The Bias/Variance TradeOff
October 29, 2024
Motivation
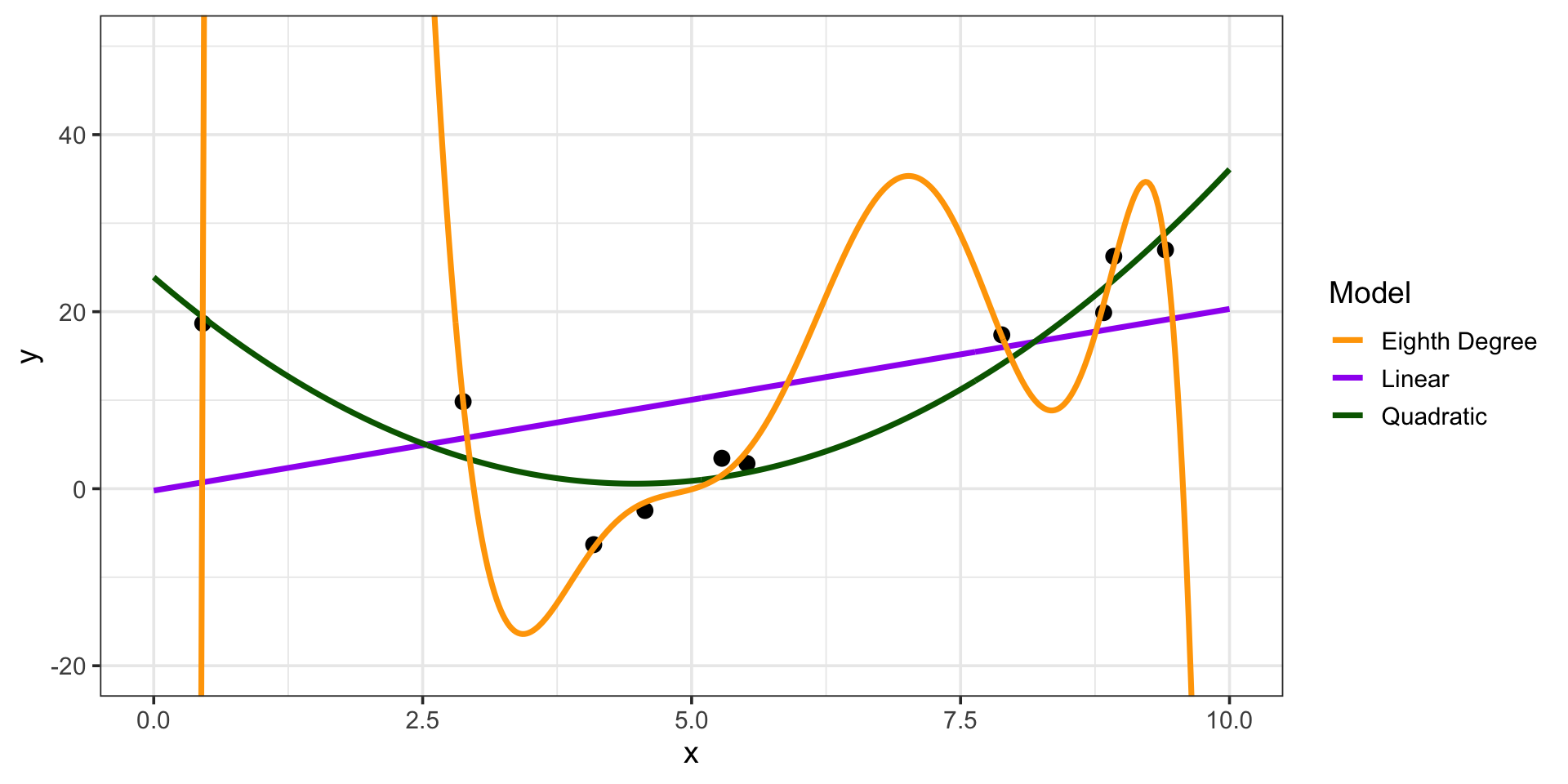
Seeing Bias and Variance in Models
Let’s bring back our Linear and Eighth Degree models from the opening slide
High Bias / Low Variance:
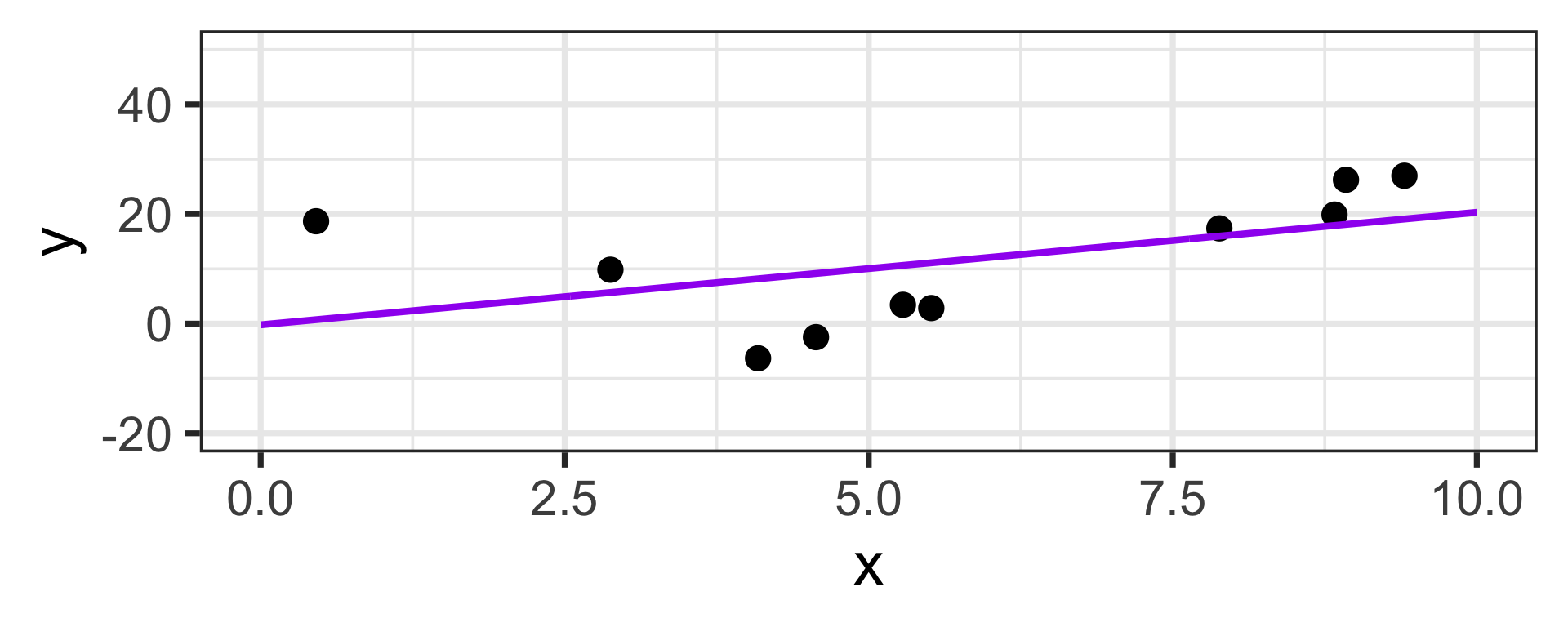
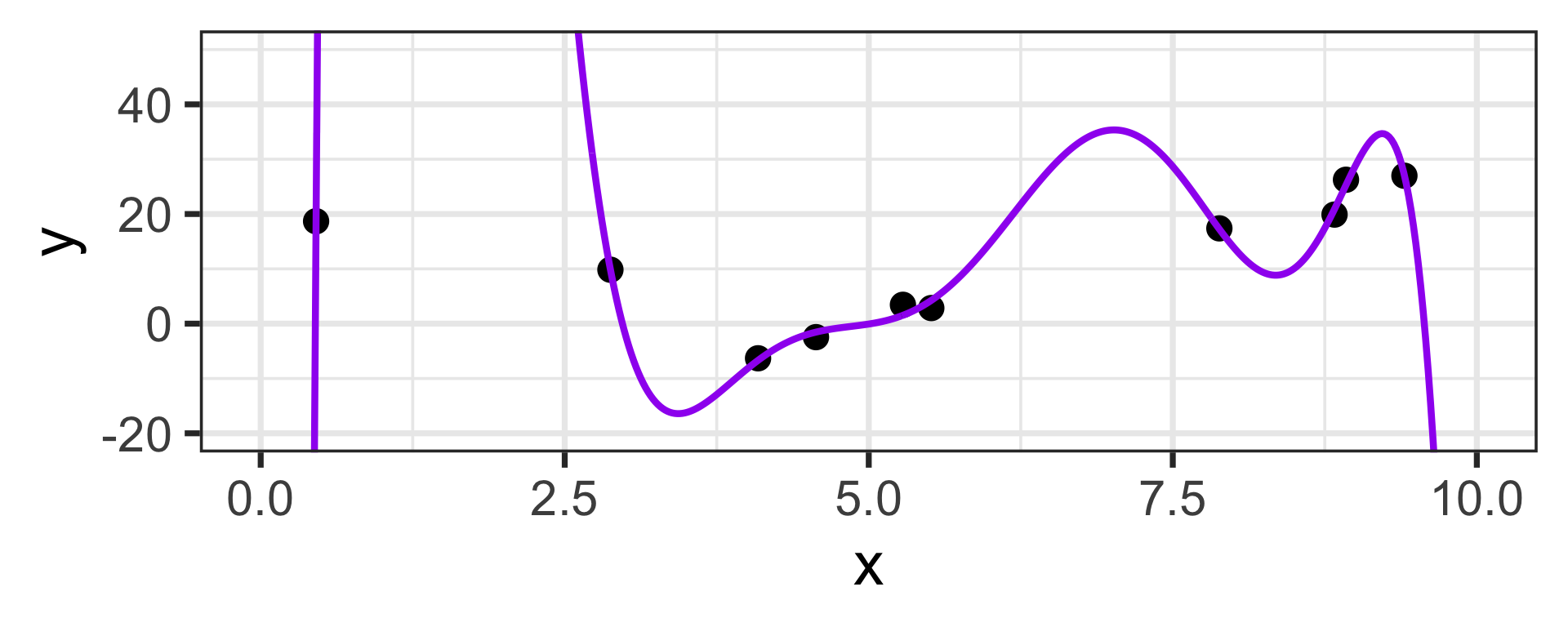
Low Bias / High Variance:
Let’s consider what would happen if we had a new training observation at \(x = 7\), \(y = 5\)
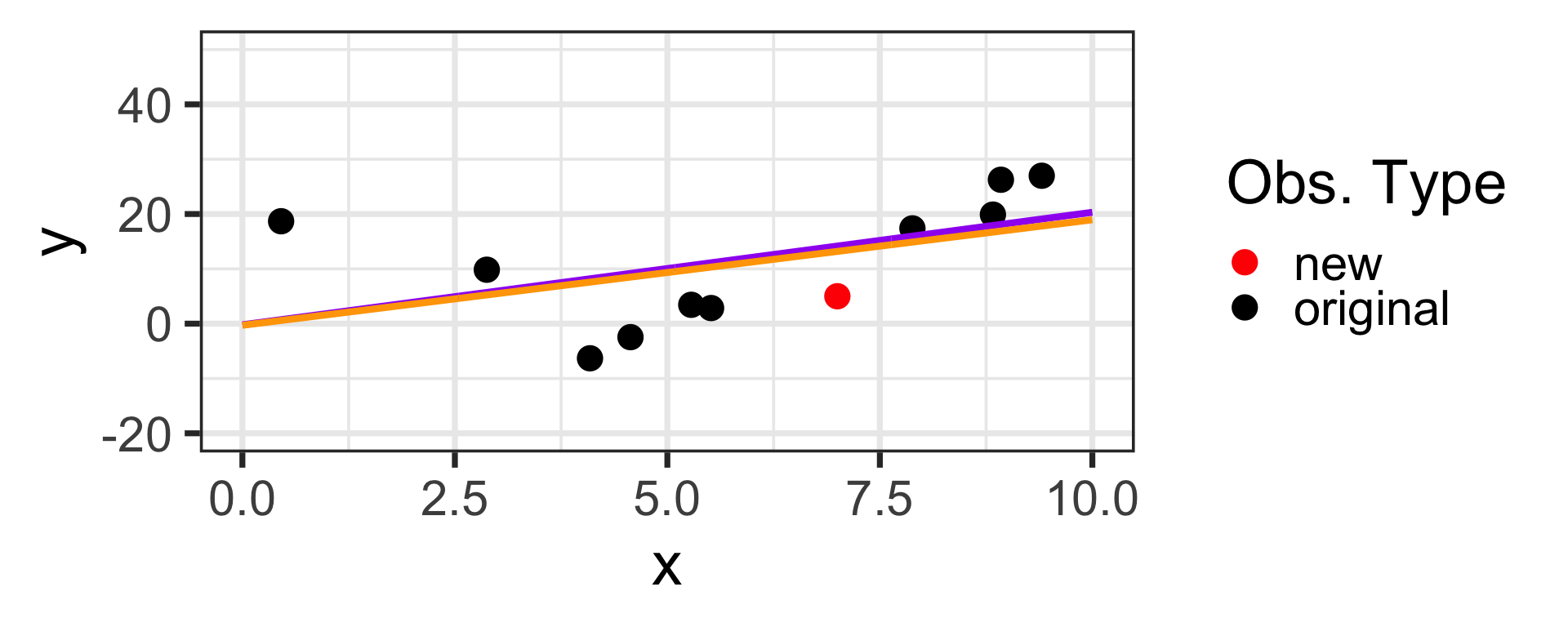
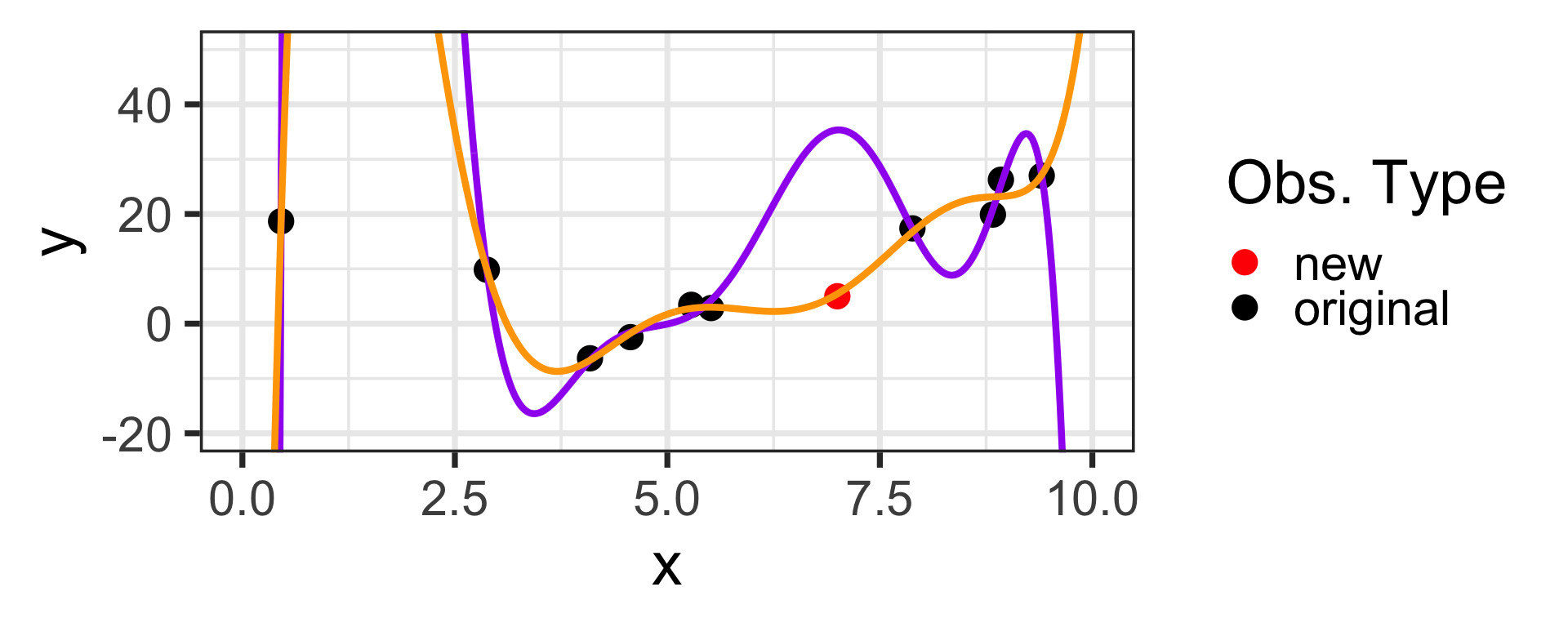
Oh No!
Seeing Bias in Our Models
On the previous slide, we saw very clearly that the model on the right had bias which was too low and variance that was too high
It is also possible for a model to have bias which is too high and variance which is too low
Consider the scenario below
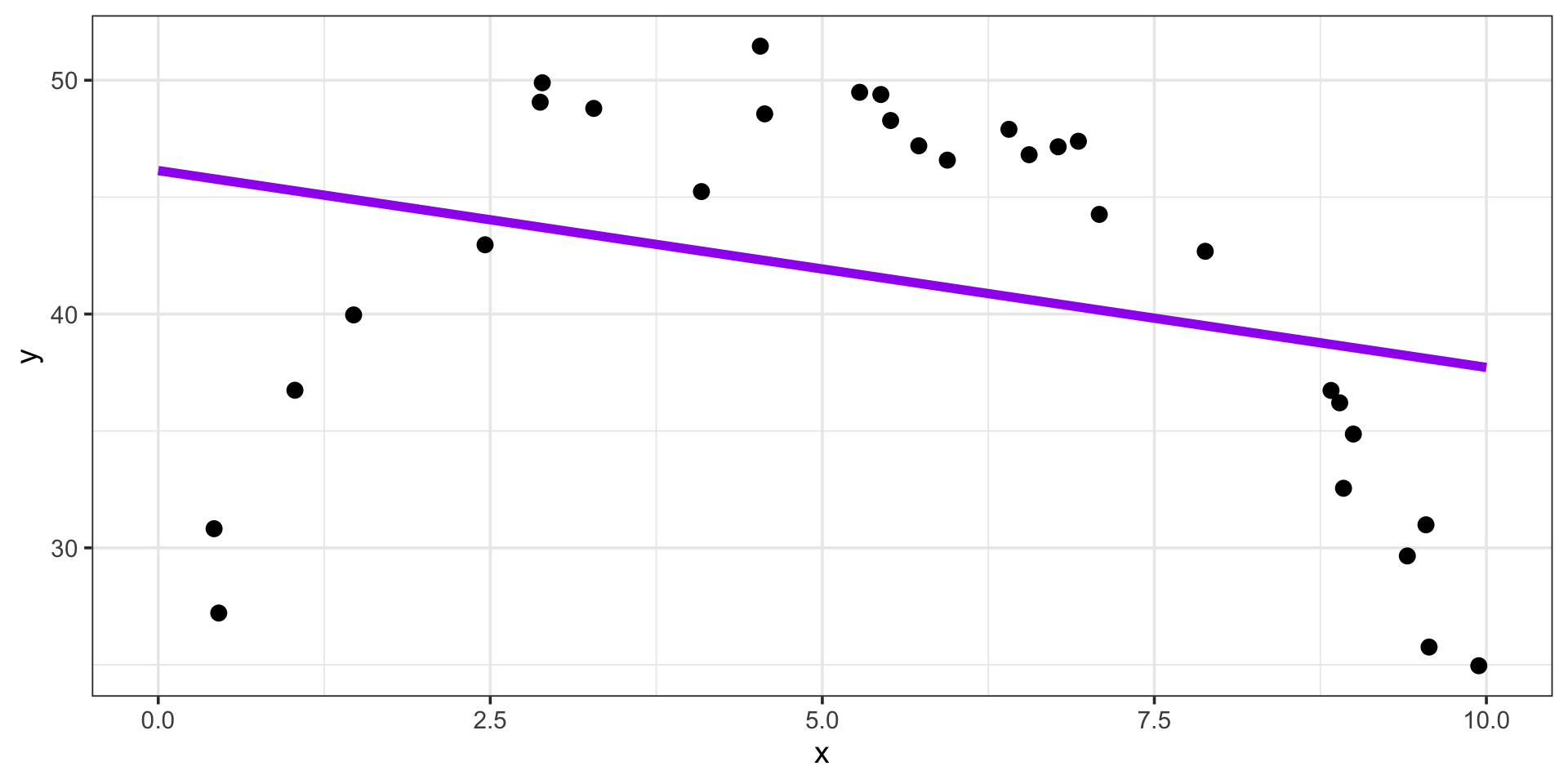
Overfitting and Underfitting
Let’s head back to the linear and eighth degree model from the opening slide again
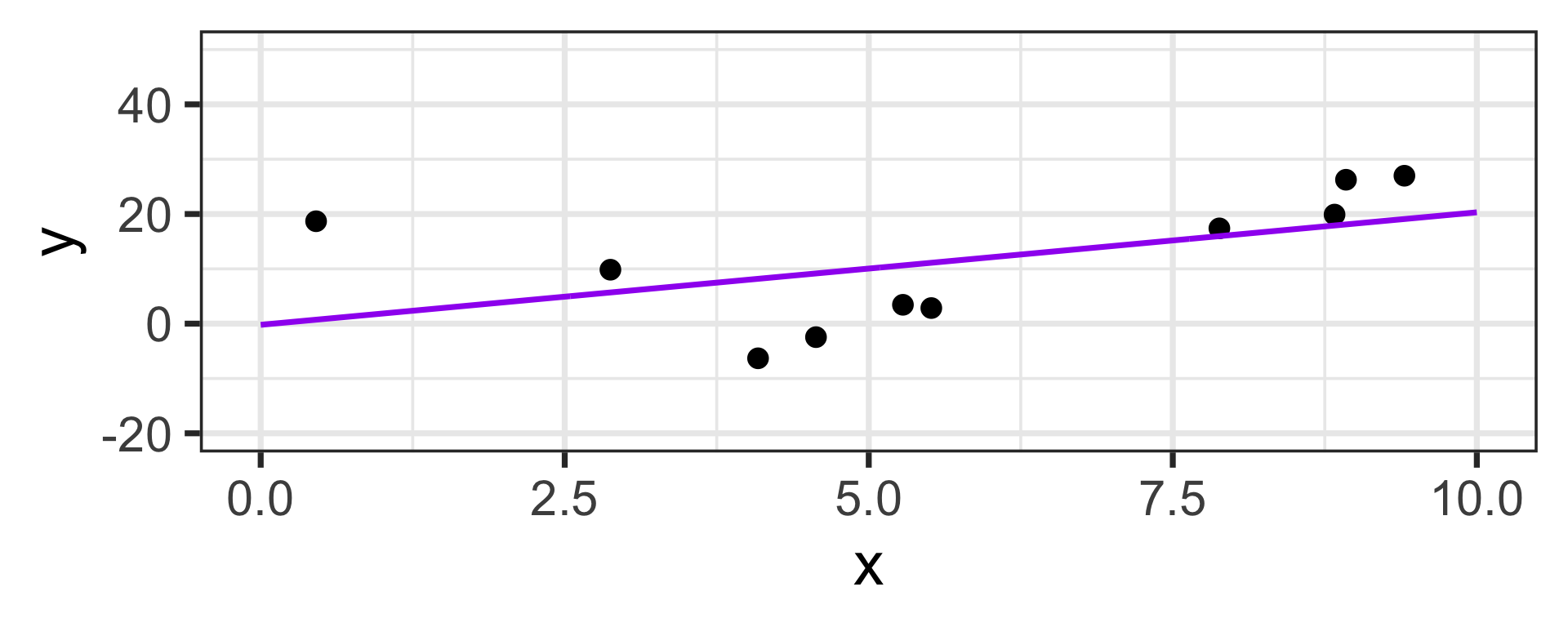
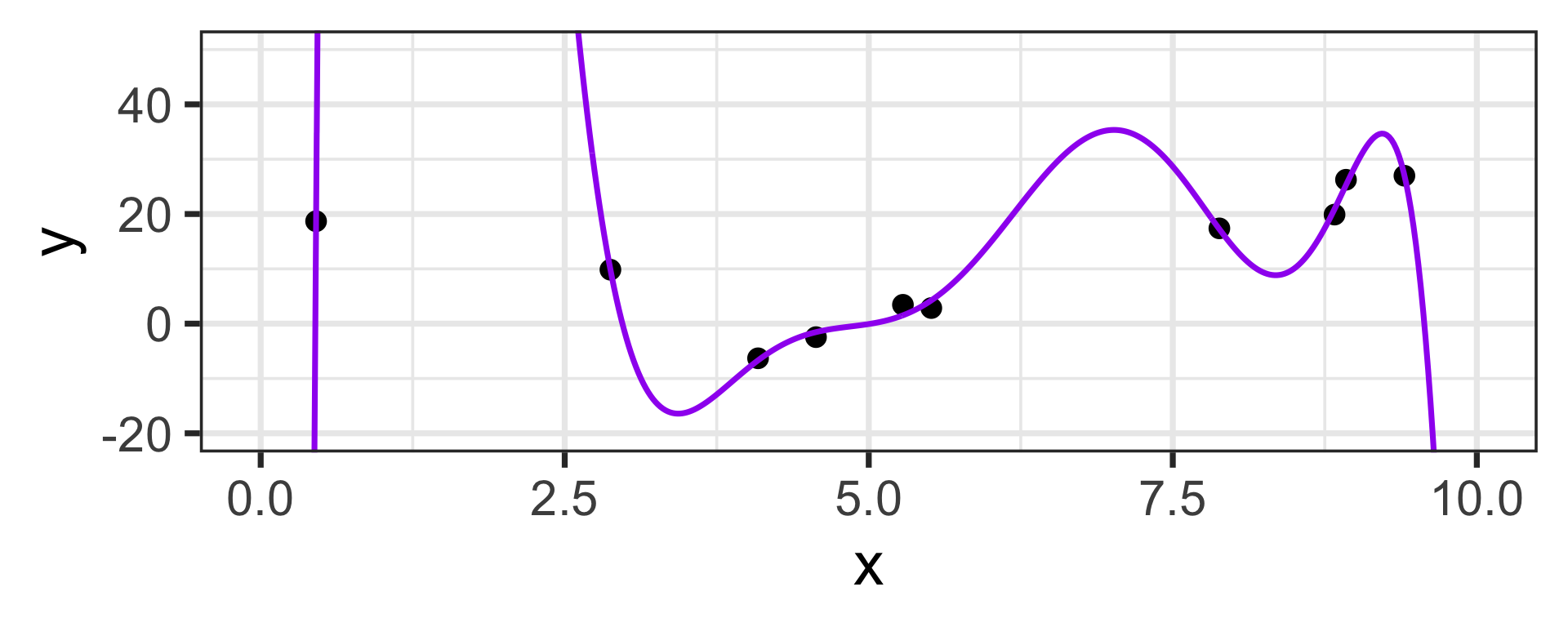
Now that we’ve fit these models, let’s see how they perform on new data drawn from the same population
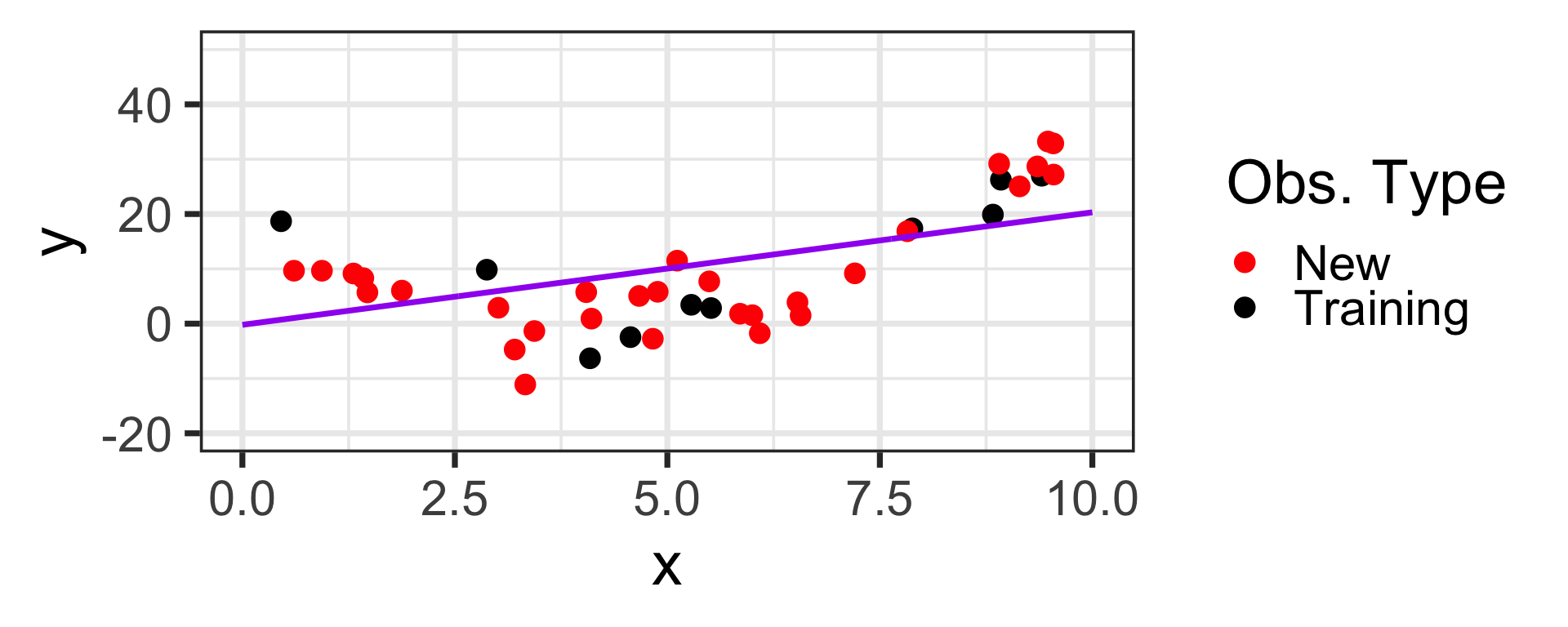
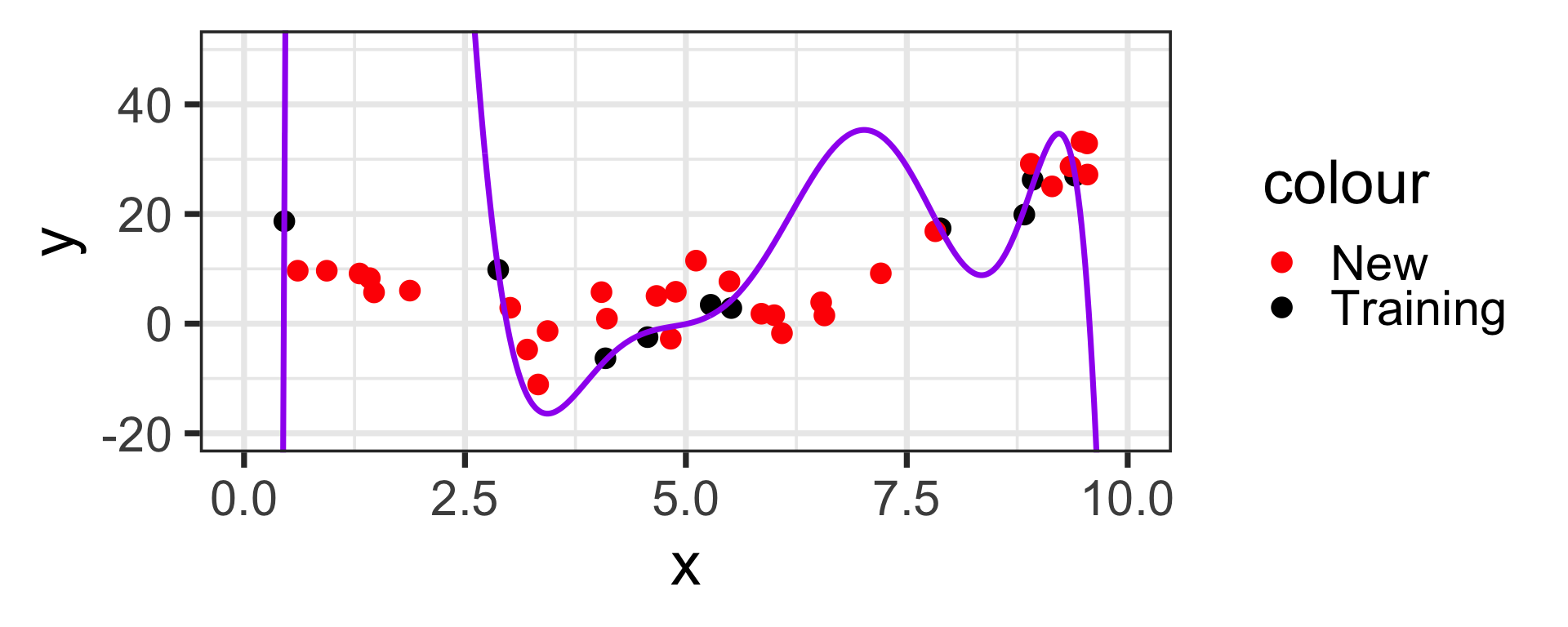
Overfitting and Underfitting
Now that we’ve fit these models, let’s see how they perform on new data drawn from the same population
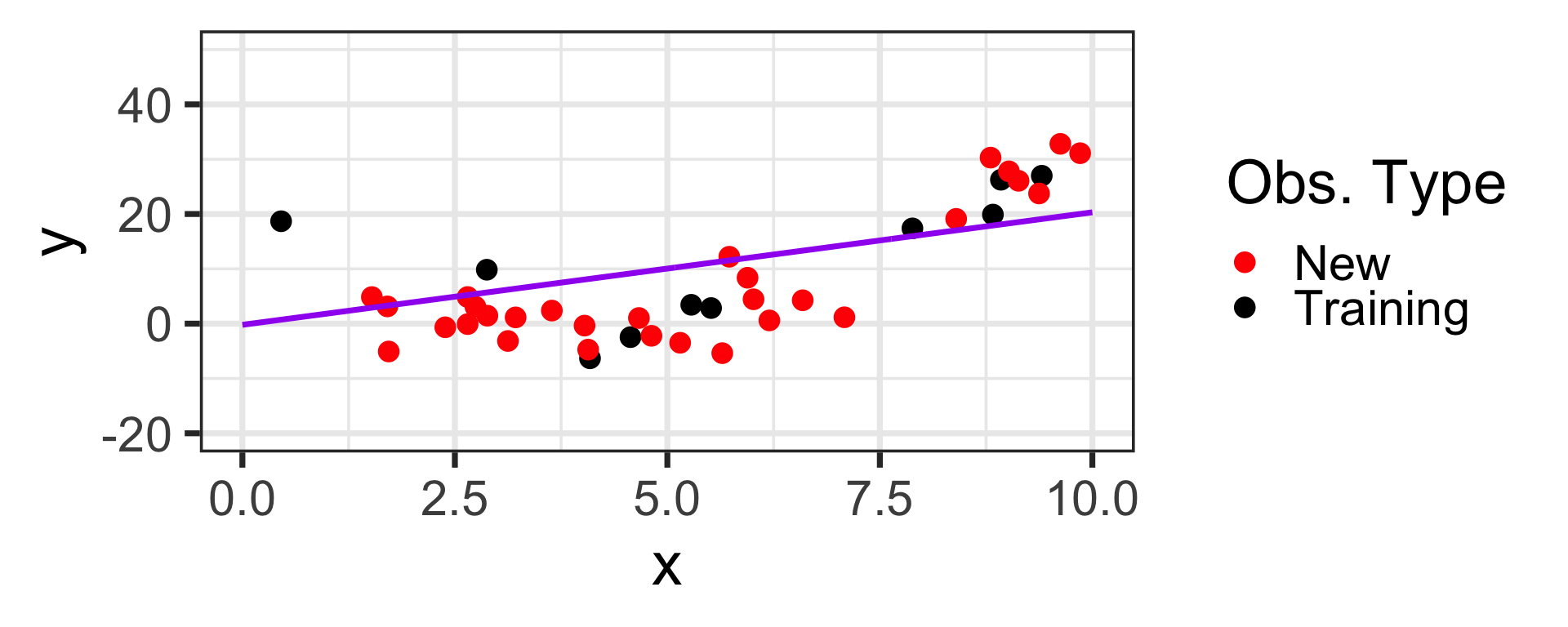
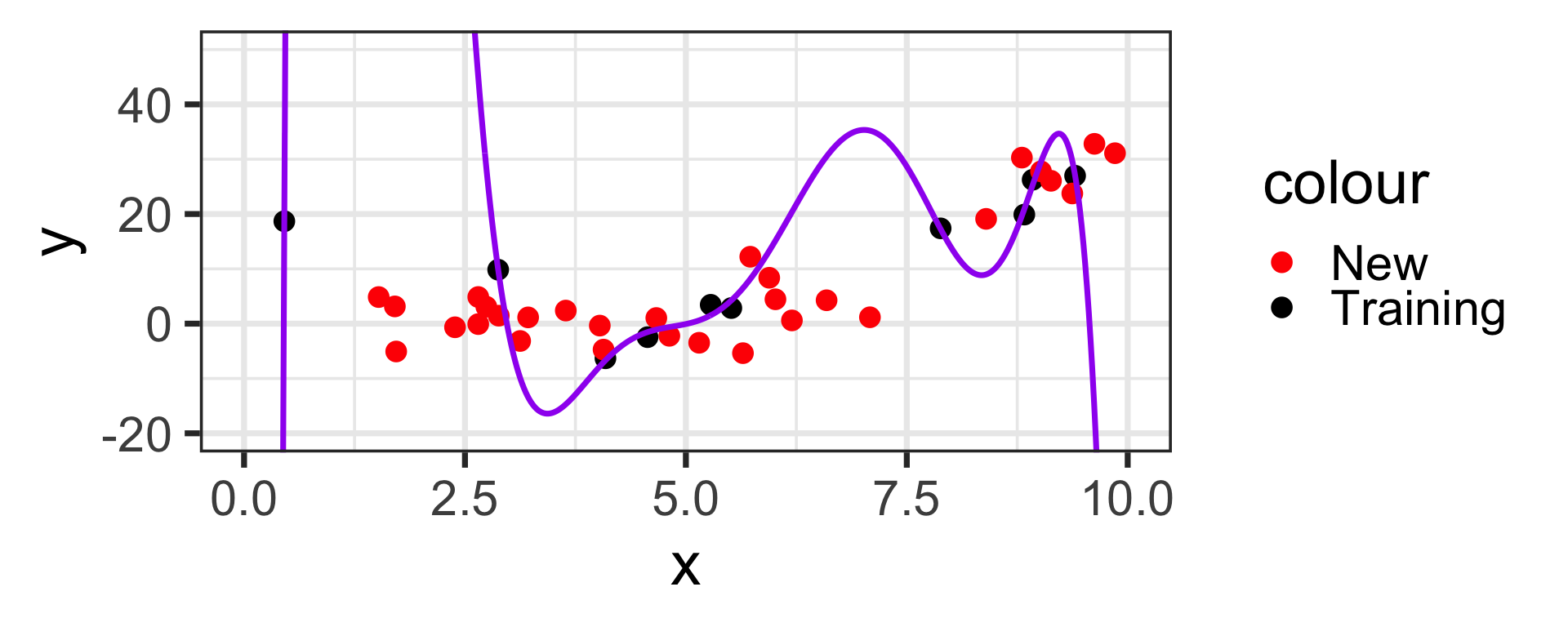
Underfit!
Overfit!
bias too high, variance too low
bias too low, variance to high
Not flexible enough
Too flexible
Training Error, Test Error, and Solving the Bias/Variance TradeOff Problem
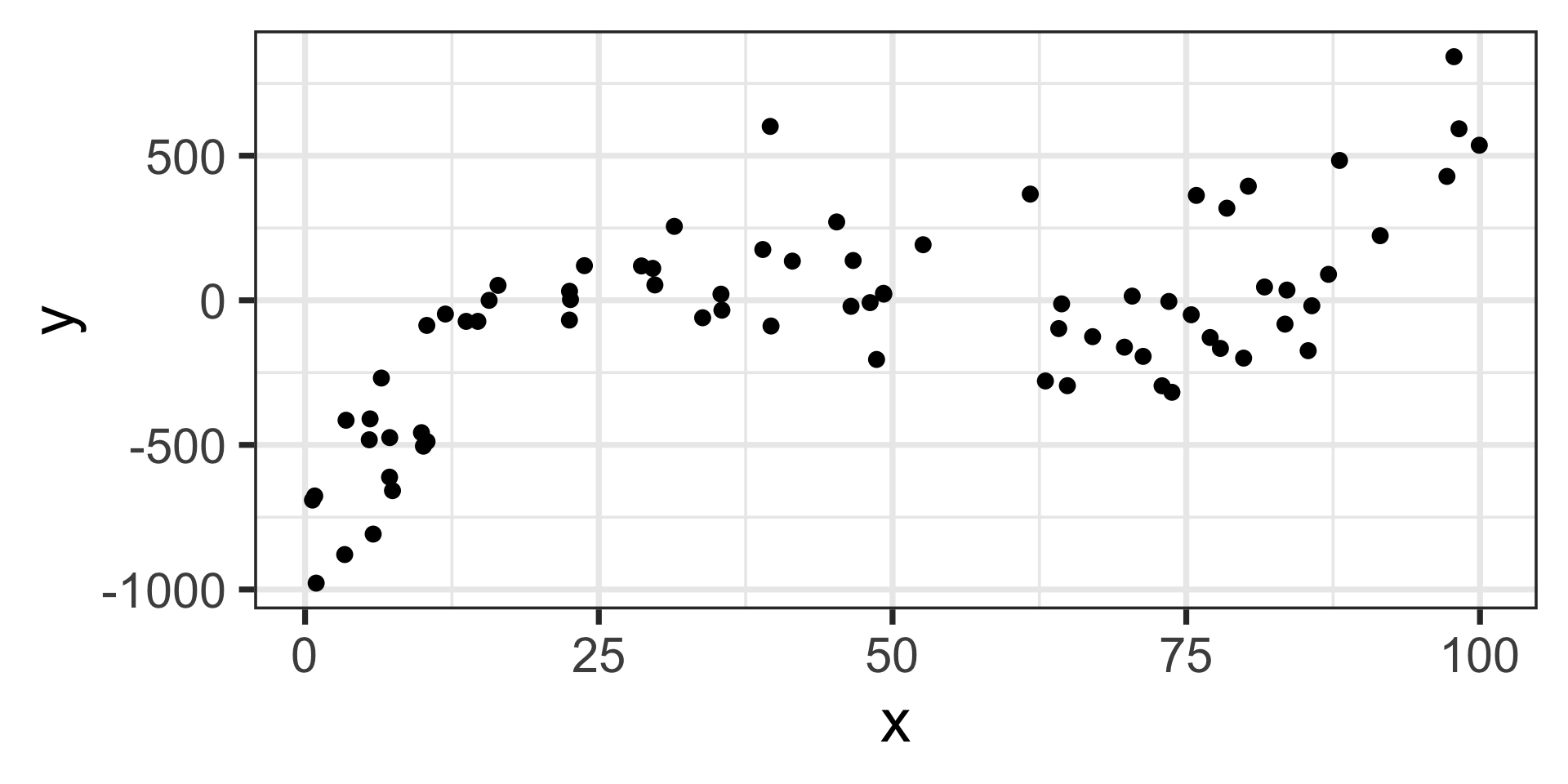
Let’s start with a new data set, but I won’t tell you what degree association there is between \(x\) and \(y\)
Training Error, Test Error, and Solving the Bias/Variance TradeOff Problem
Here they are…
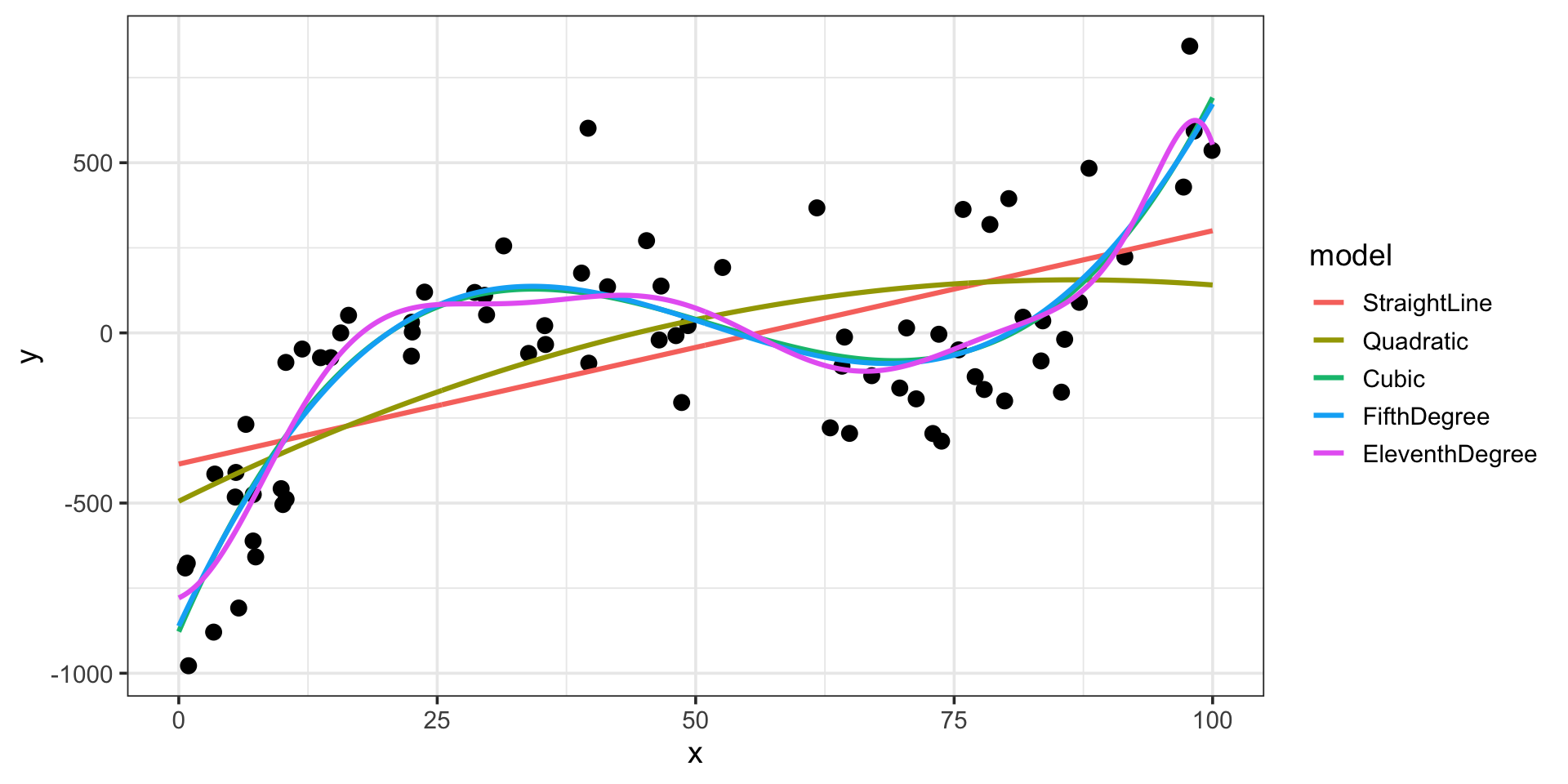
Training Error, Test Error, and Solving the Bias/Variance TradeOff Problem
Let’s examine the training metrics
| model | degree | rsq | rmse |
|---|---|---|---|
| straight-line | 1 | 0.3729797 | 274.3429 |
| quadratic | 2 | 0.4081391 | 266.5402 |
| cubic | 3 | 0.7299959 | 180.0272 |
| 5th-Order | 5 | 0.7304174 | 179.8866 |
| 11th-order | 11 | 0.7404520 | 176.5070 |
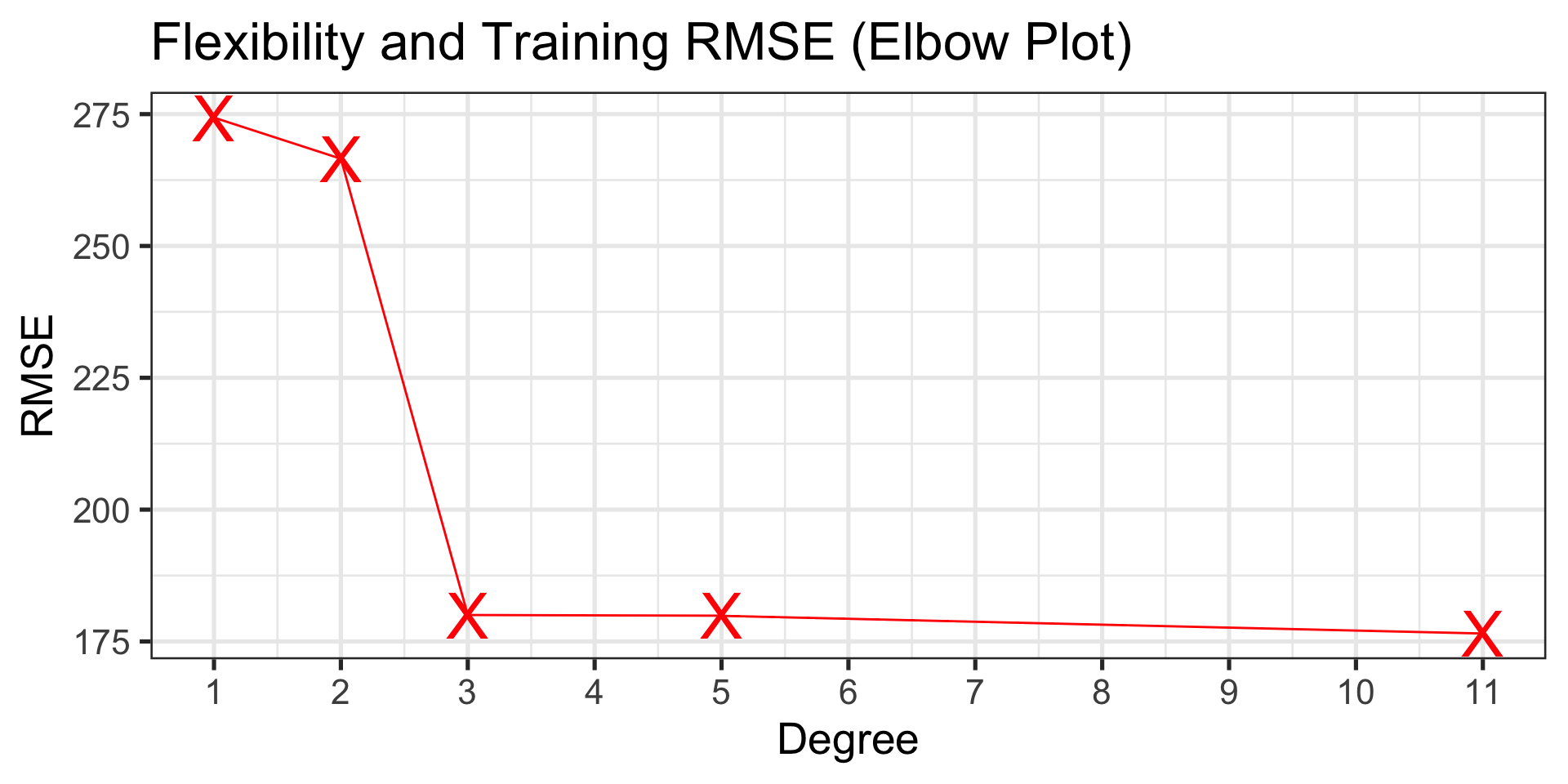
Performance gets better as flexibility increases!
Training Error, Test Error, and Solving the Bias/Variance TradeOff Problem
Let’s do the same with the test metrics
| model | degree | rsq | rmse |
|---|---|---|---|
| straight-line | 1 | 0.3045938 | 296.2297 |
| quadratic | 2 | 0.2931054 | 291.3515 |
| cubic | 3 | 0.6266876 | 189.1693 |
| 5th-Order | 5 | 0.6205745 | 190.5977 |
| 11th-order | 11 | 0.5915634 | 196.9832 |
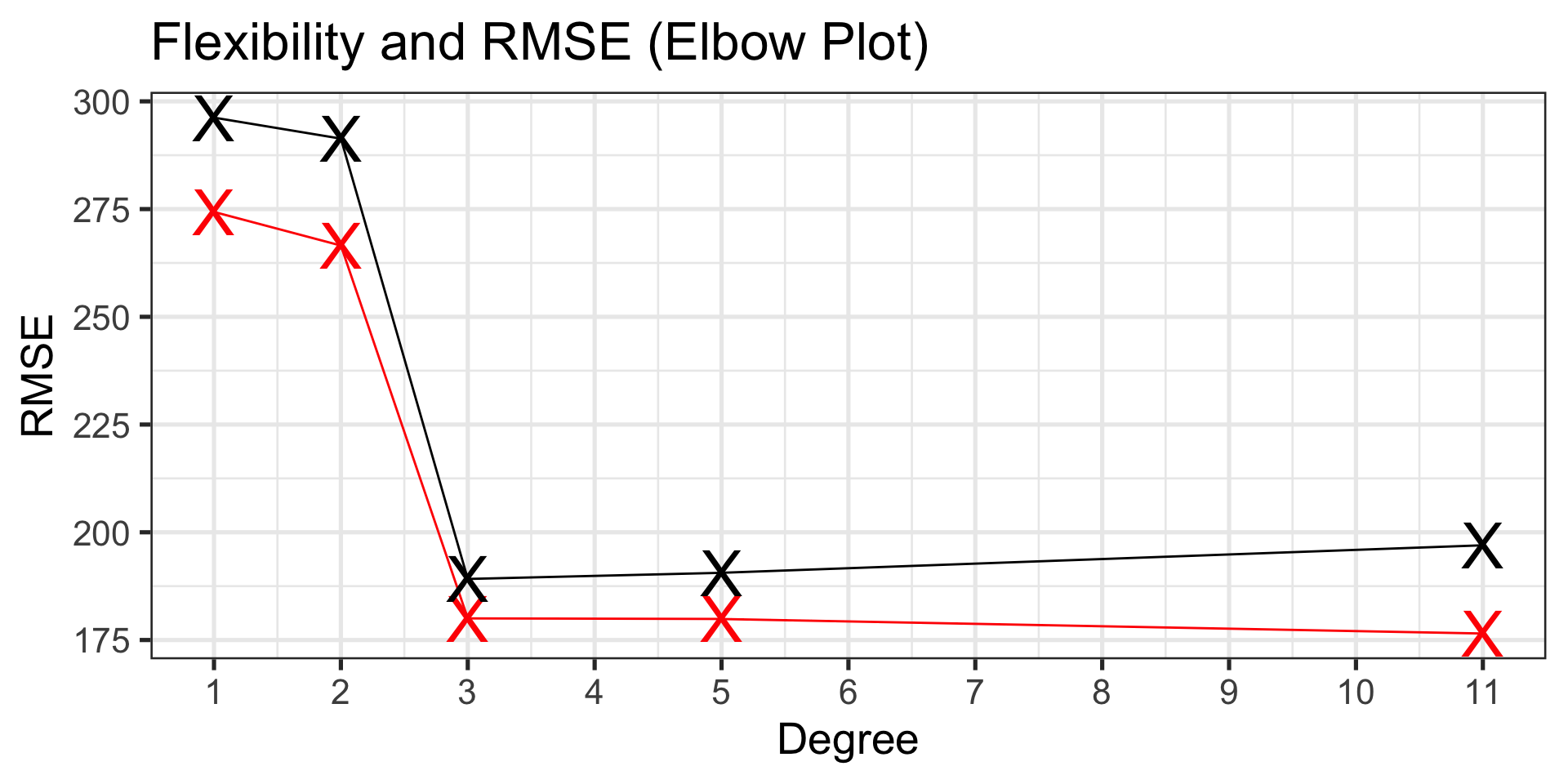
The training and test RMSE values largely agree over the lowest three levels of model flexibility, but…
Test performance gets worse with additional flexibility beyond third degree!
\(\bigstar \bigstar\) Main Takeaway \(\bigstar \bigstar\) The computer’s job is to find the best \(\beta\)-coefficients by minimizing training error, but our job (as modelers) is the find the best model by minimizing test error.