Topic 15: Hypothesis Tests and Confidence Intervals for Numerical Data
About
This activity introduces techniques for inference on a single population mean and for comparing two population means. The \(t\)-distributions are introduced, historical context is provided, and we work through two applications using federal sentencing data on drug-related convictions from the Southern District of New York State.
Note. The button above resets multiple choice and checkbox questions. Currently, resetting code cells must be done manually via hitting the Start Over button on each individual interactive cell.
Hypothesis Testing and Confidence Intervals for Numerical Data
In this activity, we continue our exploration of statistical inference. Through the past few activities you’ve become more comfortable with hypothesis testing and confidence intervals for categorical variables. Here we extend those frameworks to numerical variables. We’ll first be formally introduced to the family of \(t\)-distributions, and then work through a pair of applications to real criminal sentencing data.
As a reminder, the Standard Error Decision Tree, General Strategy for Conducting Hypothesis Tests, and General Strategy for Constructing Confidence Intervals are all available for reference. The walkthrough video for the decision tree is below, in case you’d like a refresher.
While watching the walkthrough video you probably noticed that the side of the decision tree corresponding to numerical data (inference for the mean, \(\mu\)) is more complex than the side for proportions. Much of this stems from the fact that using a sample standard deviation (\(s\)) as an approximation for the population standard deviation (\(\sigma\)) adds uncertainty to our estimate of the sampling distribution. To account for this added uncertainty, we utilize a class of penalized normal distributions called the \(t\)-distributions. Watch at least one of the introductory videos below.
A Detailed Introduction:
A Shorter Introduction:
What Does the \(t\)-Distribution Look Like?
The videos above have helped us identify scenarios where we should utilize a \(t\)-distribution instead of the standard normal (\(z\)) distribution. There is a simple rule to follow to help you decide which distribution to use: any time we use a sample standard deviation as a proxy for the population standard deviation in our estimate for the standard error, we should use a \(t\)-distribution.
The plot below shows the standard normal distribution in black, a \(t\)-distribution with 3 degrees of freedom in red, and a \(t\)-distribution with 12 degrees of freedom in blue.
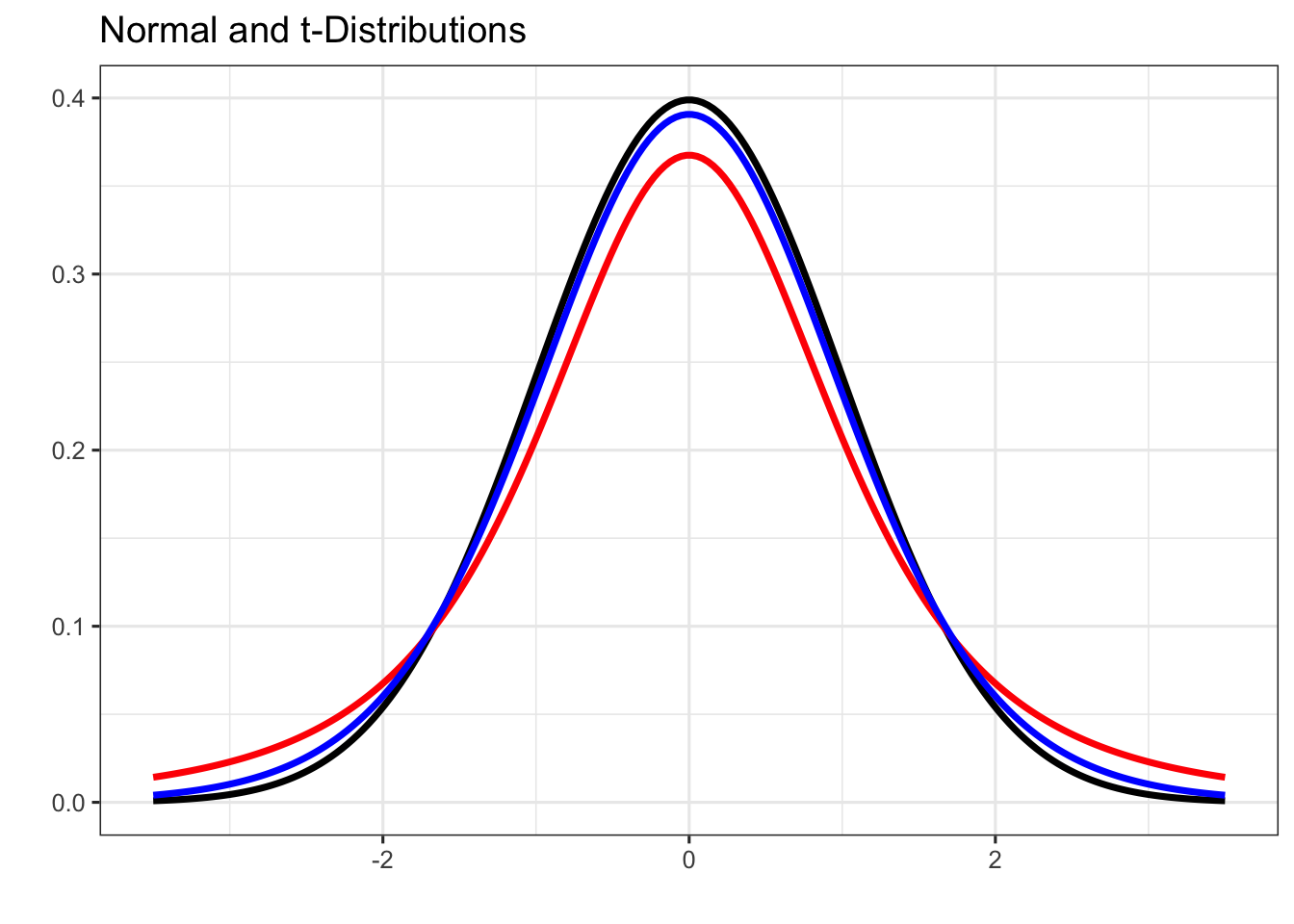
Notice that all three distributions are bell-shaped, but the \(t\)-distributions have fatter tails than the normal distribution. This means that the \(t\)-distributions have more area/probability in their tails than the standard normal distribution. Also notice that the \(t\)-distribution with 12 degrees of freedom is more similar to the standard normal distribution than the one with 3 degrees of freedom. As degrees of freedom increase, the \(t\)-distribution approaches (becomes more like) the normal distribution.
Using the \(t\)-Distributions
When we introduced the normal distribution, we identified two helper functions: pnorm() to find probabilities (areas to the left of a boundary value) and qnorm() to find percentiles (cutoff values/boundary values). We have analogous functions for the \(t\)-distribution:
pt(q, df)— finds the probability of a randomly chosen observation falling to the left of the boundary valueqin a \(t\)-distribution withdfdegrees of freedom.qt(p, df)— finds the cutoff value for which the area to the left of that cutoff in a \(t\)-distribution withdfdegrees of freedom isp.
Note that these functions have no mean or sd parameters — we always work with standardized variables (via the test statistic formula) when using the \(t\)-distributions.
Let’s practice. Don’t forget to draw pictures — you are much more likely to make mistakes if you skip this step.
Question 1: Find \(\mathbb{P}\left[t <\right.\) \(\left.\right]\) in a \(t\)-distribution with degrees of freedom.
Hint 1
Start by drawing a \(t\)-distribution centered at 0. Where does fall — to the left or right of center?
Hint 2
Shade the region to the left of your boundary value. Based on your picture, should your answer be larger or smaller than 0.5?
Hint 3
Use the pt() function. Its arguments are the boundary value and the degrees of freedom.
pt(___, df = ___)
Hint 4 (Solved)
The boundary value is and the degrees of freedom is . Fill in the first blank with and the second blank with .
pt(___, df = ___)
pt(boundary1, df = df1)
pt(boundary1, df = df1)Question 2: Find \(\mathbb{P}\left[t >\right.\) \(\left.\right]\) in a \(t\)-distribution with degrees of freedom.
Hint 1
Draw the \(t\)-distribution. Where does fall relative to 0?
Hint 2
We want the area to the right of the boundary value. What does pt() give us by default?
Hint 3
pt() gives the area to the left. To get the area to the right, subtract from 1.
1 - pt(___, df = ___)
Hint 4 (Solved)
The boundary value is and the degrees of freedom is . Fill in the first blank with and the second blank with .
1 - pt(___, df = ___)
1 - pt(boundary2, df = df2)
1 - pt(boundary2, df = df2)Question 3: Find the cutoff value in a \(t\)-distribution with degrees of freedom for which the area to the left of the cutoff is .
Hint 1
We are looking for a cutoff (boundary) value this time, rather than a probability. Which function does this — pt() or qt()?
Hint 2
Use qt() becasue we are looking for a boundary value. Draw a picture of the \(t\)-distribution with of the area shaded to the left. Should your cutoff value be positive or negative? How do you know?
Hint 3
Use qt() becasue we are looking for a boundary value. Draw a picture of the \(t\)-distribution with of the area shaded to the left. Should your cutoff value be positive or negative? How do you know?
Since a full half of this distribution contains an area of 0.5, the boundary value we seek must be above the middle of the distibution. Our boundary/cutoff value will be positive.
Hint 4
The qt() function takes the area to the left and the degrees of freedom as arguments.
qt(___, df = ___)
Hint 4 (Solved)
The area to the left is and the degrees of freedom is . Fill in the first blank with and the second blank with .
qt(___, df = ___)
qt(area3, df = df3)
qt(area3, df = df3)Question 4: Find the critical value associated with a % confidence interval using a \(t\)-distribution with degrees of freedom.
Hint 1
Draw a \(t\)-distribution. A % confidence interval captures the middle % of the distribution. How much area is left over for the two tails combined?
Hint 2
The remaining area is split equally between the two tails. How much area is in each tail?
Hint 3
The remaining area is split equally between the two tails. How much area is in each tail?
Each of the tails will contain an area of .
Hint 4
The critical value is the boundary value separating the upper tail from the rest of the distribution. What is the total area to the left of this boundary value?
Hint 5
The area to the left of the critical value is the lower tail area plus the middle area. Here that is + . Use qt() with this area and the degrees of freedom.
qt(___, df = ___)
Hint 6
Fill the first blank with , the total area to the left of the critical value.
qt(___, df = ___)
Hint 7 (Solved)
Fill the first blank with , the total area to the left of the critical value.
Fill in the second blank with , the degrees of freedom.
qt(___, df = ___)
qt(1 - (1 - clevel4/100)/2, df = df4)
qt(1 - (1 - clevel4/100)/2, df = df4)Applications to Criminal Sentencing
We’ll work with a dataset on Federal Sentencing from the Southern District of New York State. A subset of the data, consisting only of drug-related charges, has been loaded for you as SDNYdrug.
Task 1: Confidence Interval for Average Sentence Length
Construct a 95% confidence interval for the average sentence length for a drug-related conviction in the Southern District of New York State.
Check Your Understanding: Sentencing CI, Part I
To answer the question as asked, we should:
Use the code block below to compute the point estimate for average sentence length (SentenceMonths).
Hint 1
What summary statistic serves as the point estimate for a population mean?
Hint 2
Pipe the SDNYdrug data frame into summarize() and compute the mean of SentenceMonths.
SDNYdrug |>
summarize(___)
Hint 3 (Solved)
SDNYdrug |>
summarize(avg_sentence = mean(SentenceMonths))
SDNYdrug |>
summarize(avg_sentence = mean(SentenceMonths))
SDNYdrug |>
summarize(avg_sentence = mean(SentenceMonths))
Check Your Understanding: Sentencing CI, Part II
The standard error formula is:
Use the code block below to compute the standard error.
Hint 1
The standard error formula \(S_E = s/\sqrt{n}\) requires two quantities. What are they?
Hint 2
You need the sample standard deviation and the sample size. How would you find each from the SDNYdrug data frame?
Hint 3
One way is to start by piping SDNYdrug into summarize() again.
SDNYdrug |>
summarize(___)
Hint 4
One way is to start by piping SDNYdrug into summarize() again. We need the standard deviation and the number of observations.
SDNYdrug |>
summarize(
sd = ___,
n = ___)
Hint 5
One way is to start by piping SDNYdrug into summarize() again. We need the standard deviation and the number of observations.
- We can compute the standard deviation using the
sd()function. We’ll need to pass the column whose standard deviation we want into thesd()function. - Similarly, we can count the number of rows with the
n()function. Then()function takes no arguments.
SDNYdrug |>
summarize(
sd = sd(___),
n = n())
Hint 6
One way is to start by piping SDNYdrug into summarize() again. We need the standard deviation and the number of observations.
- We can compute the standard deviation using the
sd()function. We’ll need to passSentenceMonthstosd()in order to calculate its stanadard deviation. - Similarly, we can count the number of rows with the
n()function. Then()function takes no arguments.
SDNYdrug |>
summarize(
sd = sd(SentenceMonths),
n = n())
Hint 7 (Solved)
Now that you have the standard deviation and number of observations, you can compute the standard error. Carry out the arithmetic in a new line, dividing the discovered standard deviation by the square root of the sample size.
SDNYdrug |>
summarize(
sd = sd(SentenceMonths),
n = n())
___ / sqrt(___)
sd(SDNYdrug$SentenceMonths) / sqrt(nrow(SDNYdrug))
sd(SDNYdrug$SentenceMonths) / sqrt(nrow(SDNYdrug))
Check Your Understanding: Sentencing CI, Part III
The distribution to be used is:
Check Your Understanding: Sentencing CI, Part IV
The desired level of confidence is:
Use the code block below to compute the critical value for the confidence interval.
Hint 1
You’ll use qt() here. What is the area to the left of the critical value for a 95% confidence interval?
Hint 2
For a 95% confidence interval, we capture 95% of the area in the center of the distribution. How much area remains in each of the two tails?
qt(___, df = ___)
Hint 3
For a 95% confidence interval, the two tails together hold 5% of the area, so each tail holds 2.5%.
qt(___, df = ___)
Hint 4
The critical value is the boundary/cutoff for the upper tail. How much of the area in the distribution falls below that upper tail?
qt(___, df = ___)
Hint 5
The critical value is the boundary/cutoff for the upper tail. How much of the area in the distribution falls below that upper tail?
The total area to the left includes the lower-tail area (0.025) plus the middle area (0.95).
qt(___, df = ___)
Hint 6
The critical value is the boundary/cutoff for the upper tail. How much of the area in the distribution falls below that upper tail?
The total area to the left includes the lower-tail area (0.025) plus the middle area (0.95). Replace the first blank with 0.025 + 0.95 or, more simply, 0.975.
qt(0.025 + 0.95, df = ___)
Hint 7
The critical value is the boundary/cutoff for the upper tail. How much of the area in the distribution falls below that upper tail?
The second blank is filled in by the degrees of freedom. Here, that’s one less than the number of observations we have.
qt(0.025 + 0.95, df = ___)
Hint 7 (Solved)
The critical value is the boundary/cutoff for the upper tail. How much of the area in the distribution falls below that upper tail?
The second blank is filled in by the degrees of freedom. Here, that’s one less than the number of observations we have. We have 280 observations, so fill the second blank with 280 - 1 or, more simply, by 279.
qt(0.025 + 0.95, df = 280 - 1)
qt(0.975, df = nrow(SDNYdrug) - 1)
qt(0.975, df = nrow(SDNYdrug) - 1)
A Note on the Critical Value
With so many observations, the correct critical value differed very little from 1.96 (the value obtained from the normal distribution). Remember that the critical values on the Standard Error Decision Tree are for the normal distribution only. Any time we use a sample standard deviation as a stand-in for the population standard deviation, we should use qt() — this will make a larger difference when sample sizes are smaller.
Use the code block below to compute the lower bound of the 95% confidence interval.
Hint 1
The formula for a confidence interval is: \((\text{point estimate}) \pm (\text{critical value}) \times S_E\). For the lower bound, which operation do you use?
Hint 2
For the lower bound, subtract the margin of error from the point estimate.
___ - (___ * ___)
Hint 3
You calculated all of these values in earlier code cells.
- The point estimate (the sample average sentence length) was about 42.75 months.
- The critical value is about 1.97.
- The standard error is about 3.22 months.
___ - (___ * ___)
Hint 4
You calculated all of these values in earlier code cells.
- The point estimate (the sample average sentence length) was about 42.75 months.
- The critical value is about 1.97.
- The standard error is about 3.22 months.
Fill the first blank with your point estimate. It is your best guess at the location of the population parameter.
42.75 - (___ * ___)
Hint 5
You calculated all of these values in earlier code cells.
- The point estimate (the sample average sentence length) was about 42.75 months.
- The critical value is about 1.97.
- The standard error is about 3.22 months.
Fill the second blank with your critical value. This is the number of standard errors above or below the point estimate you’ll need to extend in order to capture the parameter with your desired level of confidence.
42.75 - (1.97 * ___)
Hint 6 (Solved)
You calculated all of these values in earlier code cells.
- The point estimate (the sample average sentence length) was about 42.75 months.
- The critical value is about 1.97.
- The standard error is about 3.22 months.
Fill the final blank with your standard error. This measures the typical amount of sampling variability we should expect in our point estimates from one sample to the next.
42.75 - (1.97 * 3.22)
mean(SDNYdrug$SentenceMonths) -
qt(0.975, df = nrow(SDNYdrug) - 1) *
(sd(SDNYdrug$SentenceMonths) / sqrt(nrow(SDNYdrug)))
mean(SDNYdrug$SentenceMonths) -
qt(0.975, df = nrow(SDNYdrug) - 1) *
(sd(SDNYdrug$SentenceMonths) / sqrt(nrow(SDNYdrug)))Use the code block below to compute the upper bound of the 95% confidence interval.
Hint 1
This is done the same way as finding the lower bound — just swap subtraction for addition.
Hint 2 (Solved)
42.75 + (1.97 * 3.22)
mean(SDNYdrug$SentenceMonths) +
qt(0.975, df = nrow(SDNYdrug) - 1) *
(sd(SDNYdrug$SentenceMonths) / sqrt(nrow(SDNYdrug)))
mean(SDNYdrug$SentenceMonths) +
qt(0.975, df = nrow(SDNYdrug) - 1) *
(sd(SDNYdrug$SentenceMonths) / sqrt(nrow(SDNYdrug)))
Check Your Understanding: Sentencing CI, Part V
Which of the following is the correct interpretation of this confidence interval?
Check Your Understanding: Sentencing CI, Part VI
Does this sample provide evidence to suggest that the average sentence length for drug-related charges in the Southern District of New York State exceeds three years (36 months)?
Task 2: Hypothesis Test for Difference in Sentence Lengths
Conduct a hypothesis test at the \(\alpha = 0.10\) level of significance to determine whether the sample data provides significant evidence that the average sentence length for white offenders and the average sentence length for non-white offenders differs for drug-related cases in the Southern District of New York State.
Check Your Understanding: Sentencing HT, Part I
To answer the question as asked, we should:
Check Your Understanding: Sentencing HT, Part II
What is the level of significance associated with this test?
Check Your Understanding: Sentencing HT, Part III
Does this hypothesis test involve testing a statement about a mean (\(\mu\)), a proportion (\(p\)), or something else?
Check Your Understanding: Sentencing HT, Part IV
How many groups are being compared in this test?
Check Your Understanding: Sentencing HT, Part V
Which of the following are the hypotheses associated with this test?
Check Your Understanding: Sentencing HT VI
Do we know the population standard deviations (\(\sigma\)) for sentence lengths in each group?
Check Your Understanding: Sentencing HT, Part VII
Are the observations in the two groups (sentences handed to white offenders and sentences handed to non-white offenders) paired?
Check Your Understanding: Sentencing HT, Part VIII
Which standard error formula should be used?
Check Your Understanding: Sentencing HT IX
Which distribution does the test statistic follow?
The sentence lengths for white offenders are stored in the vector whiteSentences and for non-white offenders in the vector nonWhiteSentences. Since these objects are not data frames, you can use functionality like mean(), sd(), and length() directly on them.
Use the code blocks below to compute the necessary quantities.
Number of white offenders:
Hint 1
whiteSentences is a vector, not a data frame. Which function counts elements in a vector?
Hint 2 (Solved)
Use length() rather than nrow() for vectors.
length(whiteSentences)
length(whiteSentences)
length(whiteSentences)Number of non-white offenders:
Hint 1 (Solved)
Use the same approach, but for nonWhiteSentences.
length(nonWhiteSentences)
length(nonWhiteSentences)
length(nonWhiteSentences)Average sentence length — white offenders:
Hint 1
Use the mean() function to calculate the average sentence length. What do you need to take the mean() of?
mean(___)
Hint 2 (Solved)
Use the mean() function applied to whiteSentences to calculate the average sentence length.
mean(whiteSentences)
mean(whiteSentences)
mean(whiteSentences)Average sentence length — non-white offenders:
Hint 1 (Solved)
Just like with the previous scenario, use the mean() function to calculate the average sentence length. This time, apply it to nonWhiteSentences though.
mean(nonWhiteSentences)
mean(nonWhiteSentences)
mean(nonWhiteSentences)Standard deviation in sentence lengths — white offenders:
Hint 1
Remember that you can calculate the standard deviation with the sd() function.
sd(___)
Hint 2 (Solved)
Apply the sd() function to your collection of whiteSentences.
sd(whiteSentences)
sd(whiteSentences)
sd(whiteSentences)Standard deviation in sentence lengths — non-white offenders:
Hint 1 (Solved)
Use the same approach. Apply the sd() function to nonWhiteSentences.
sd(nonWhiteSentences)
sd(nonWhiteSentences)
sd(nonWhiteSentences)Now let’s put the pieces together.
Check Your Understanding: Sentencing HT, Part X
The population parameter in question for this hypothesis test is:
Check Your Understanding: Sentencing HT, Part XI
The null value is:
Point estimate:
Hint 1
The population parameter is \(\mu_{\text{white}} - \mu_{\text{non-white}}\). The form of the parameter tells you how to calculate the point estimate.
Hint 2 (Solved)
The point estimate is the sample “version” of the parameter — subtract the mean sentence for non-white offenders from the mean sentence for white offenders, or vice-versa.
mean(whiteSentences) - mean(nonWhiteSentences)
mean(whiteSentences) - mean(nonWhiteSentences)
mean(whiteSentences) - mean(nonWhiteSentences)Standard error:
Hint 1
You identified the standard error formula earlier: \(S_E = \sqrt{\left(s_1^2 / n_1\right) + \left(s_2^2 / n_2\right)}\). What are the four quantities you need?
Hint 2
You’ve already computed all four quantities. Fill in the blanks:
sqrt((___^2 / ___) + (___^2 / ___))
Hint 3
The first grouping corresponds to the whiteSentences. We’ll fill in the first blank with the standard deviation for that group and the second blank with the number of observations from that group.
sqrt((36.53^2 / 37) + (___^2 / ___))
Hint 4 (Solved)
Similarly, we’ll fill in the remaining blanks with the standard deviation and number of observations from the nonWhiteSentences.
sqrt((36.53^2 / 37) + (55.88^2 / 243))
sqrt((sd(whiteSentences)^2 / length(whiteSentences)) +
(sd(nonWhiteSentences)^2 / length(nonWhiteSentences)))
sqrt((sd(whiteSentences)^2 / length(whiteSentences)) +
(sd(nonWhiteSentences)^2 / length(nonWhiteSentences)))Test statistic:
Hint 1
The test statistic formula is \(\displaystyle{\text{test statistic} = \frac{(\text{point estimate}) - (\text{null value})}{S_E}}\). You have all three components.
(___ - ___) / ___
Hint 2
The test statistic formula is \(\displaystyle{\text{test statistic} = \frac{(\text{point estimate}) - (\text{null value})}{S_E}}\). You have all three components.
From the earlier exercises, we know that:
- the point estimate is about -14.92 months, the difference in average sentences lengths.
(-14.92 - ___)/___
Hint 3
The test statistic formula is \(\displaystyle{\text{test statistic} = \frac{(\text{point estimate}) - (\text{null value})}{S_E}}\). You have all three components.
From the earlier exercises, we know that:
- the point estimate is about -14.92 months, the difference in average sentences lengths.
- The null value is 0, the expected difference in average sentence lengths if no difference in the population average sentences exists.
(-14.92 - 0)/___
Hint 4 (Solved)
The test statistic formula is \(\displaystyle{\text{test statistic} = \frac{(\text{point estimate}) - (\text{null value})}{S_E}}\). You have all three components.
From the earlier exercises, we know that:
- the point estimate is about -14.92 months, the difference in average sentences lengths.
- The null value is 0, the expected difference in average sentence lengths if no difference in the population average sentences exists.
- The standard error is about 6.99 months.
(-14.92 - 0)/6.99
se <- sqrt((sd(whiteSentences)^2 / length(whiteSentences)) +
(sd(nonWhiteSentences)^2 / length(nonWhiteSentences)))
(mean(whiteSentences) - mean(nonWhiteSentences)) / se
se <- sqrt((sd(whiteSentences)^2 / length(whiteSentences)) +
(sd(nonWhiteSentences)^2 / length(nonWhiteSentences)))
(mean(whiteSentences) - mean(nonWhiteSentences)) / seDegrees of freedom:
Hint 1
For a two-sample \(t\)-test, the degrees of freedom depends on the sizes of the two samples. Which formula applies?
Hint 2
We use \(\text{df} = \min\left(n_1 - 1, n_2 - 1\right)\), one less than the smaller of the two sample sizes.
Hint 3
We use \(\text{df} = \min\left(n_1 - 1, n_2 - 1\right)\), one less than the smaller of the two sample sizes.
Which sample was smaller – whiteSentences or nonWhiteSentences?
Hint 4 (Solved)
We use \(\text{df} = \min\left(n_1 - 1, n_2 - 1\right)\), one less than the smaller of the two sample sizes.
Which sample was smaller – whiteSentences or nonWhiteSentences?
There were only 37 observations in whiteSentences and there were 243 in nonWhiteSentences. Because of this, use 36 for the degrees of freedom.
min(length(whiteSentences), length(nonWhiteSentences)) - 1
min(length(whiteSentences), length(nonWhiteSentences)) - 1\(p\)-value:
Hint 1
Draw a picture of the \(t\)-distribution with your test statistic marked. Since the alternative hypothesis is two-sided (\(\neq\)), which regions correspond to the \(p\)-value?
Hint 2
Both tails are shaded for a two-sided test. Since both tails are equal in size, you can find one tail area and double it.
2*p???(___)
Hint 3
Which of the p*() functions should we use here? We’ve encountered several…pbinom(), pnorm(), pchisq(), and pt().
2*p???(___)
Hint 4
Since we’re working with a \(t\)-distribution, we’ll use pt().
2*pt(___, df = ___)
Hint 5
Because the test statistic is negative, pt() will calculate the area in the lower tail. Doubling this area will give us our \(p\)-value, as mentioned earlier.
2*pt(___, df = ___)
Hint 6 (Solved)
Our test statistic of about -2.13 will occupy the first blank, while our degrees of freedom (36) will occupy the second.
2*pt(-2.13, df = 36)
se <- sqrt((sd(whiteSentences)^2 / length(whiteSentences)) +
(sd(nonWhiteSentences)^2 / length(nonWhiteSentences)))
ts <- (mean(whiteSentences) - mean(nonWhiteSentences)) / se
df <- min(length(whiteSentences), length(nonWhiteSentences)) - 1
2 * (1 - pt(abs(ts), df = df))
se <- sqrt((sd(whiteSentences)^2 / length(whiteSentences)) +
(sd(nonWhiteSentences)^2 / length(nonWhiteSentences)))
ts <- (mean(whiteSentences) - mean(nonWhiteSentences)) / se
df <- min(length(whiteSentences), length(nonWhiteSentences)) - 1
2 * (1 - pt(abs(ts), df = df))
Check Your Understanding: Sentencing HT XII
What is the result of the test?
Check Your Understanding: Sentencing HT XIII
The result of the test means that:
Check Your Understanding: Sentencing HT XIV
Which of the following is an appropriate implication of our result?
Submit
If you are part of a course with an instructor who is grading your work on these activities, please copy and submit both of the hashes below using the method your instructor has requested.
Question Hash
The hash below encodes your responses to the multiple choice questions in this activity.
Exercise Hash
Click the button below to generate your exercise submission code. This hash encodes your work on the graded code exercises in this activity.
You must have attempted the graded exercises before clicking — clicking generates a snapshot of your current results. If you have completed the activity over multiple sessions, please go back through and hit the Run Code button on each graded exercise before generating the hash below, to ensure your most recent results are recorded.
Summary
Great work through all of that — and I hope you found the application to sentencing data in the SDNY both interesting and thought-provoking. The problems were scaffolded step-by-step deliberately, to help you see how each individual piece connects to the larger process of conducting inference with numerical data.
Main Takeaways
- The \(t\)-distributions are a family of penalized normal distributions parameterized by degrees of freedom. As degrees of freedom increase, the \(t\)-distribution becomes closer to the normal distribution.
- Use the \(t\)-distribution any time you use a sample standard deviation (\(s\)) as a substitute for the population standard deviation (\(\sigma\)) in the standard error formula. The functions
pt()andqt()work exactly likepnorm()andqnorm(), but for the \(t\)-distribution. - For a single mean, the standard error is \(S_E = s/\sqrt{n}\) and the degrees of freedom is \(n - 1\).
- For comparing two independent means, the standard error is \(S_E = \sqrt{s_1^2/n_1 + s_2^2/n_2}\) and the degrees of freedom is \(\min\{n_1 - 1, n_2 - 1\}\).
- The confidence interval and hypothesis test formulas are the same as before — what changes is the standard error formula and the distribution used for the critical value or \(p\)-value.
- Statistical significance does not imply proof. Our finding of a significant difference in sentence lengths is evidence that warrants further investigation — it does not prove racial bias, nor does it tell us the direction of the difference without examining the point estimate.
Looking Ahead
You’ve now completed the core statistical inference toolkit — confidence intervals and hypothesis tests for proportions, differences in proportions, means, and differences in means. In the coming activities, you’ll have the opportunity to practice applying these tools across a variety of mixed scenarios, building fluency in selecting the right method for each situation. The decision tree and general strategy documents will continue to be your primary guides.