#install.packages("xgboost")library(tidyverse)library(tidymodels)library(patchwork)library(kableExtra)library(modeldata)tidymodels_prefer()options(kable_styling_bootstrap_options =c("hover", "striped"))#Set ggplot base themetheme_set(theme_bw(base_size =14))ames <-read_csv("https://raw.githubusercontent.com/koalaverse/homlr/master/data/ames.csv")
Recap
In our most recent notebooks, we’ve gone beyond Ordinary Least Squares and explored additional classes of model. We began with penalized least squares models like Ridge Regression and the LASSO. We extended our knowledge of model classes to nearest neighbor and tree-based models as well as ensembles of models in the previous notebook. We ended that notebook with a short discussion on parameter choices that must be made prior to model training – such parameters are known as hyperparameters. In this notebook, we learn how to use cross-validation to tune our model hyperparameters.
Objectives
In this notebook, we’ll accomplish the following:
Use tune() for model parameters as well as in feature engineering steps to identify hyperparameters that we want to tune through cross-validation.
Use cross-validation and tune_grid() to tune the hyperparameters for a single model, identify the best hyperparameter choices, and fit the model using those best choices.
Build a workflow_set(), choose hyperparameters that must be tuned for each model and recipe, use cross-validation to tune models and select “optimal” hyperparameter values, and compare the models in the workflow set.
Tuning Hyperparameters for a Single Model
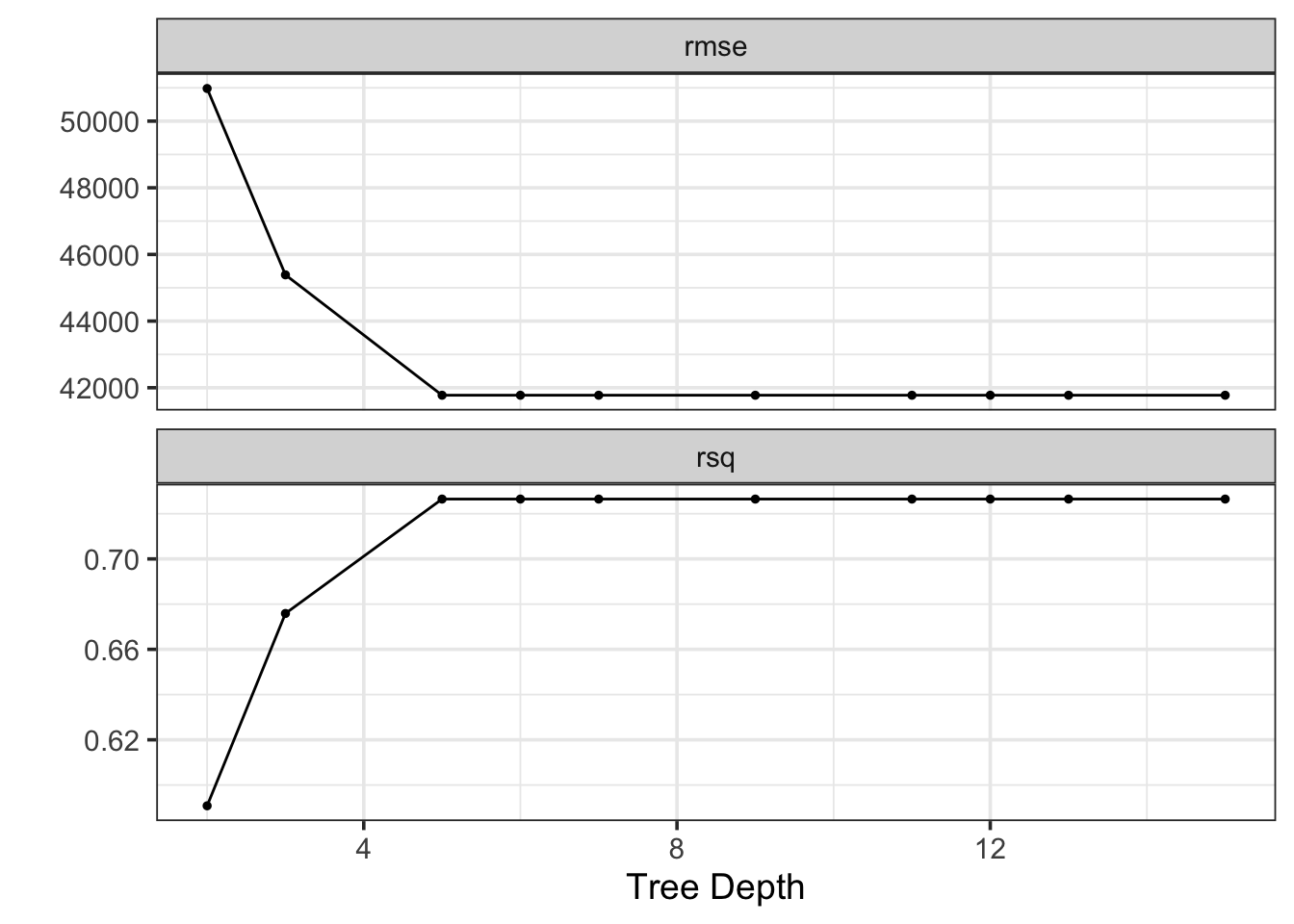
Let’s start with a decision tree model and we’ll tune the tree depth parameter. We’ll work with the ames data again for now.
We see from the plots above that deeper trees seemed to perform better than shallow trees. We don’t observe much improvement in performance after a depth of 5. The risk of overfitting increases with deeper trees. We do seem to get some benefit by increasing the depth of the tree beyond 4. For this reason, I’ll choose a tree depth of 5. The output of show_best() below shows our best-performing depths in terms of RMSE.
Warning: Cannot retrieve the data used to build the model (so cannot determine roundint and is.binary for the variables).
To silence this warning:
Call rpart.plot with roundint=FALSE,
or rebuild the rpart model with model=TRUE.
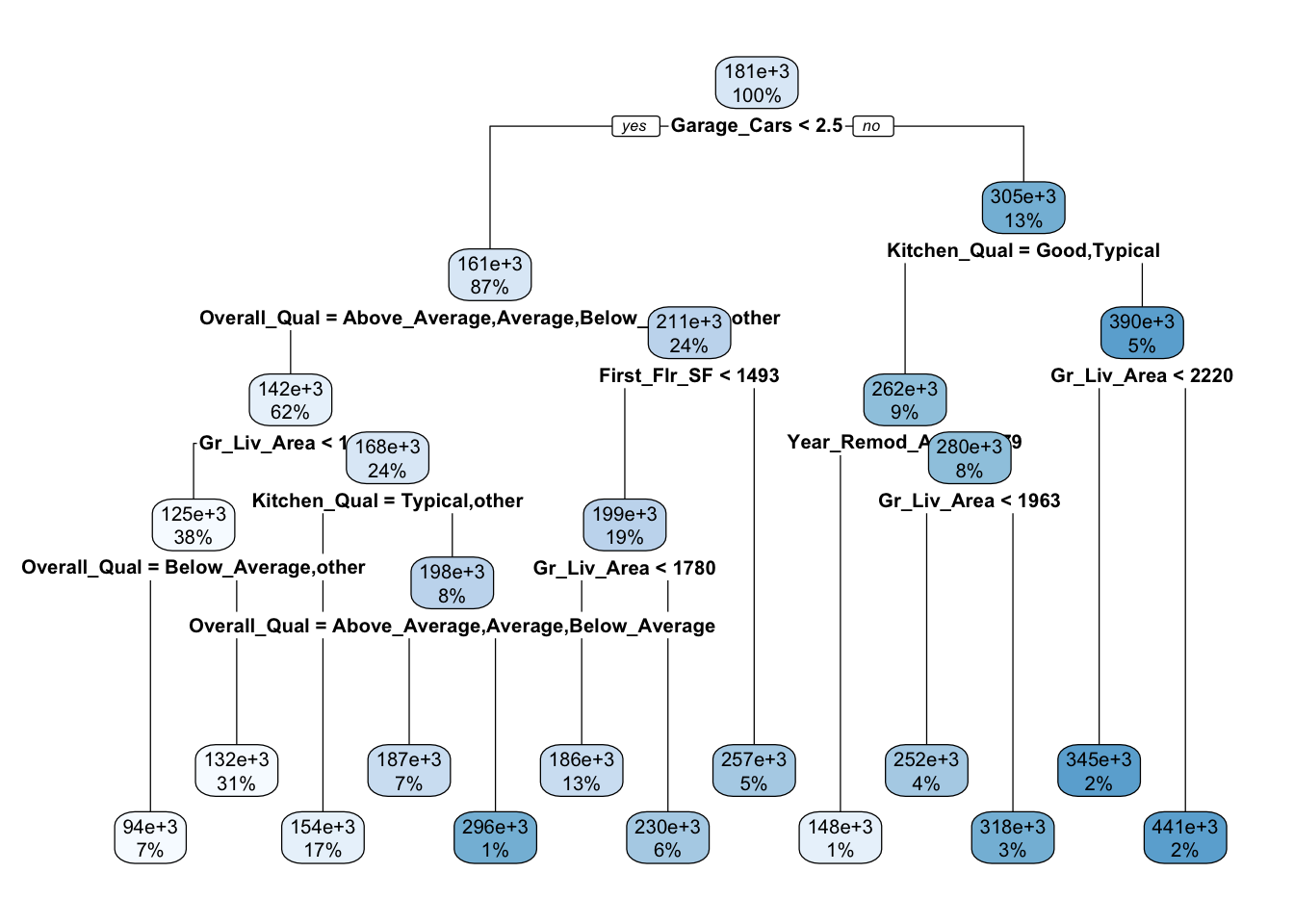
The model we built above can be interpreted and can also be utilized to make predictions on new data just like out previous models. Next, let’s look at how we can tune multiple models with a variety of hyperparameters in a workflow_set(). We’ll fit a LASSO, a random forest, and a gradient boosted model.
Tuning Hyperparameters Across a Workflow Set
Let’s create model specifications and recipes for each of the models mentioned in earlier notebooks.
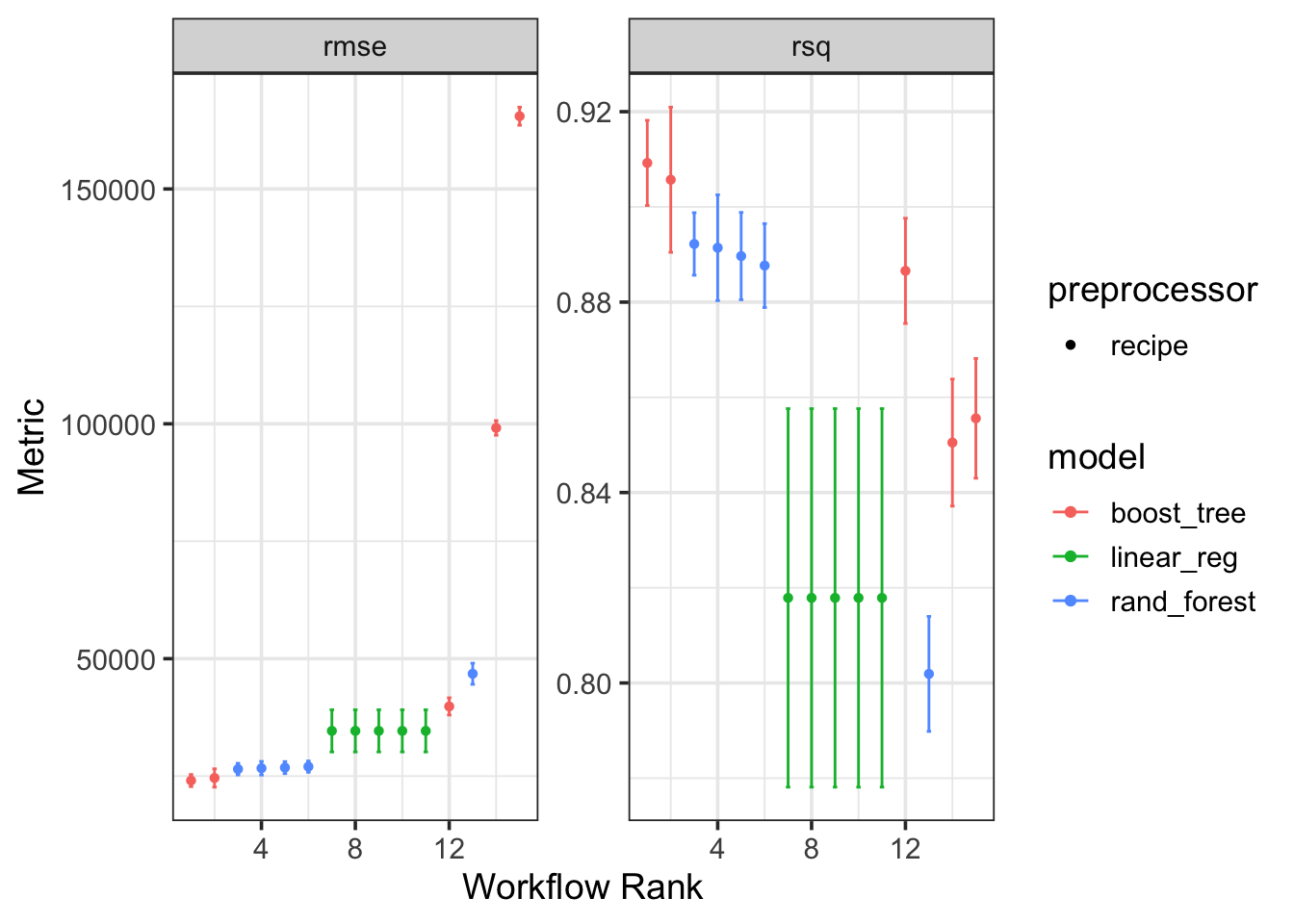
The model performing the best was the gradient boosted tree ensemble. Let’s see what hyperparameter choices led to the best performance.
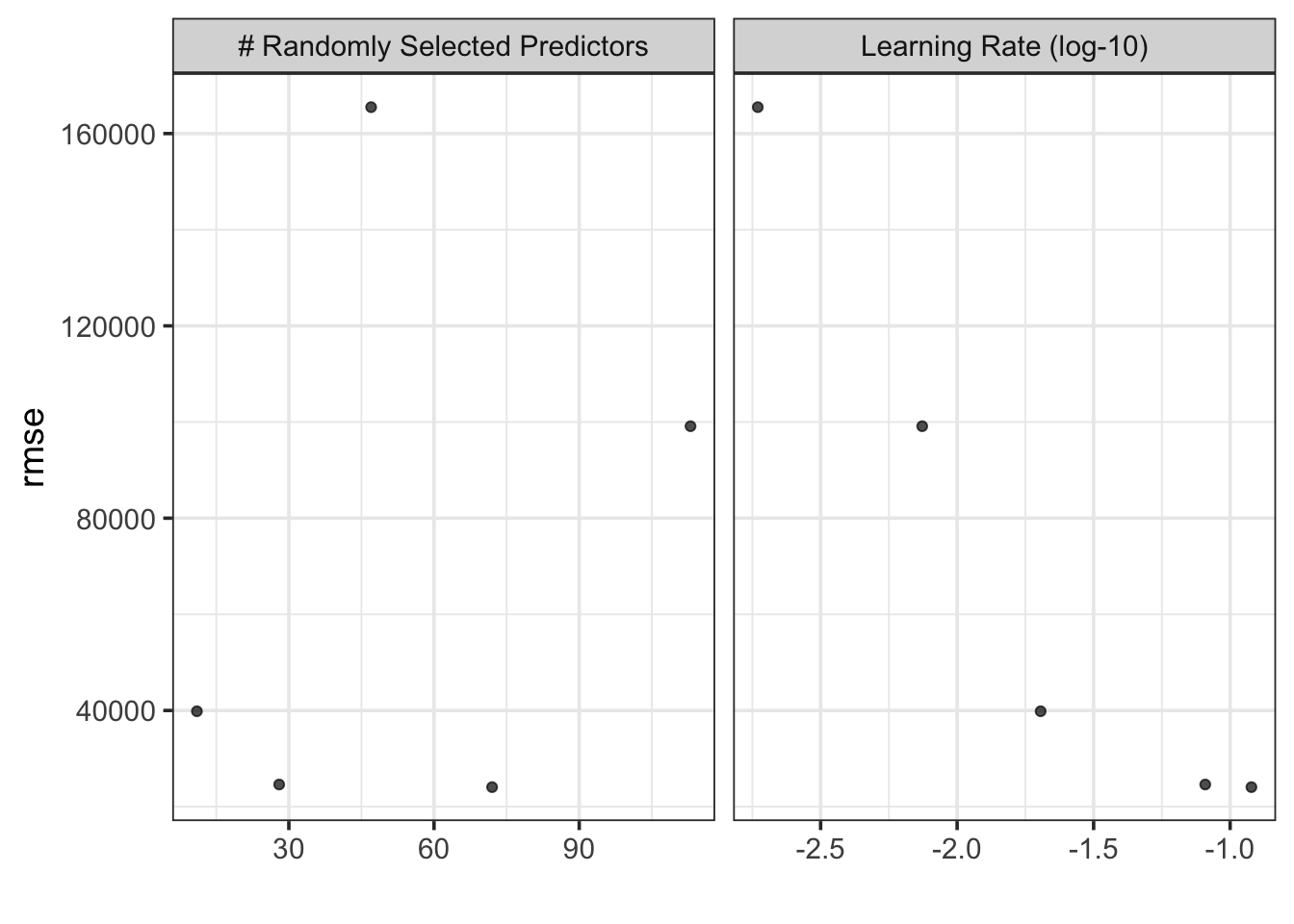
grid_results %>%autoplot(metric ="rmse", id ="rec_gb_tree")
It seems that a number of randomly selected parameters of near 30 gave the best performance and learning rates near 0.1 did as well. We’ll construct this model and fit it to our training data.
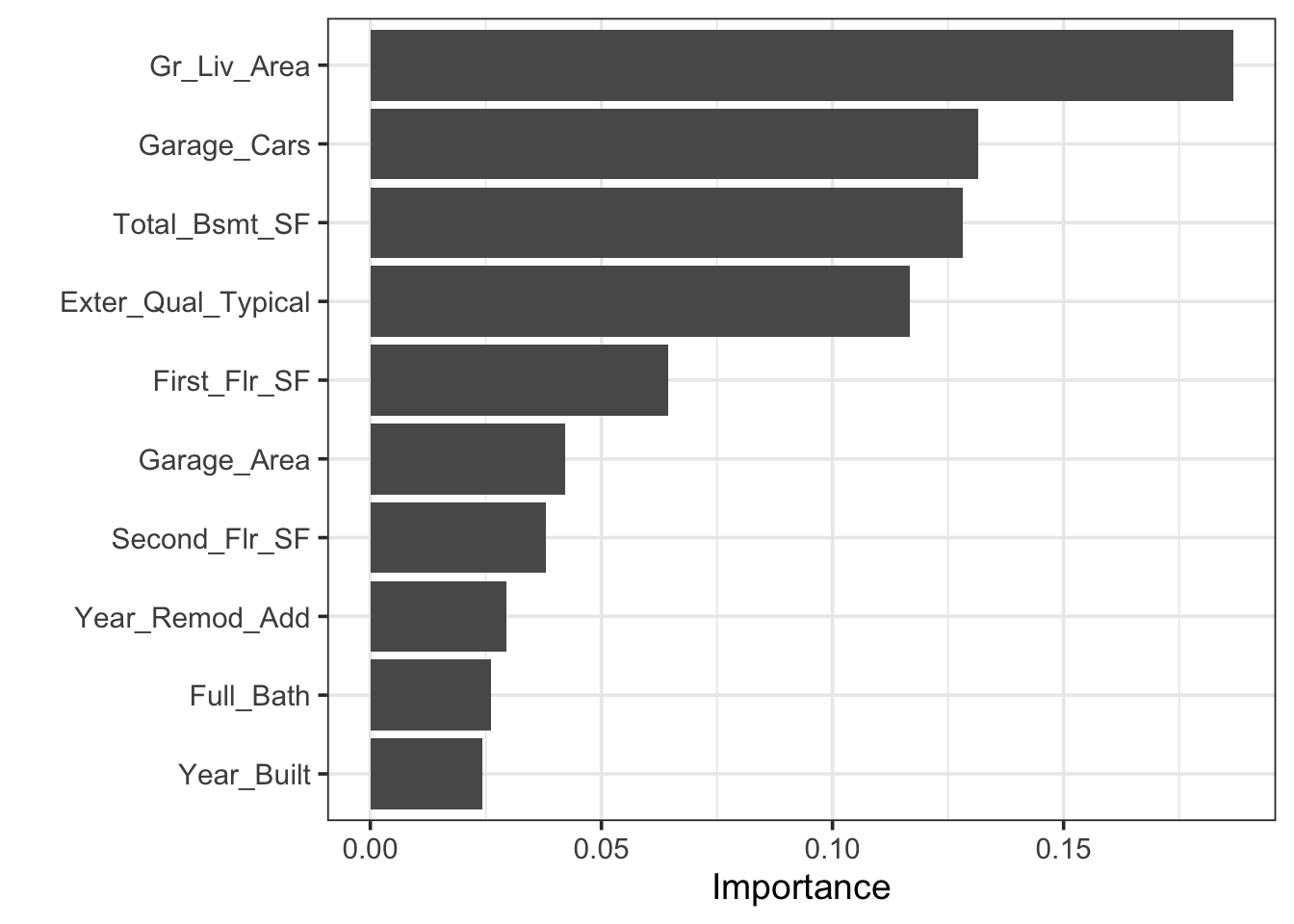
Such a model doesn’t have much interpretive value but can make very good predictions. We can identify the predictors which were most important within the ensemble by using var_imp().
From the plot above, we can see the features that were most the important predictors of selling price within the ensemble. Note that the important predictors will shuffle around slightly each time you re-run the ensemble. Before we close this notebook, let’s take a look at how well this model predicts the selling prices of homes in our test set.
This final ensemble of models predicted selling prices of homes with an root mean squared error of $ 20,582.85.
Summary
In this notebook, we saw how to build a workflow set consisting of several models with tunable hyperparameters. We explored a space-filling grid of hyperparameter combinations with a workflow_map(). After identifying a best model and optimal(*) hyperparameter choices, we fit the corresponding model to our training data and then assessed that model’s performance on our test data.