Hyperparameters and Tuning
November 19, 2024
Tuning a Decision Tree Regressor
Decision tree regressors are a great first model class to tune because optimizing the max_depth parameter is intuitive
The deeper a decision tree, the more flexible it is, and the more likely it is to overfit
Tuning a Decision Tree Regressor
Decision tree regressors are a great first model class to tune because optimizing the max_depth parameter is intuitive
The deeper a decision tree, the more flexible it is, and the more likely it is to overfit
If a tree is too shallow though, it will be underfit
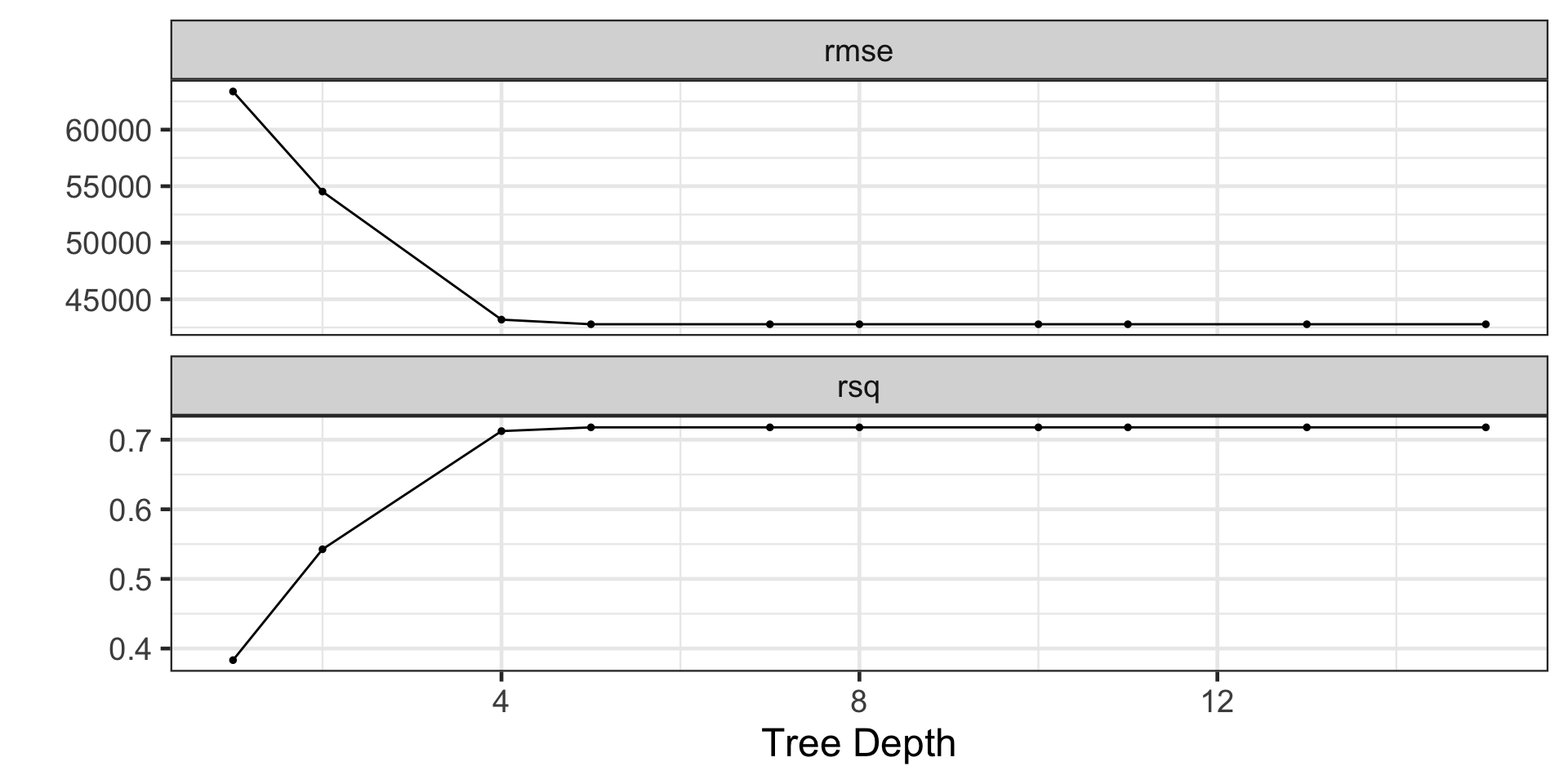
Let’s tune a tree to identify the optimal depth for predicting selling prices of homes in the Ames, Iowa data
Visualizing the Tuning Results
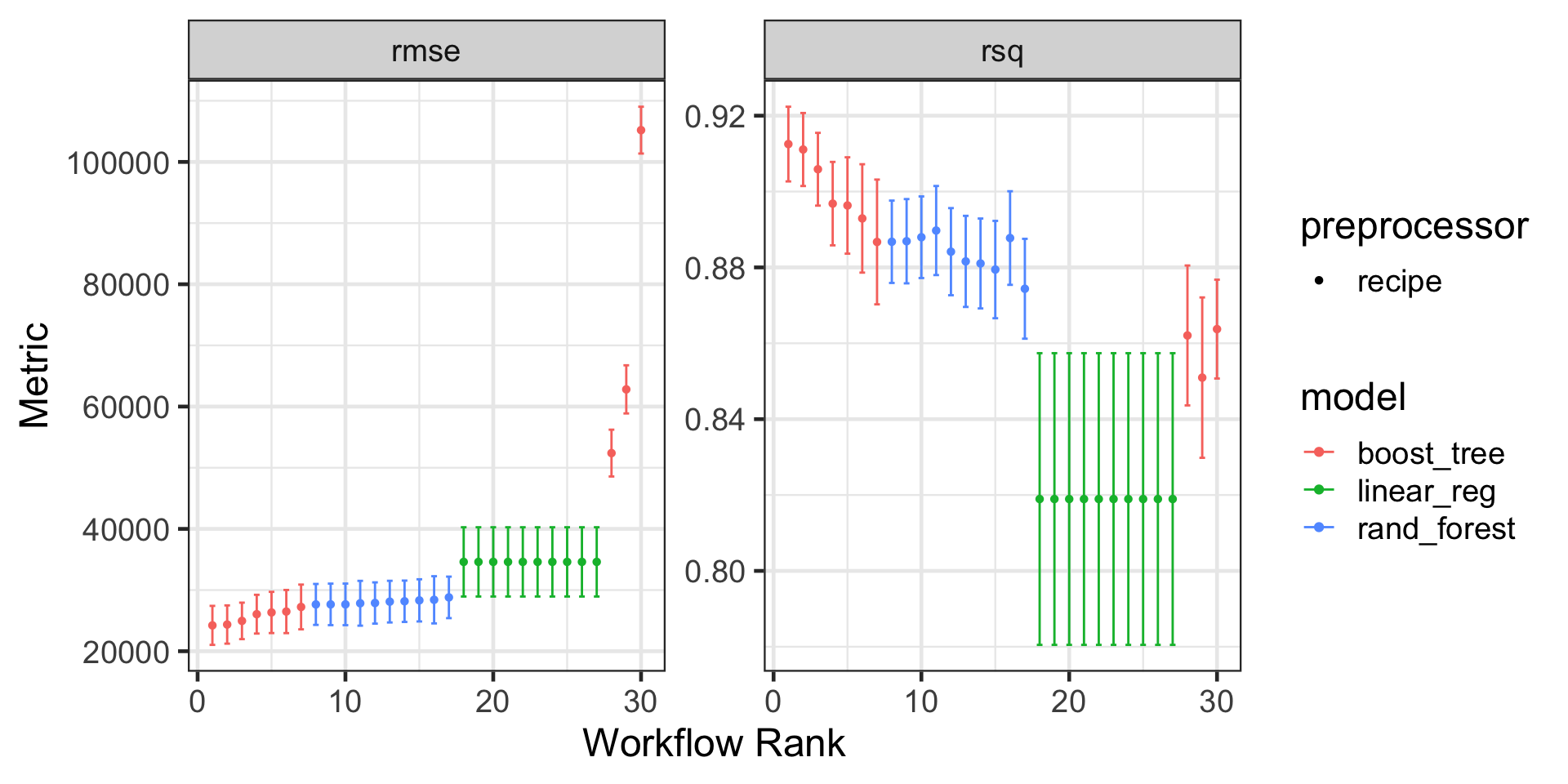
We see that several tree depths result in models that perform similarly to one another
Eventually, including additional flexibility doesn’t translate into improvements in our model performance metrics
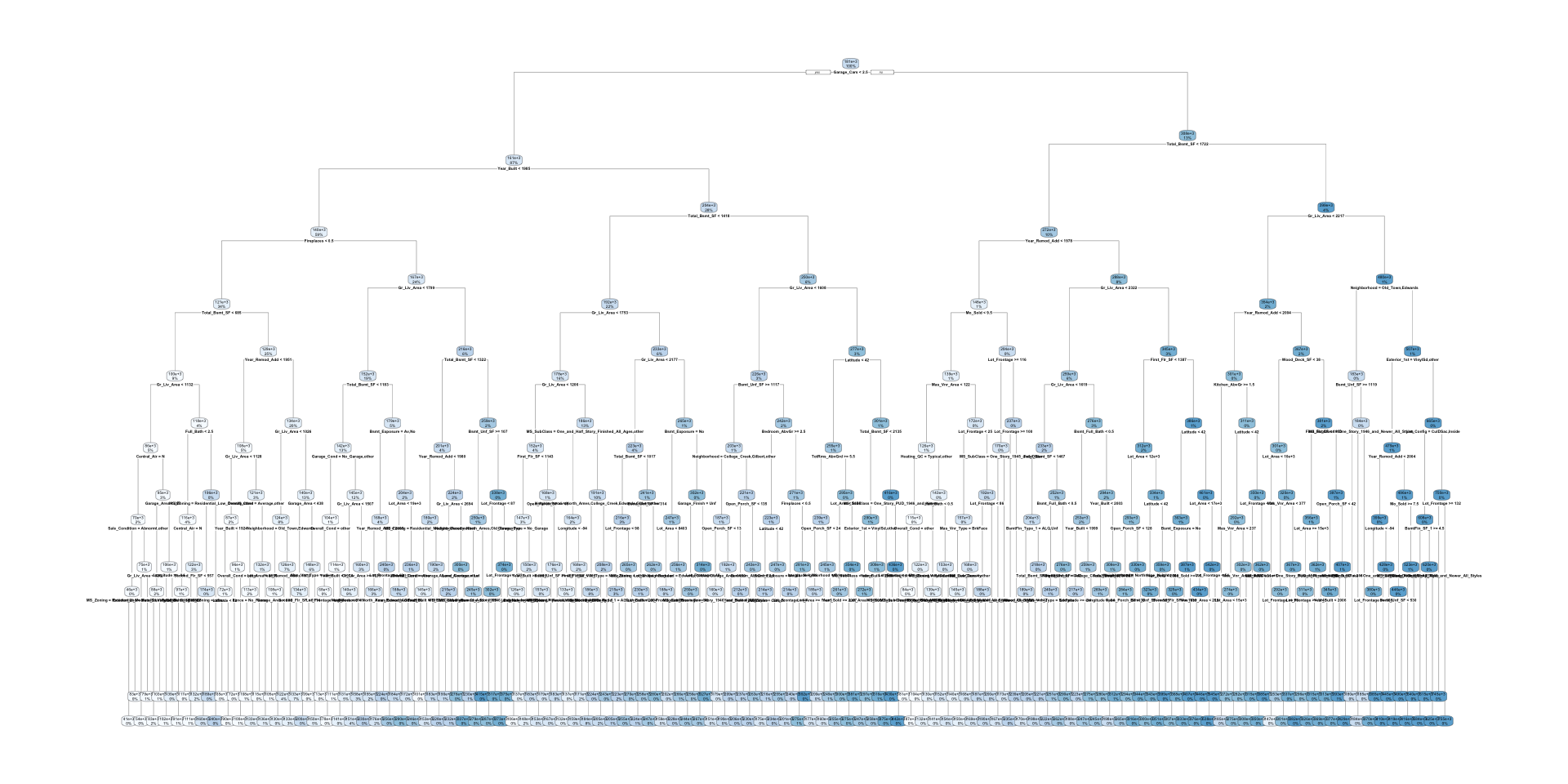
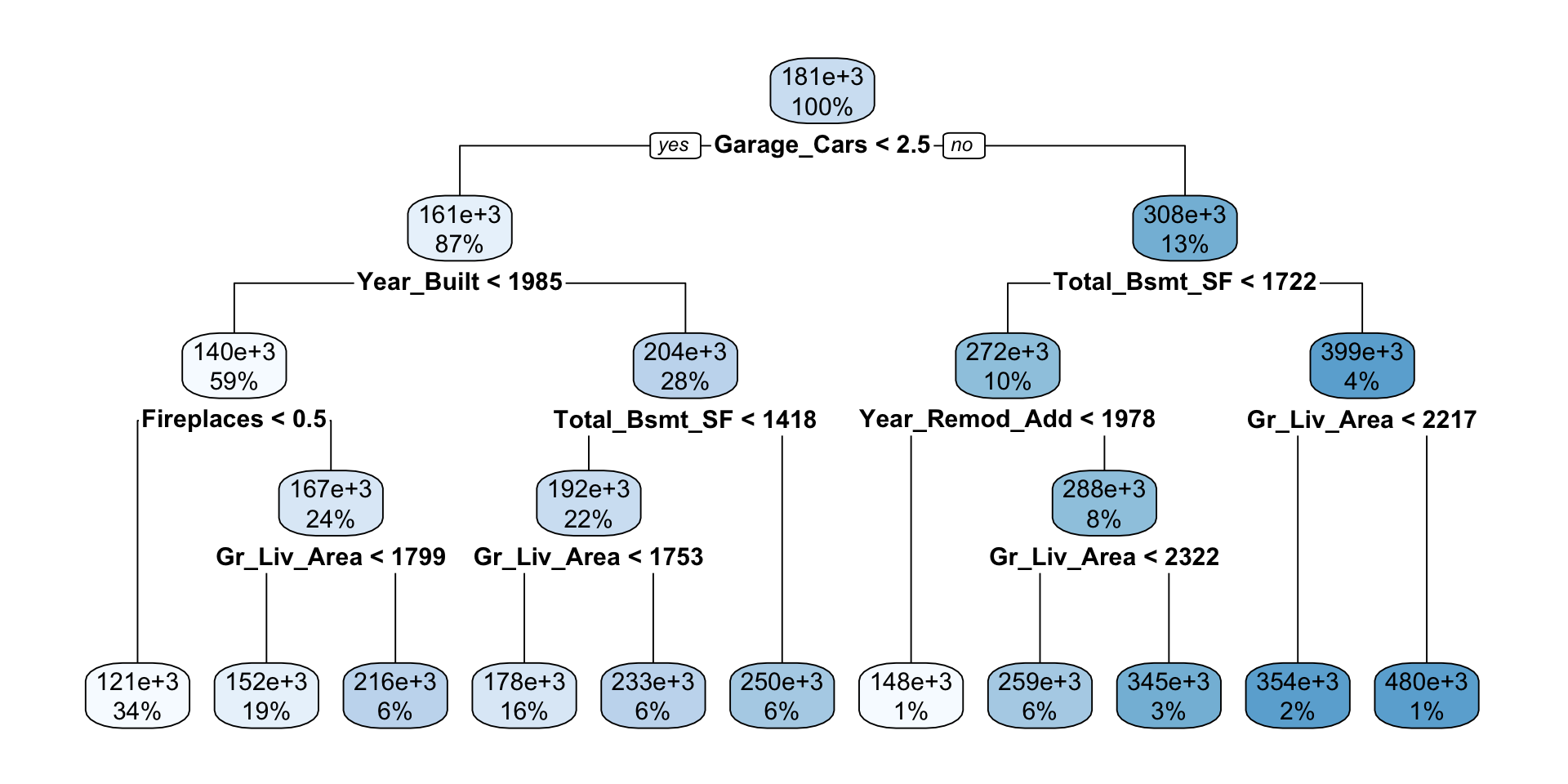
Visualizing the Decision Tree
A major strength of decision trees is how interpretable and intuitive they are (if we can see them)
Visualizing Results
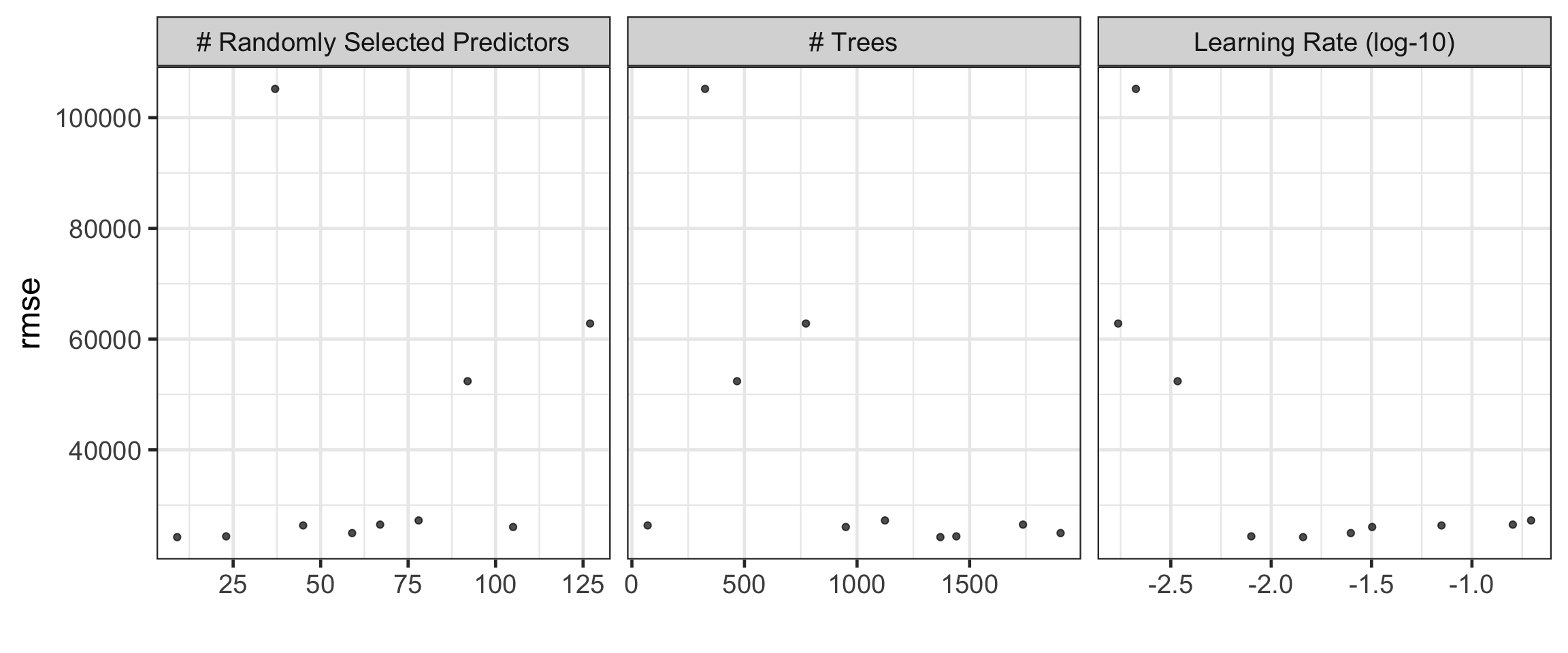
Seeing Best Hyperparameter Combinations
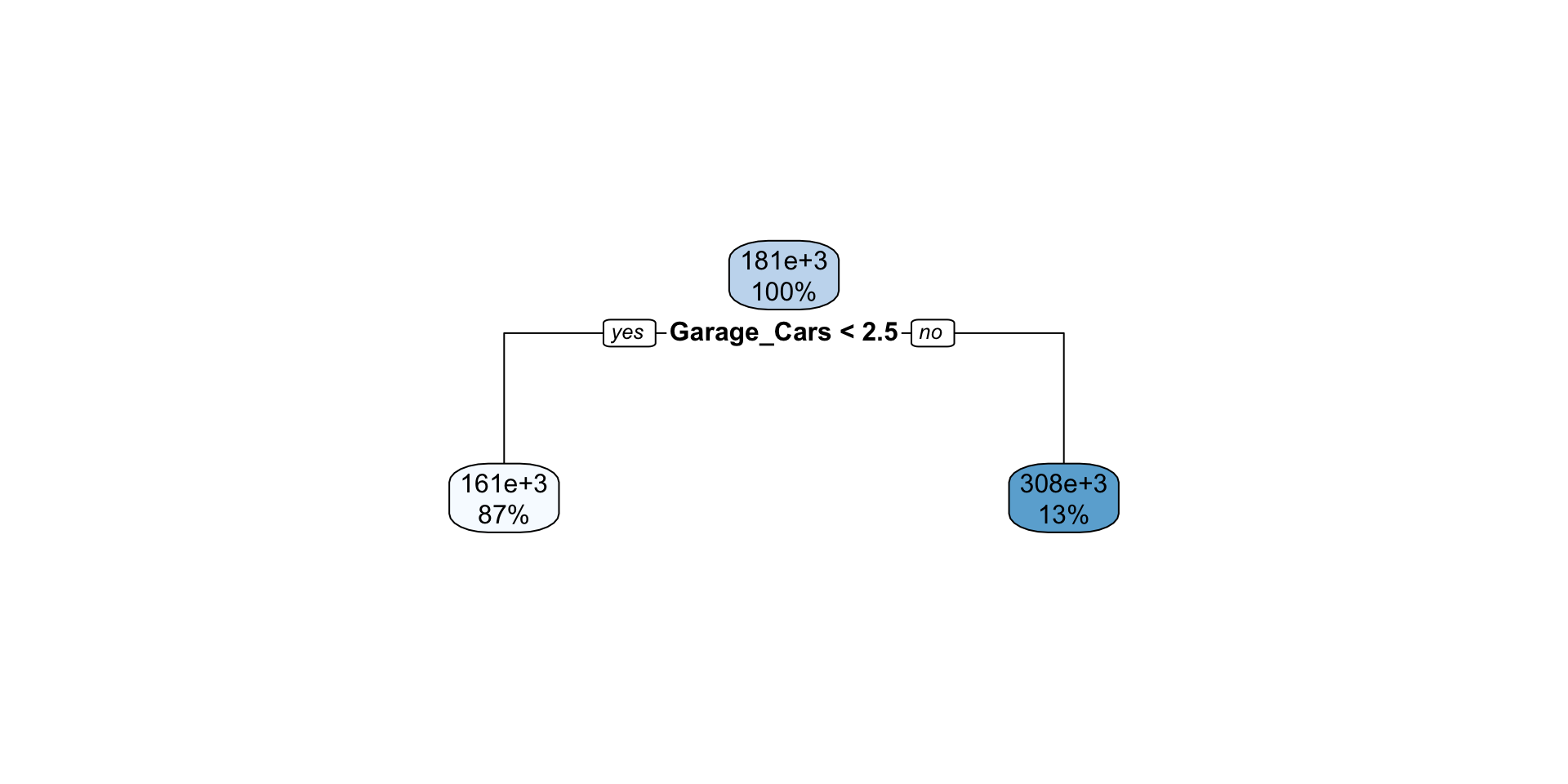
Extracting Important Predictors
Ensembles are not generally known for their interpretability
We can, however, identify the predictors which are most important to the ensemble using the vip() function from the {vip} package

Assessing Performance
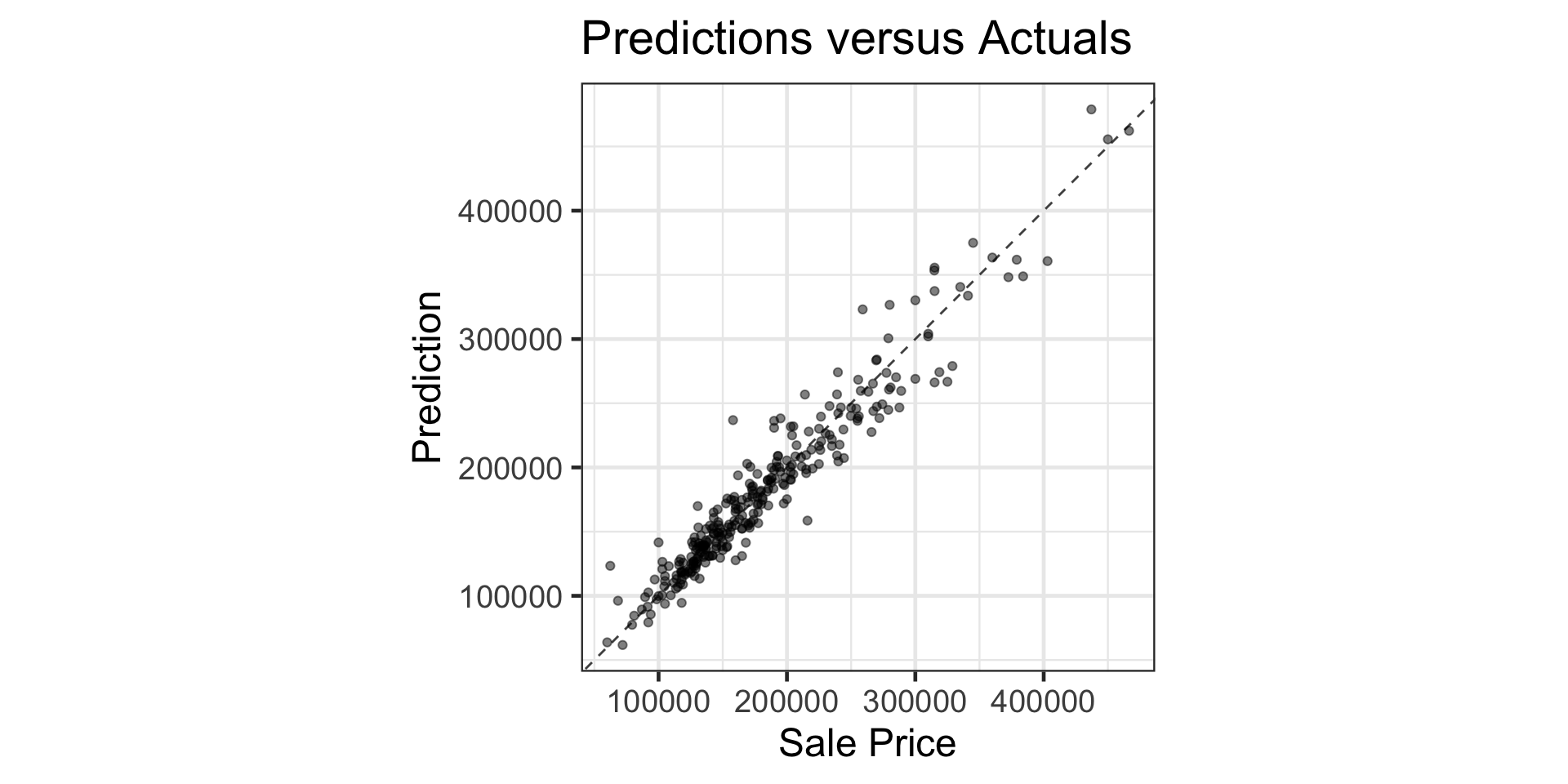
Let’s assess our model’s performance on our test data
xgb_results <- xgb_fit %>%
augment(ames_test) %>%
select(Sale_Price, .pred)
xgb_results %>%
ggplot() +
geom_point(aes(x = Sale_Price, y = .pred),
alpha = 0.5) +
geom_abline(slope = 1, intercept = 0,
linetype = "dashed", alpha = 0.75) +
labs(
title = "Predictions versus Actuals",
x = "Sale Price",
y = "Prediction"
) +
coord_equal()