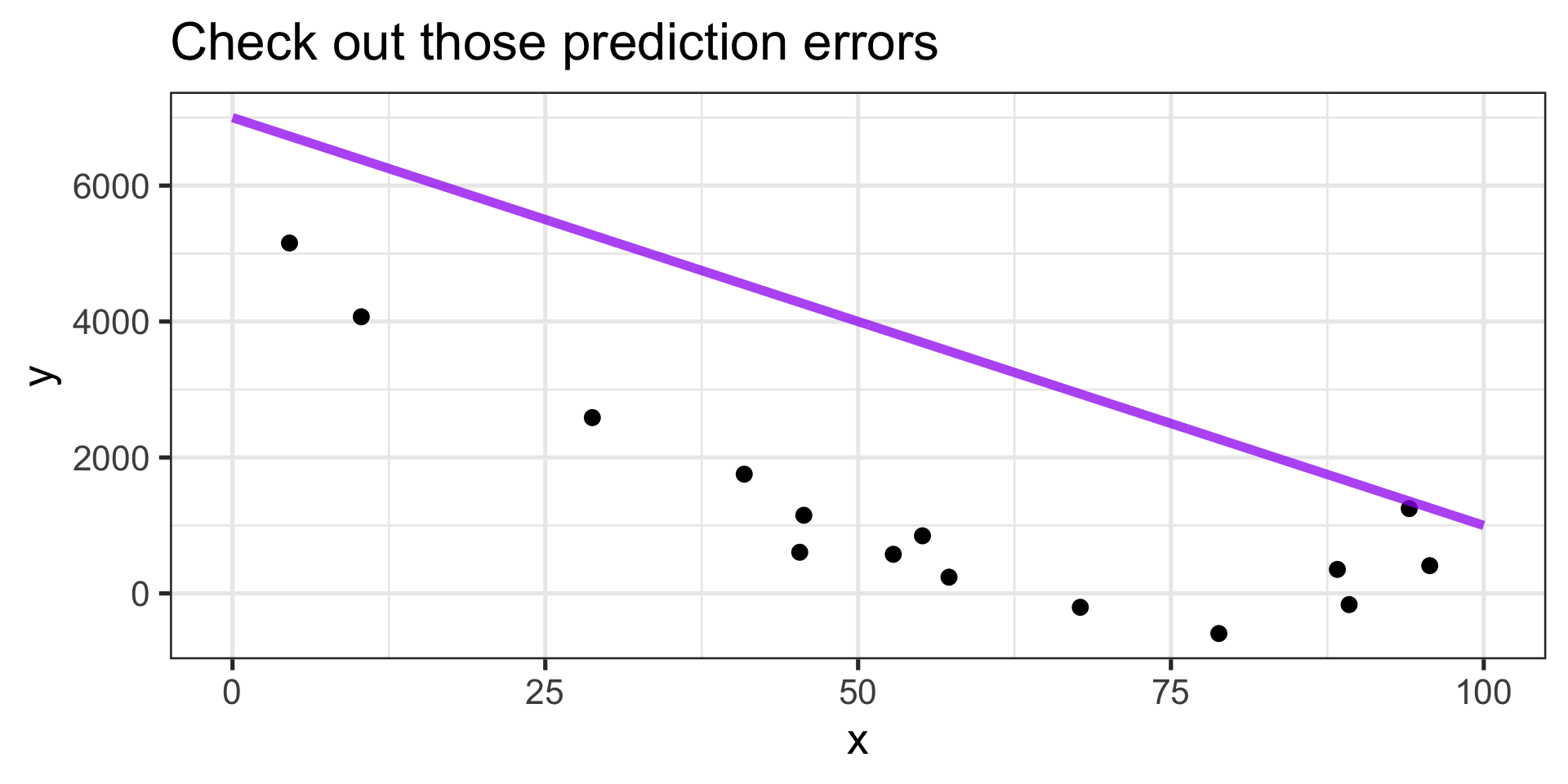
Statistical Learning in Pictures
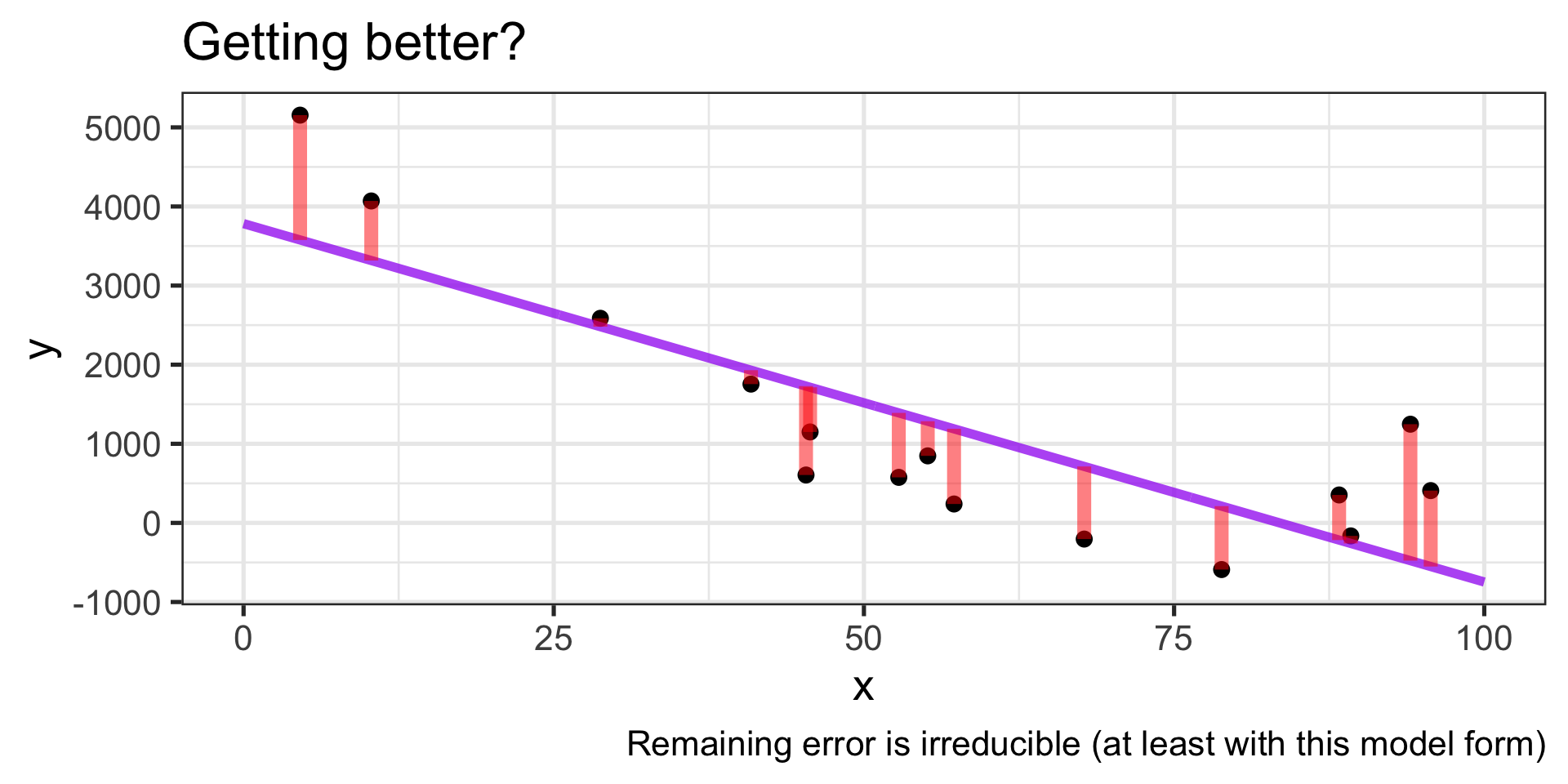
Statistical Learning in Pictures
Statistical Learning in Pictures
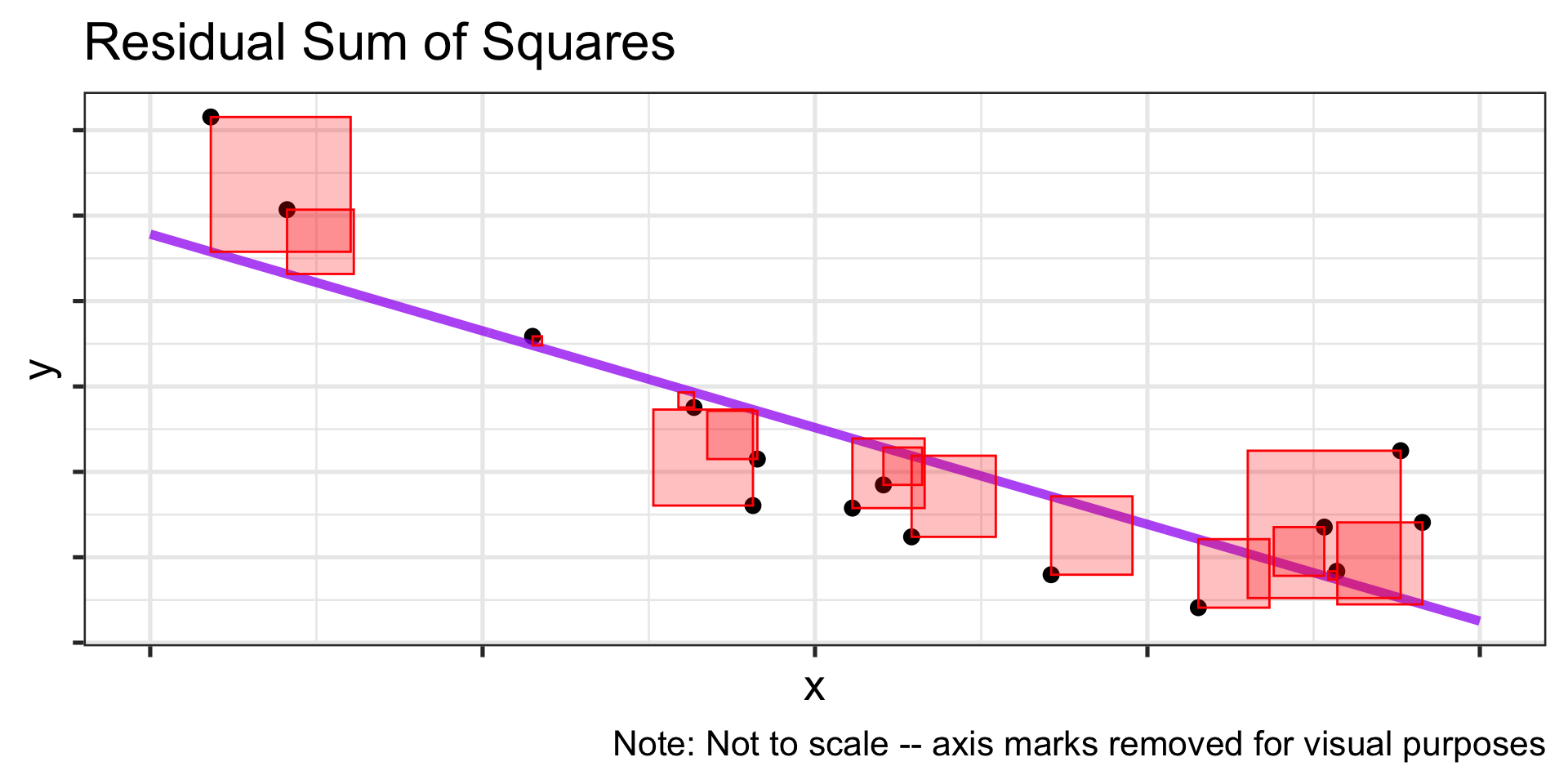
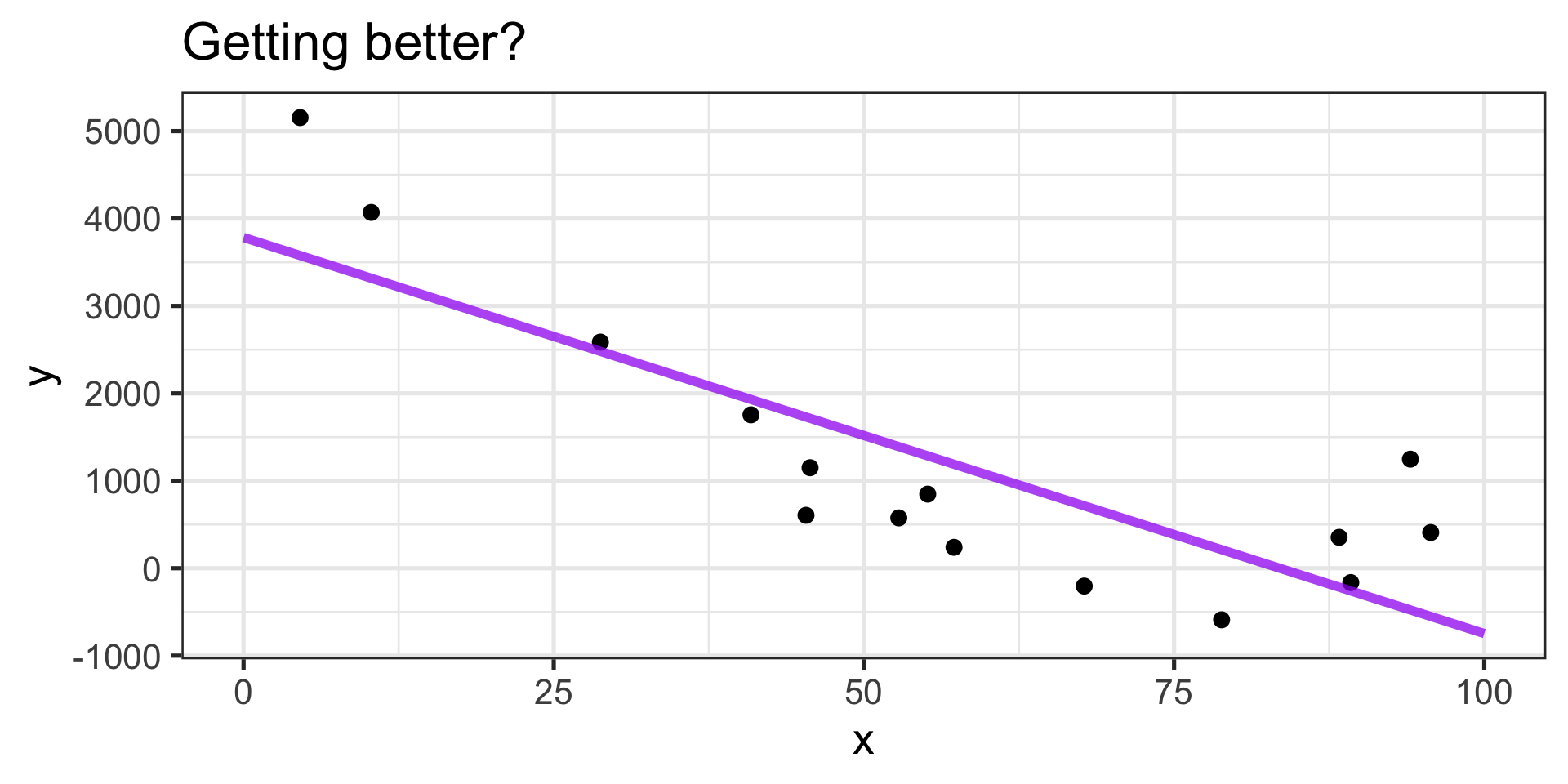
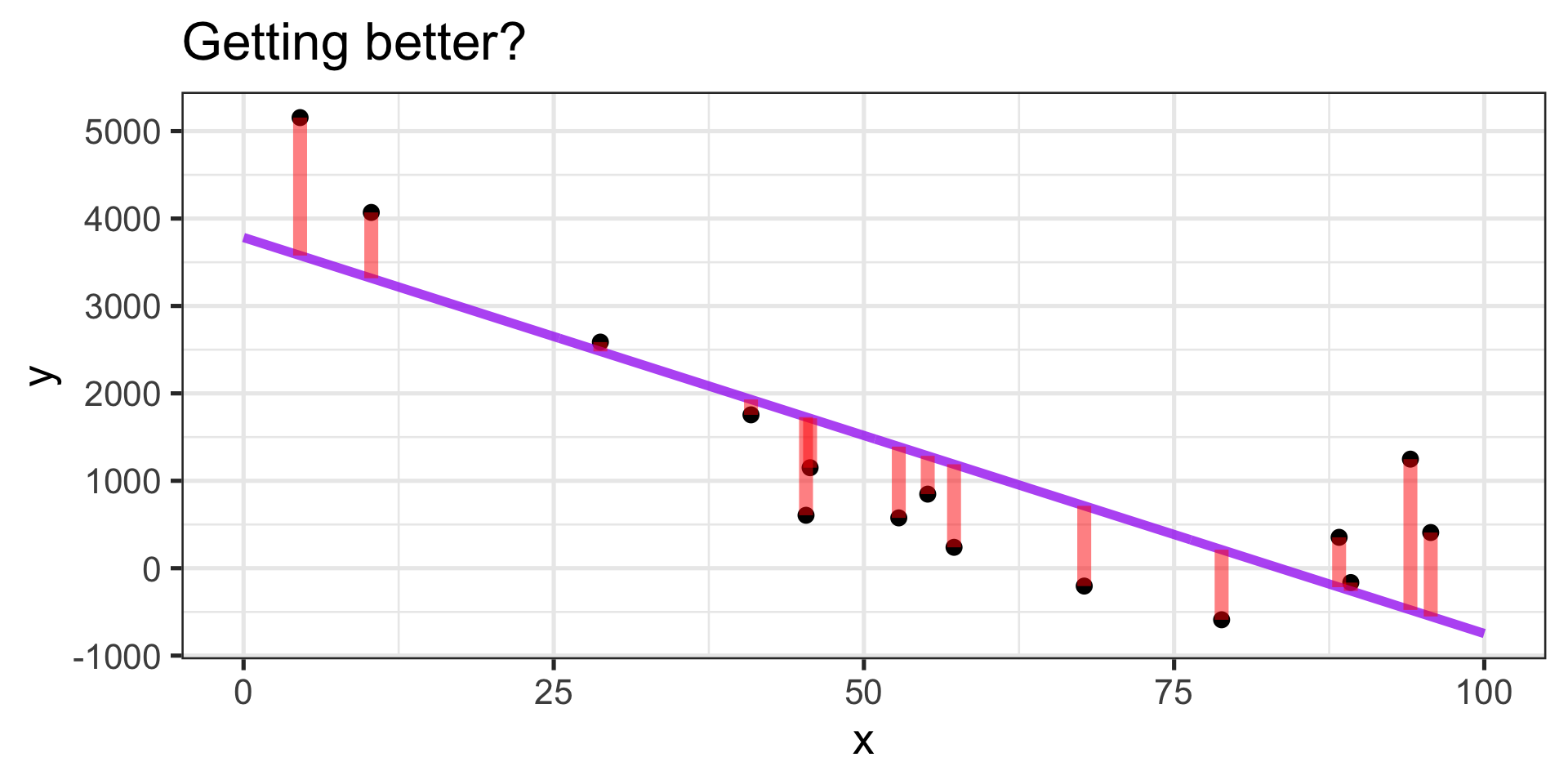
Capturing the general trend?
- …mostly
Balanced errors?
- ✓
How it works
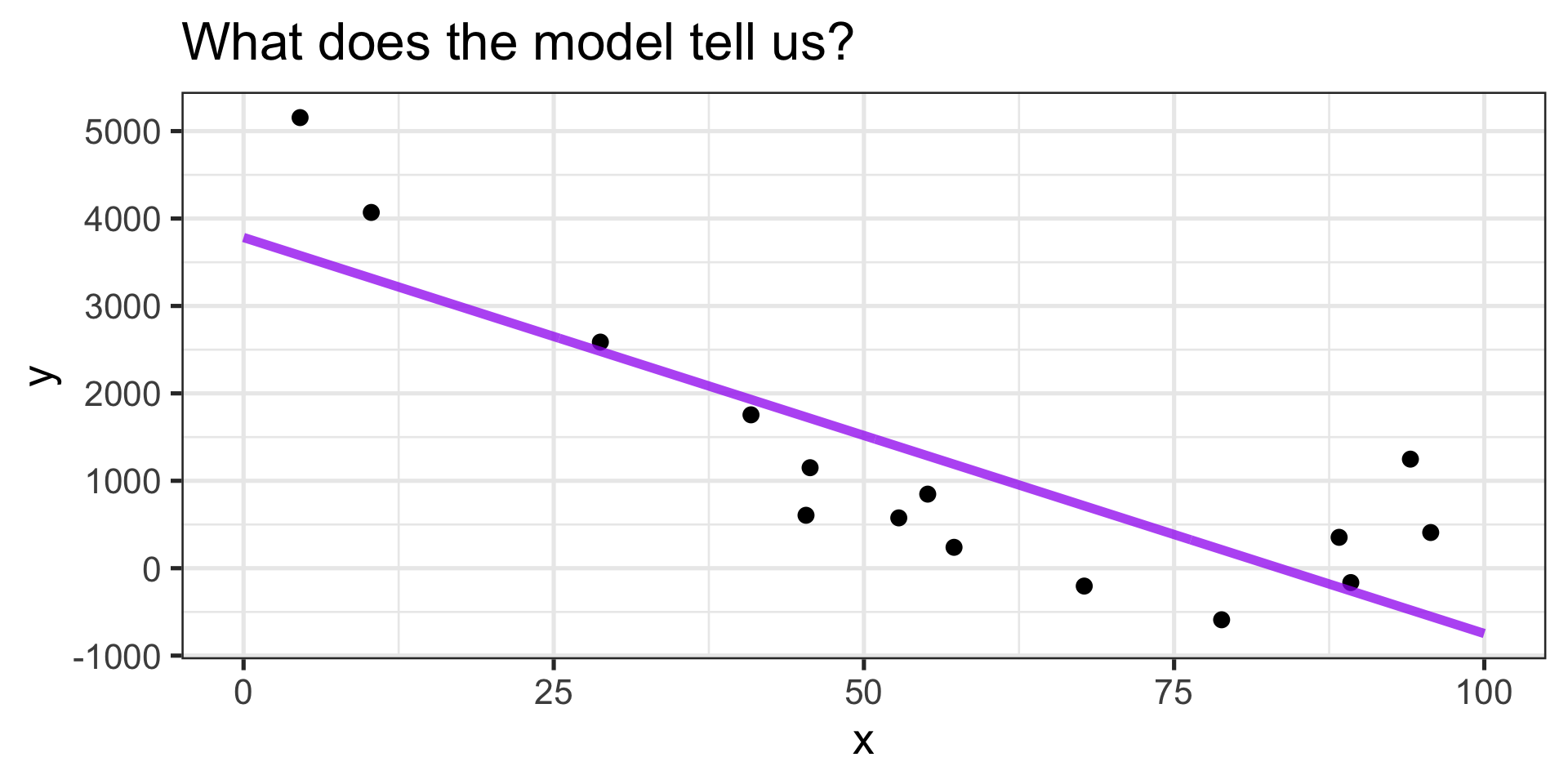
Interpreting the Model
\(\displaystyle{\mathbb{E}\left[y\right] = 3783.21 - 45.3\cdot x}\)
- The expected value of \(y\) when \(x = 0\) is \(3783.21\).
- As \(x\) increases, we expect \(y\) to decrease (on average).
- Given a unit increase in \(x\), we expect \(y\) to decrease by about \(45.3\) units.
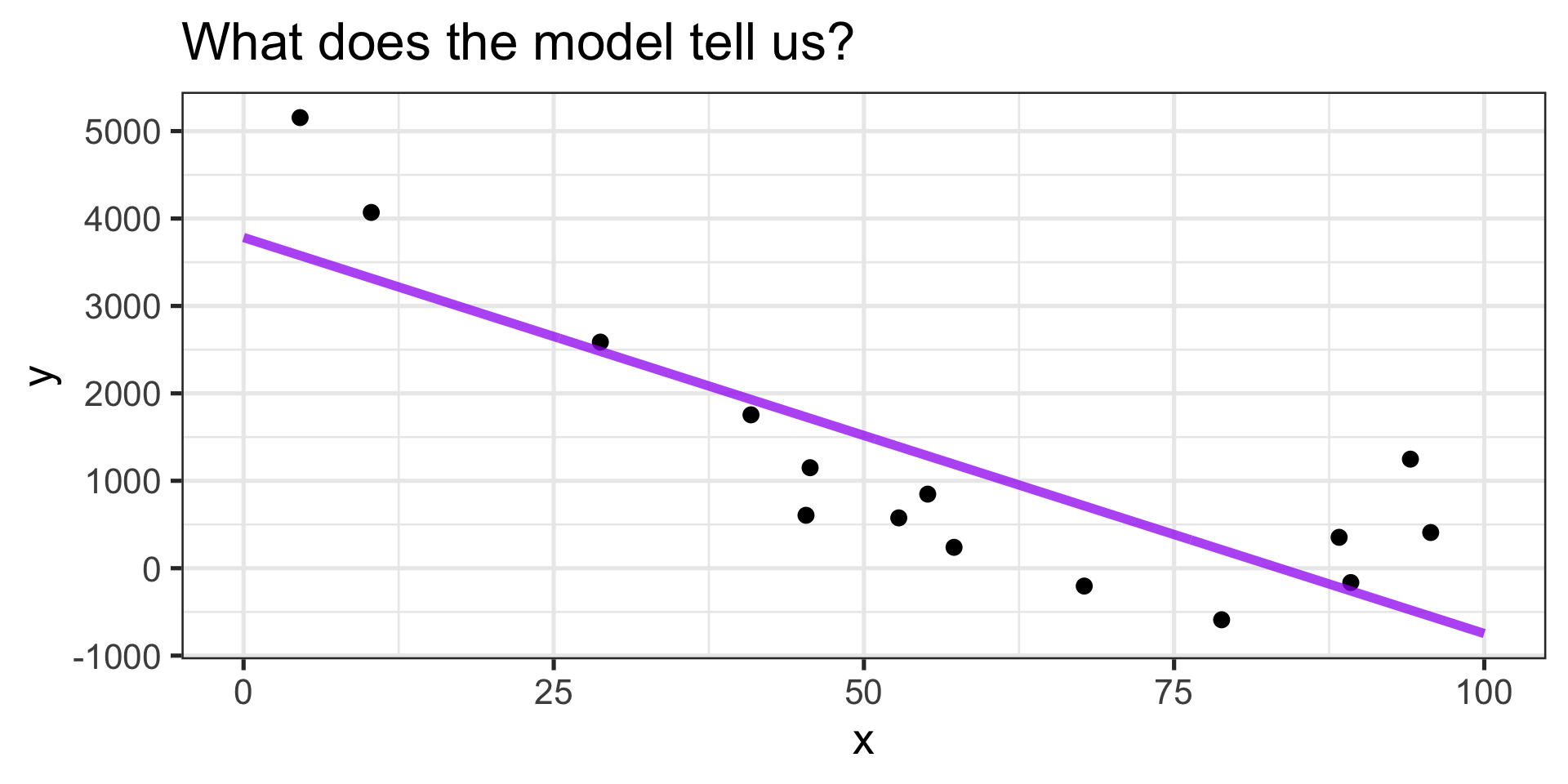
Interpreting the Model
\(\displaystyle{\mathbb{E}\left[y\right] = 3783.21 - 45.3\cdot x}\)
- The expected value of \(y\) when \(x = 0\) is \(3783.21\).
- As \(x\) increases, we expect \(y\) to decrease (on average).
- Given a unit increase in \(x\), we expect \(y\) to decrease by about \(45.3\) units.
Approach to Model Interpretation: In general, we’ll interpret the intercept (when appropriate) and the expected effect of a unit change in each predictor on the response
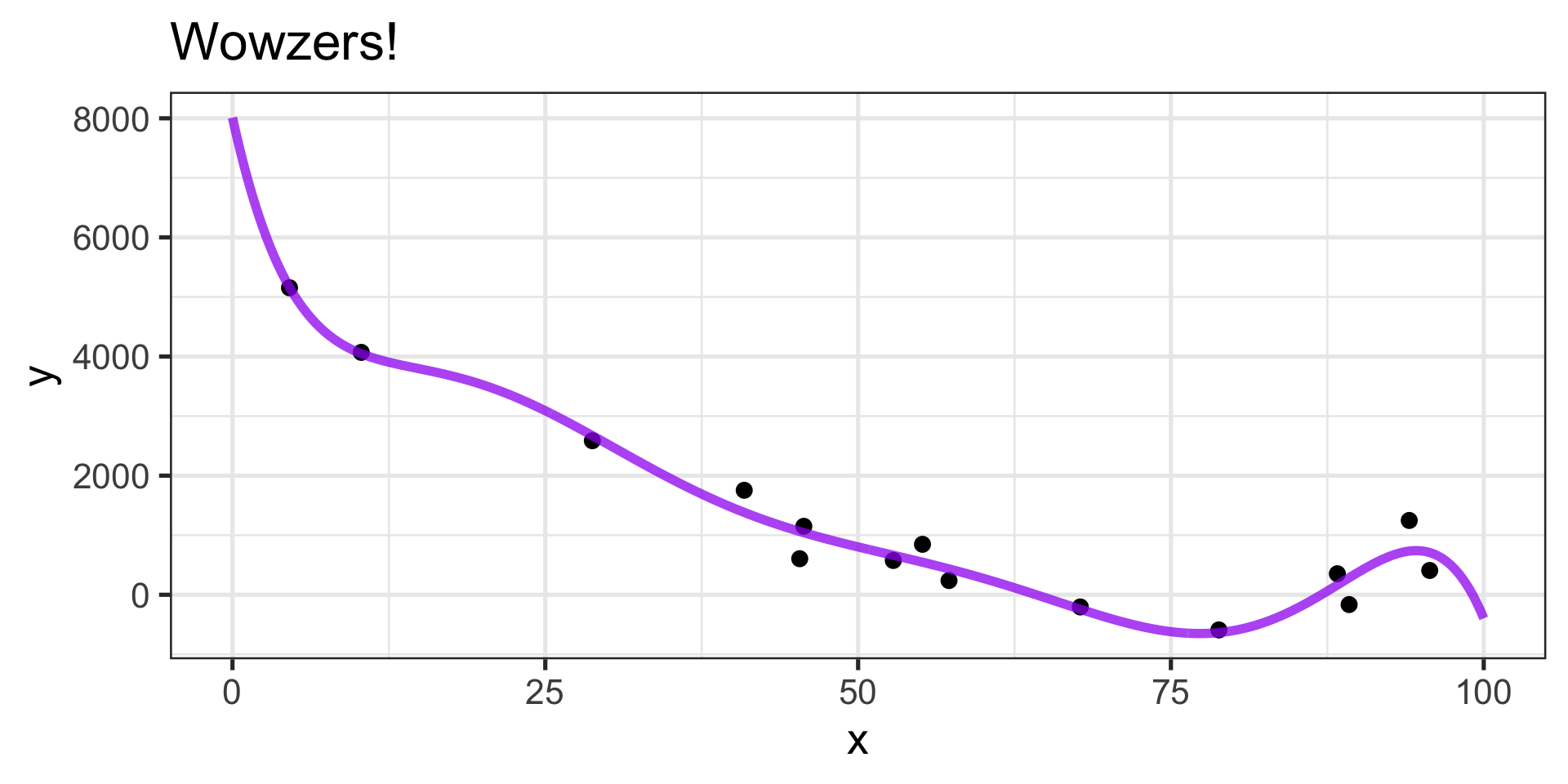
Can we find a better model?
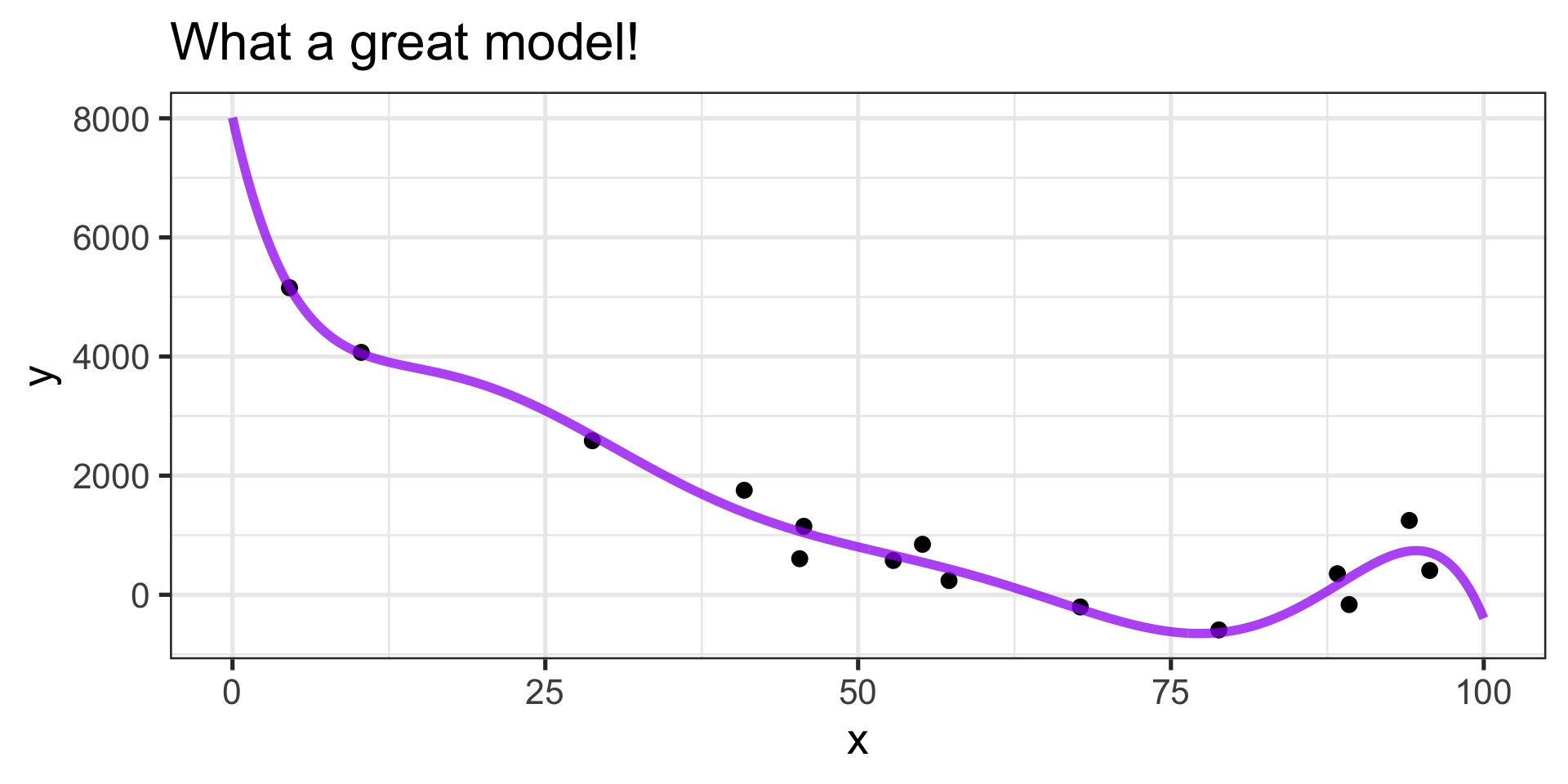
Can we interpret this model?
- The equation is \(\mathbb{E}\left[y\right] \approx 1202 - 4911x +3156x^2 + 784x^3 +\\ 409x^4 -215x^5 -7x^6 -516x^7\)
- No thanks…
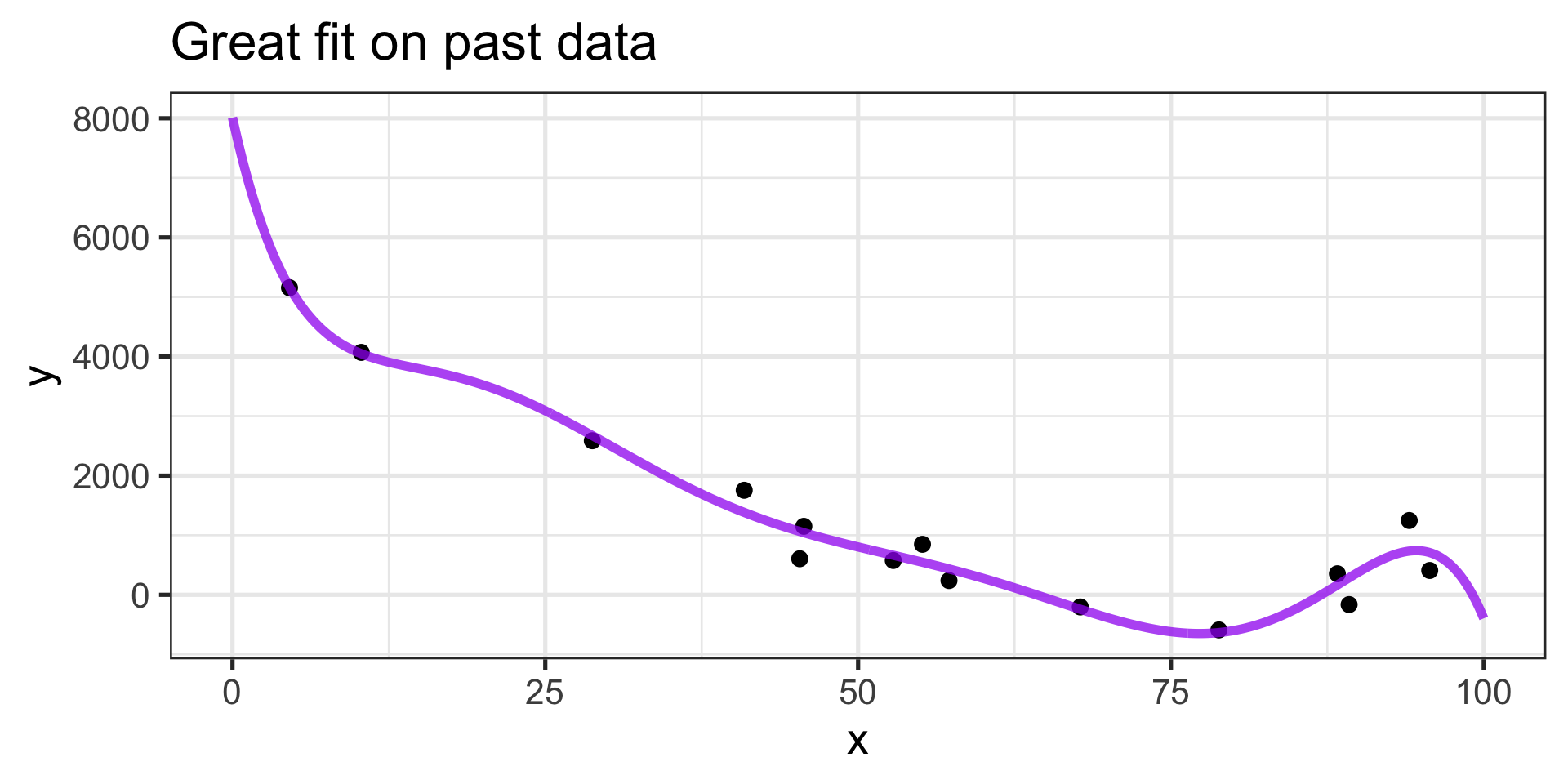
Do we expect this model to generalize well?
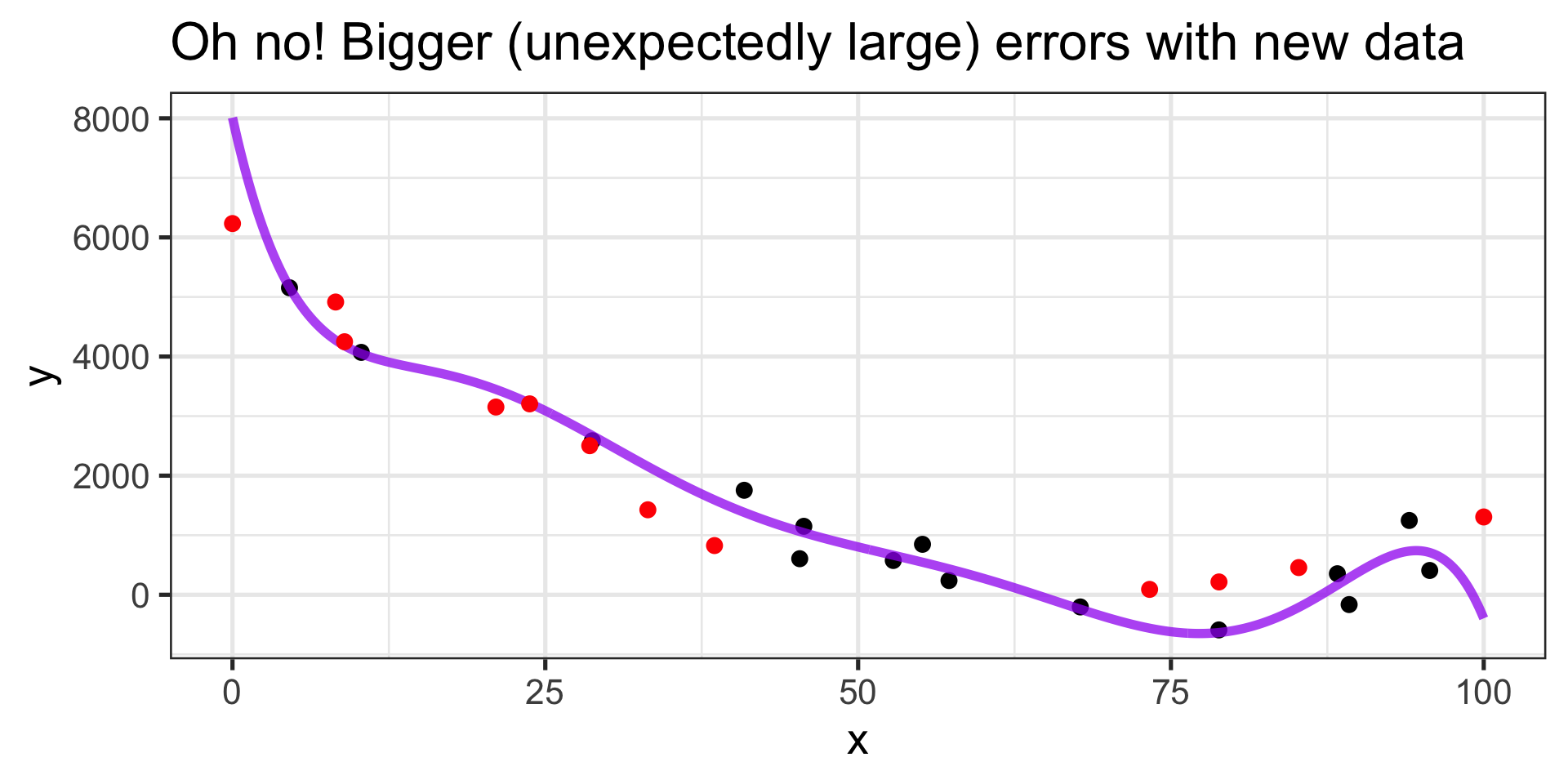
Do we expect this model to generalize well?
- Especially near \(x = 0\) and \(x = 100\)
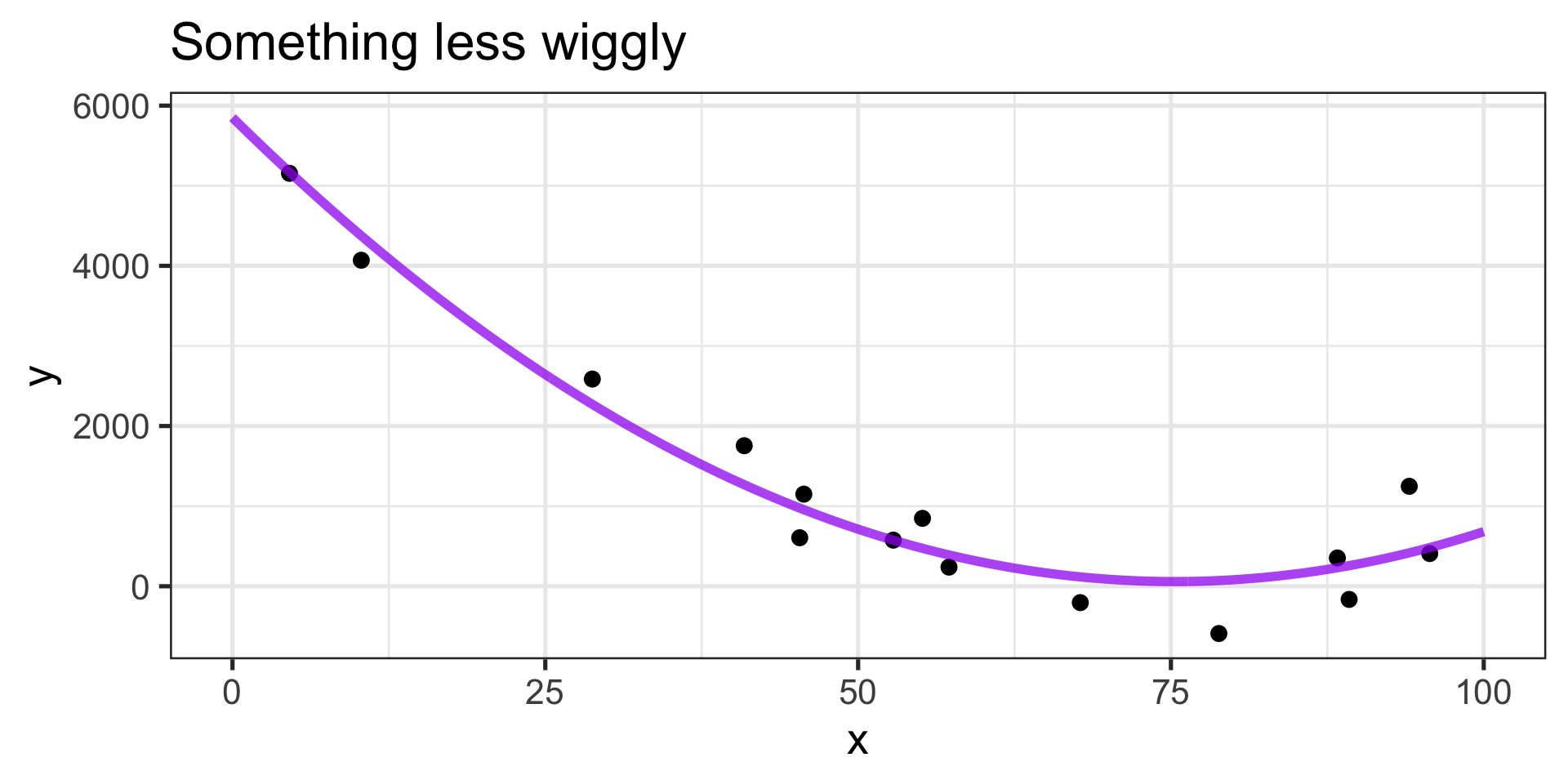
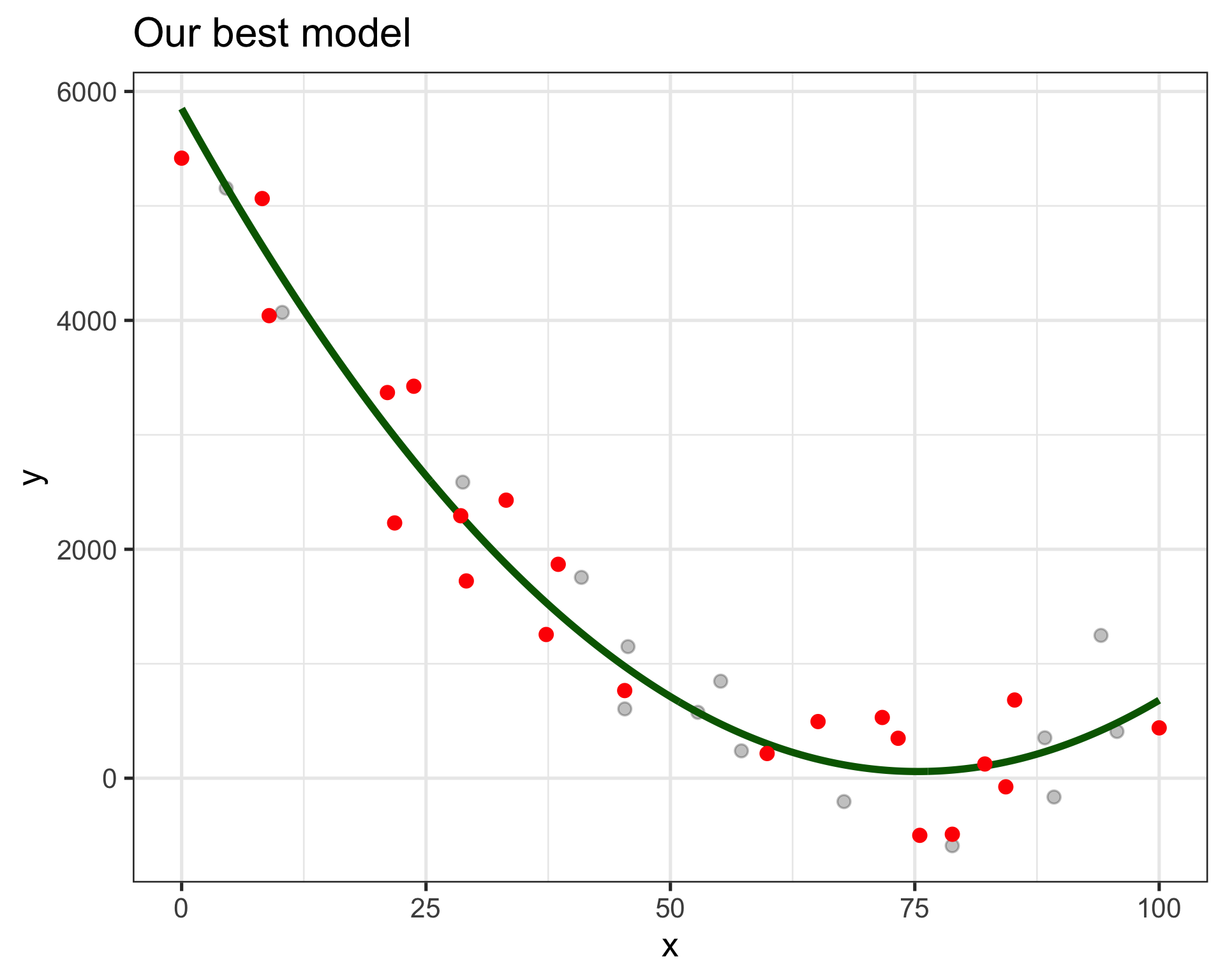
Is there a happy medium?
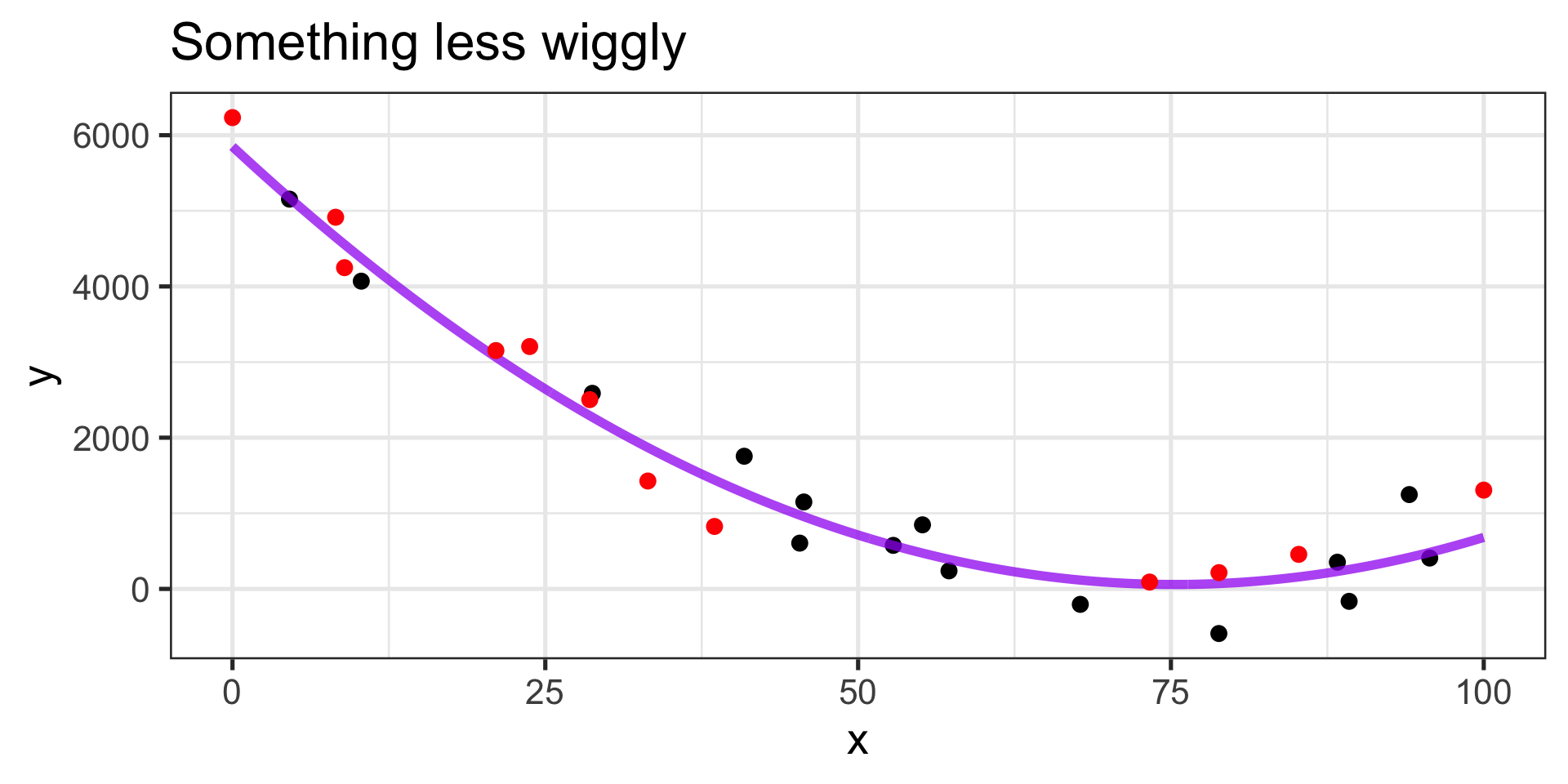
Is there a happy medium?
Fits old and new observations similarly well
Equation \(\displaystyle{\mathbb{E}\left[y\right] \approx 1202 -4912x + 3156x^2}\)
- We’ll be able to interpret this
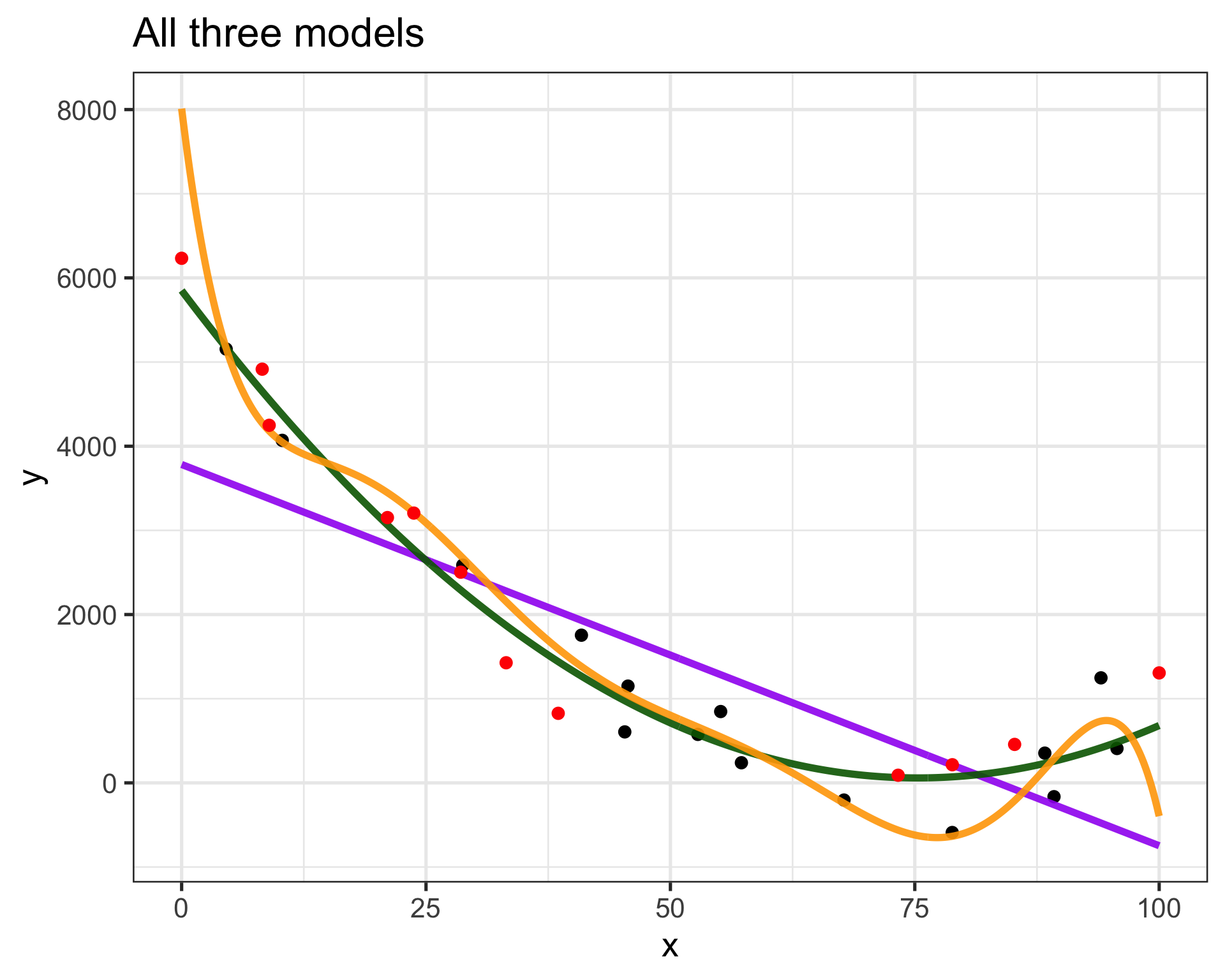
How do we know what model is right?
- The purple model is too straight
- The orange model is too wiggly
- The green model is just right
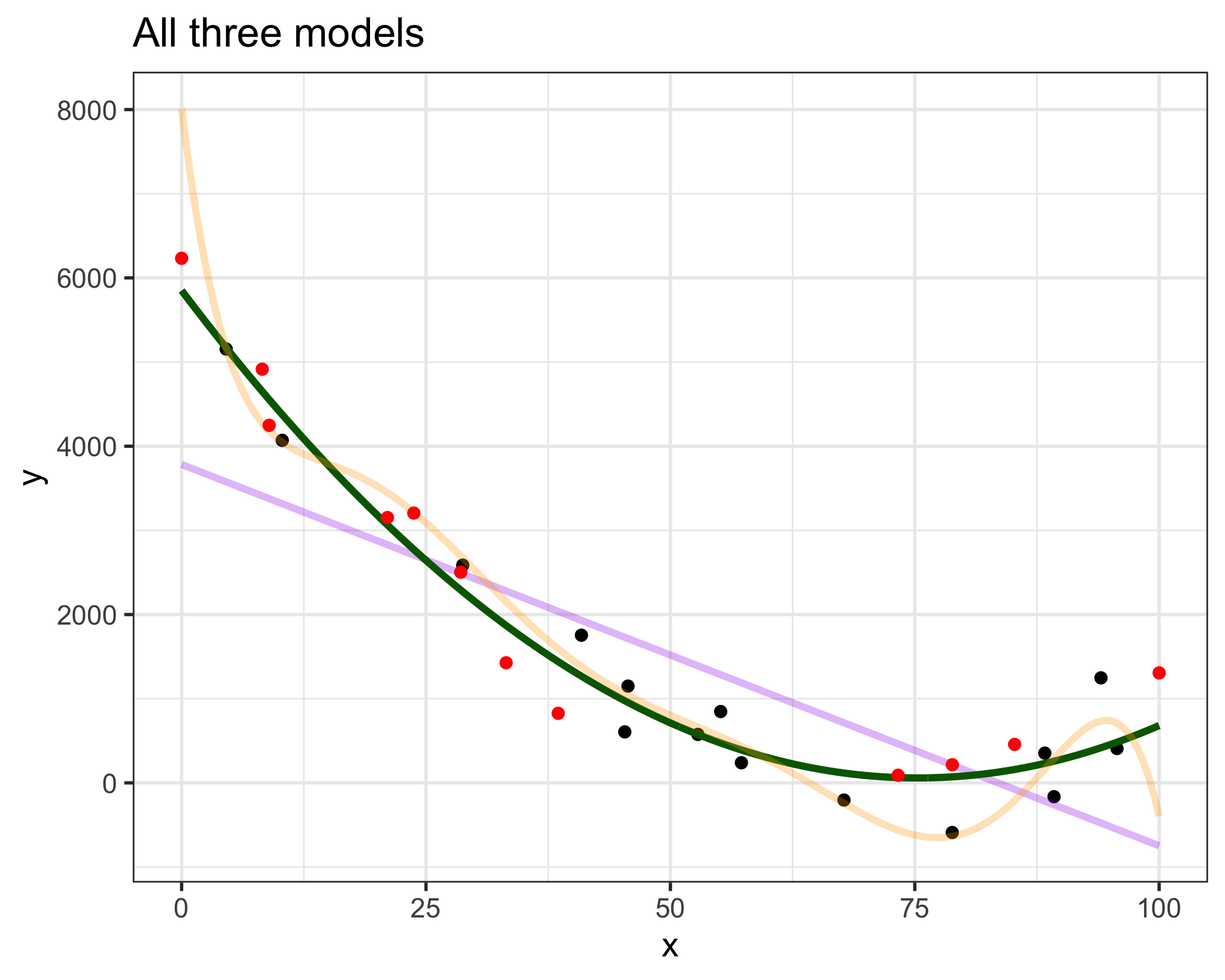
How do we know what model is right?
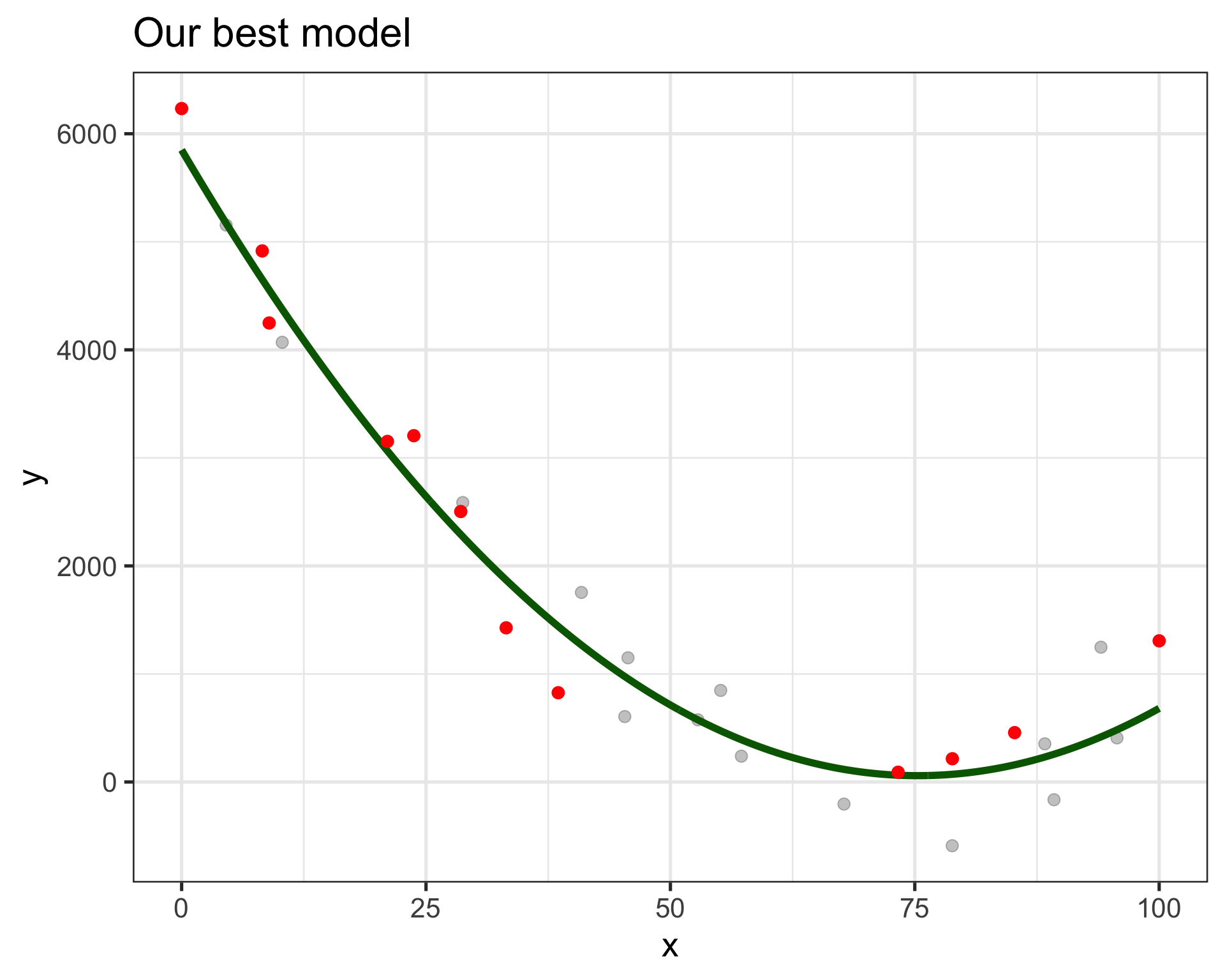
We don’t want to wait for new data to know we are wrong.
- Use some of our available data for training
- And the rest for validation
Okay, but our predictions are all wrong…literally!
- All models are wrong, but some are useful, George Box (1976)
- Predictions will be wrong but, with some assumptions, they have value
Comment: Confirmatory versus Exploratory Workflows
There are two different circumstances from which we can come at statistics and data projects.
Exploratory Settings: Where we don’t yet have well-defined expectations or formal hypotheses generated about associations, patterns, or relationships in our data.
Confirmatory Settings: Where we have generated formal hypotheses or perhaps even officially pre-registered them prior to collecting any data.
The scenario we are in dictates the workflow we must use in order to conduct valid inference.