Introduction to Inference: The Central Limit Theorem
March 4, 2026
Probability and the Normal Distribution (A Reminder)
A normal distribution is defined by its mean (\(\mu\)) and standard deviation (\(\sigma\))
- The mean, \(\mu\), is the center of the distribution
- The standard deviation, \(\sigma\), governs the spread of the distribution – a larger \(\sigma\) means a wider distribution, while a smaller \(\sigma\) means a more narrow distribution
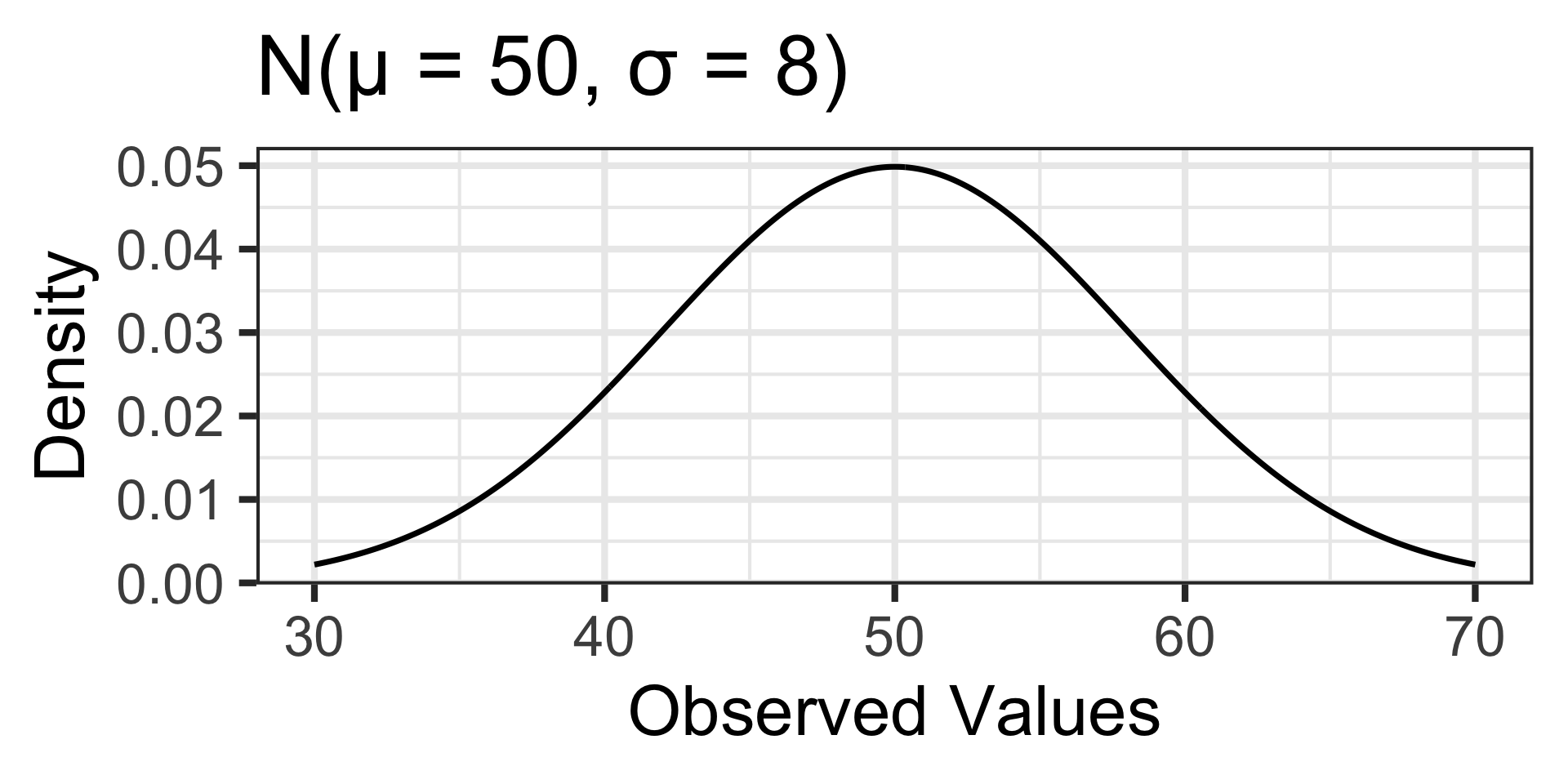
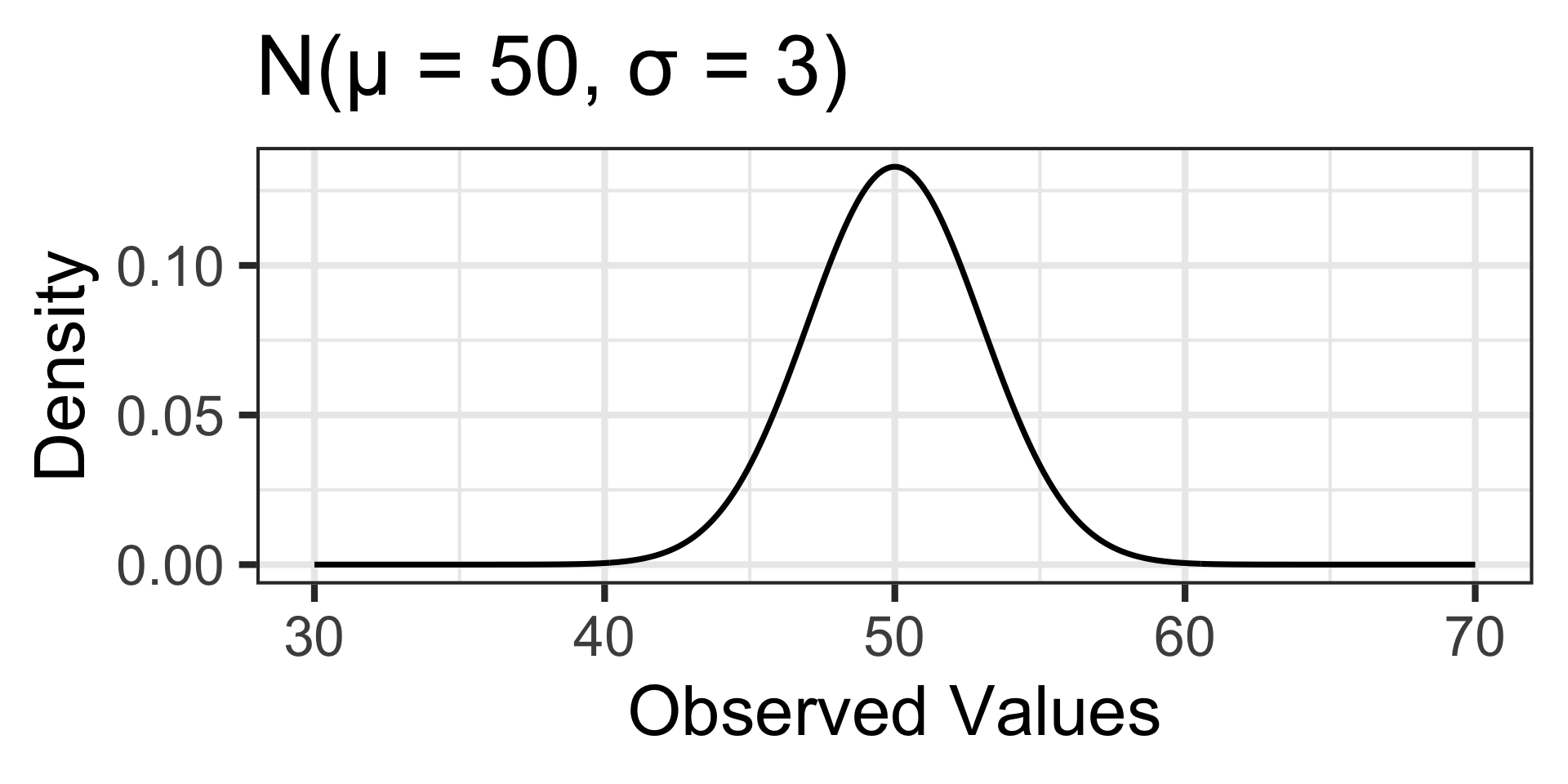
Probabilities associated with values far away from the mean are larger in the distribution on the left than they are in the distribution on the right.
Probability and the Normal Distribution (A Reminder)
Probabilities associated with values far away from the mean are larger in the distribution on the left than they are in the distribution on the right.
\(\mathbb{P}\left[X < 45\right] \approx ...\)
\(\mathbb{P}\left[X < 45\right] \approx ...\)
Probability and the Normal Distribution (A Reminder)
Probabilities associated with values far away from the mean are larger in the distribution on the left than they are in the distribution on the right.
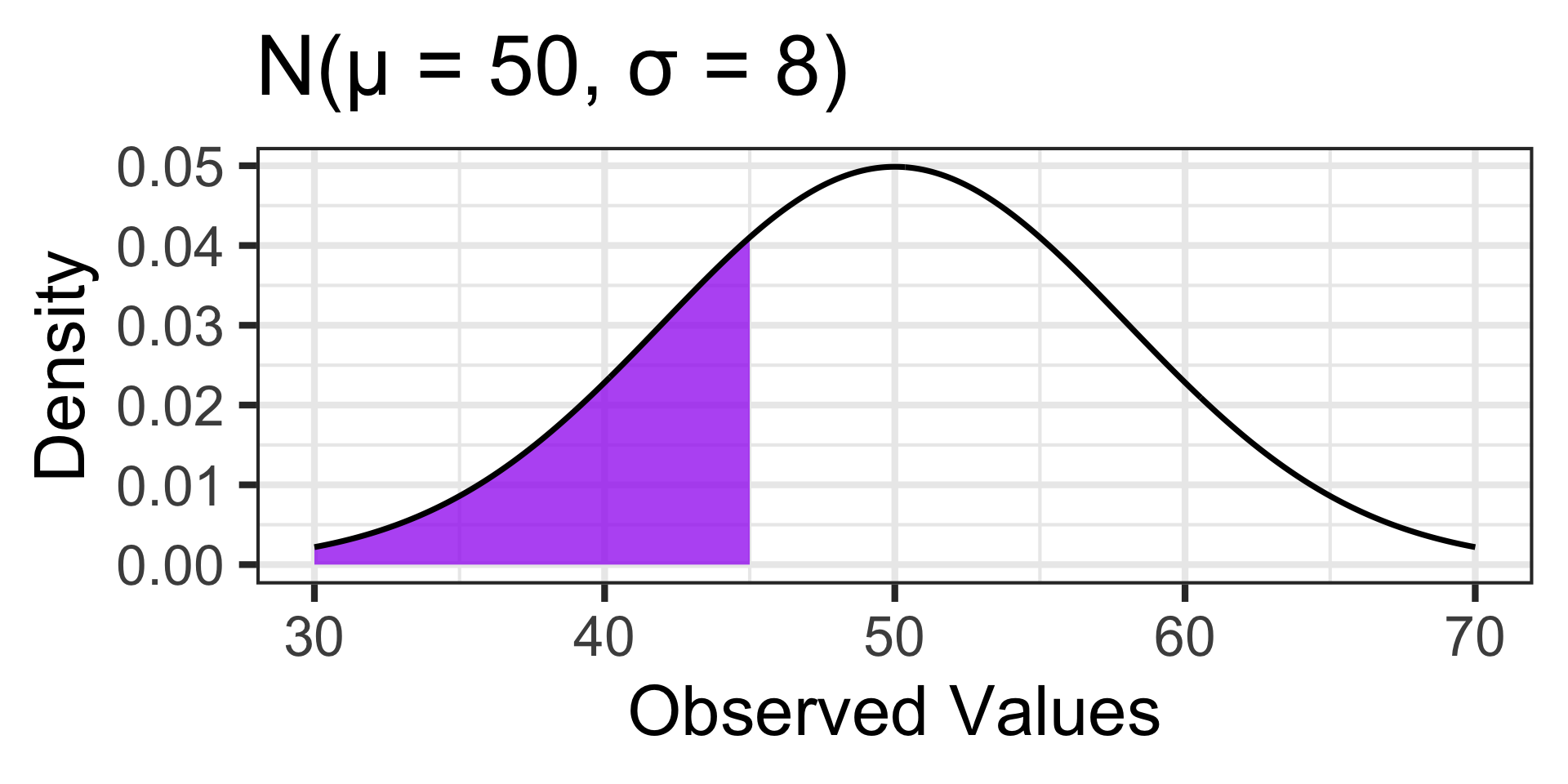
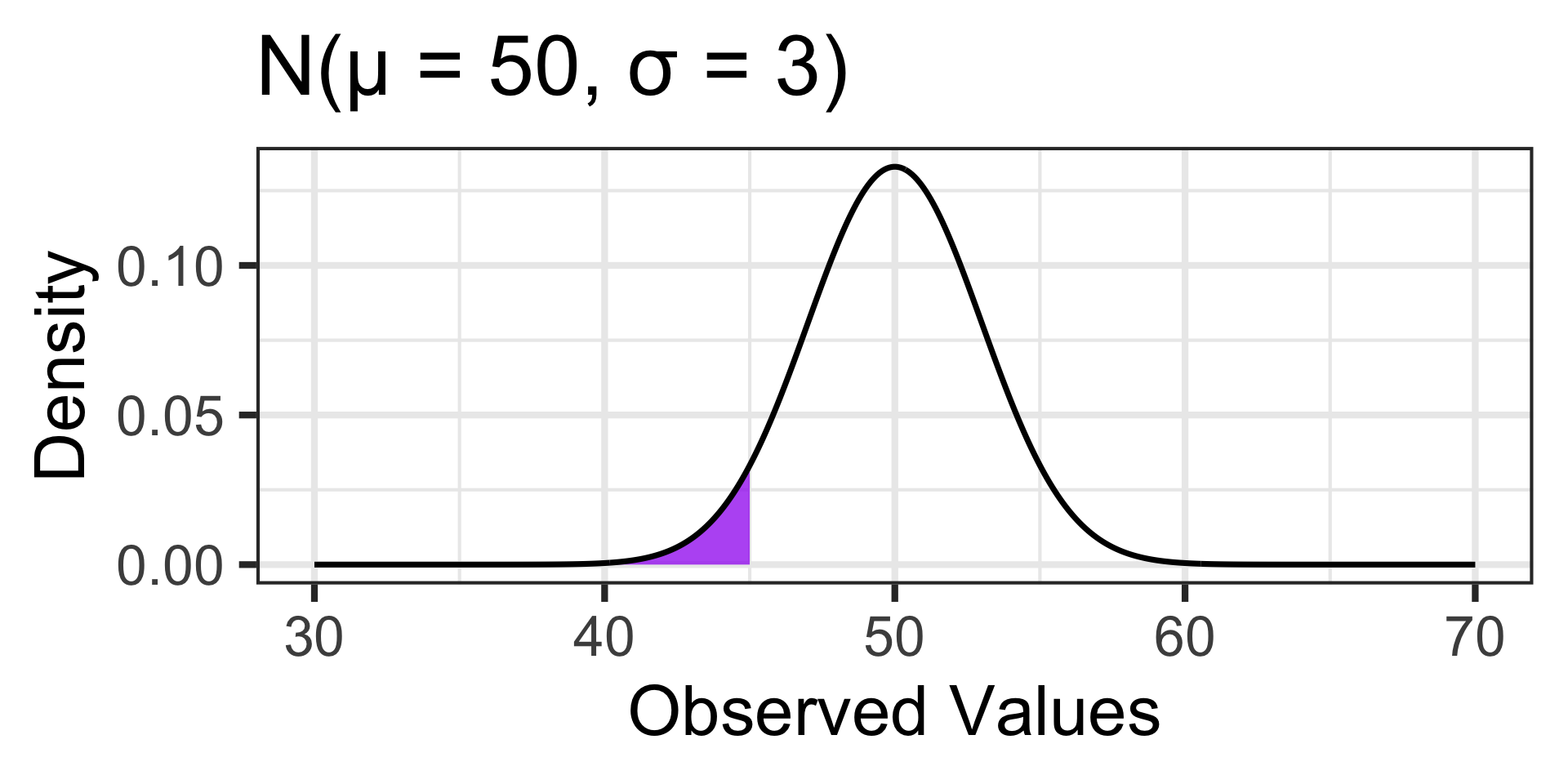
\(\mathbb{P}\left[X < 45\right] \approx ...\)
\(\mathbb{P}\left[X < 45\right] \approx ...\)
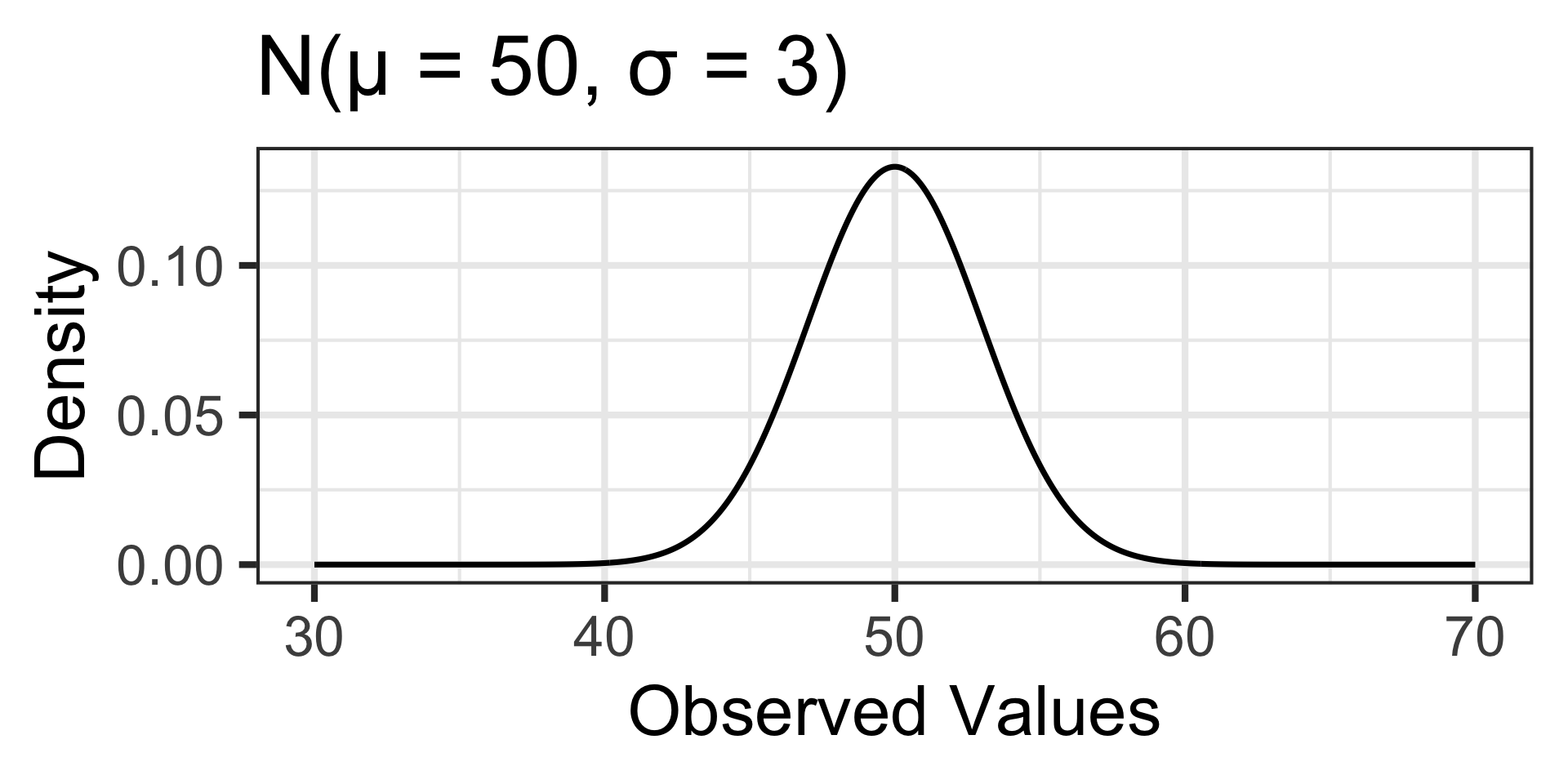
pnorm(45, 50, 8) \(\approx\) 0.266
pnorm(45, 50, 3) \(\approx\) 0.0478
Probability and the Normal Distribution (A Reminder)
Probabilities associated with values far away from the mean are larger in the distribution on the left than they are in the distribution on the right.
\(\mathbb{P}\left[X \geq 60\right] \approx ...\)
\(\mathbb{P}\left[X \geq 60\right] \approx ...\)
Probability and the Normal Distribution (A Reminder)
Probabilities associated with values far away from the mean are larger in the distribution on the left than they are in the distribution on the right.
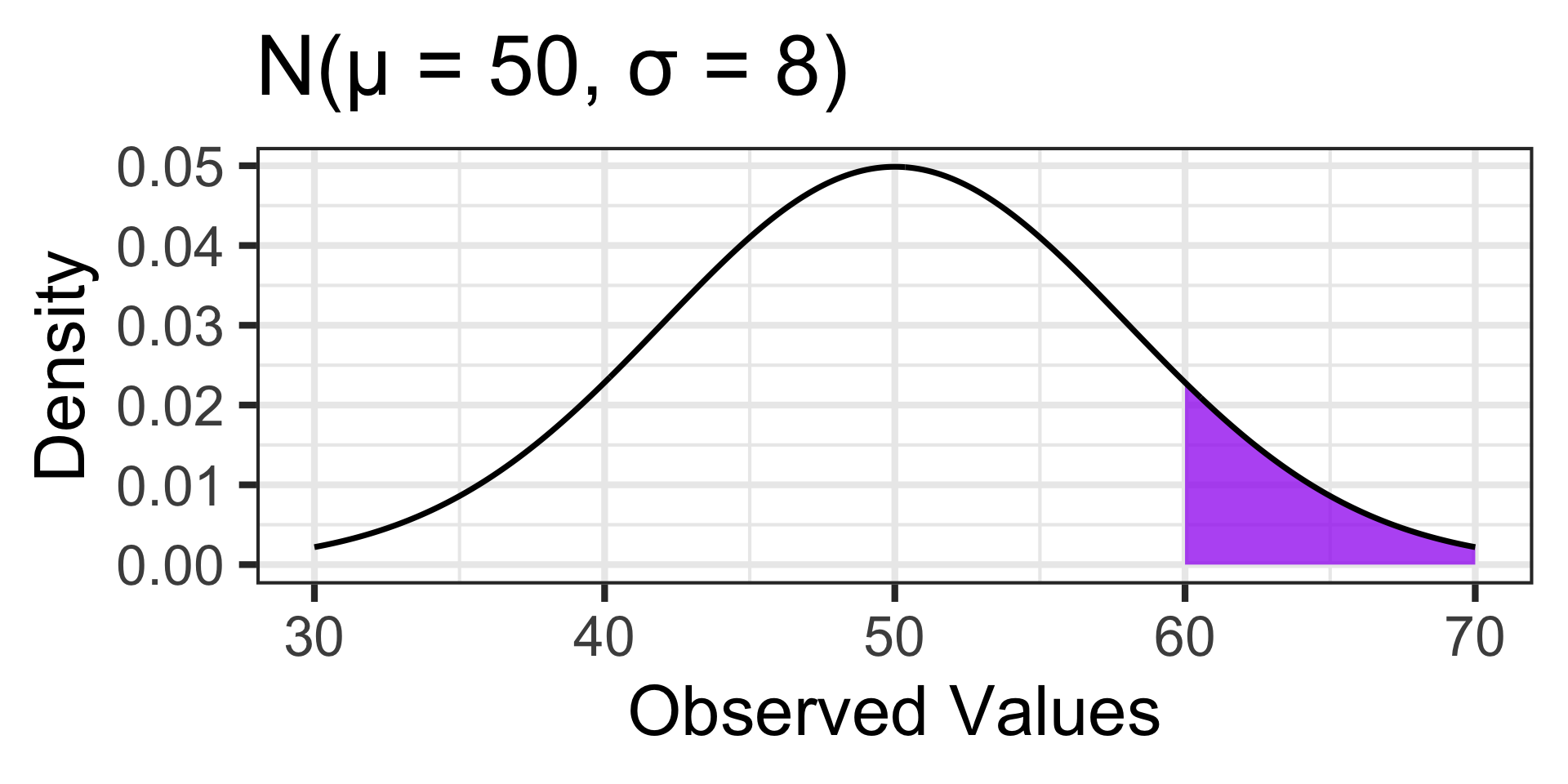
\(\mathbb{P}\left[X \geq 60\right] \approx ...\)
\(\mathbb{P}\left[X \geq 60\right] \approx ...\)
1 - pnorm(60, 50, 8) \(\approx\) 0.1056
1 - pnorm(60, 50, 3) \(\approx\) 0.0004
Sampling One Observation at a Time (Population Distribution)
The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. Find the probability that a launched pumpkin exceeds 2000ft.
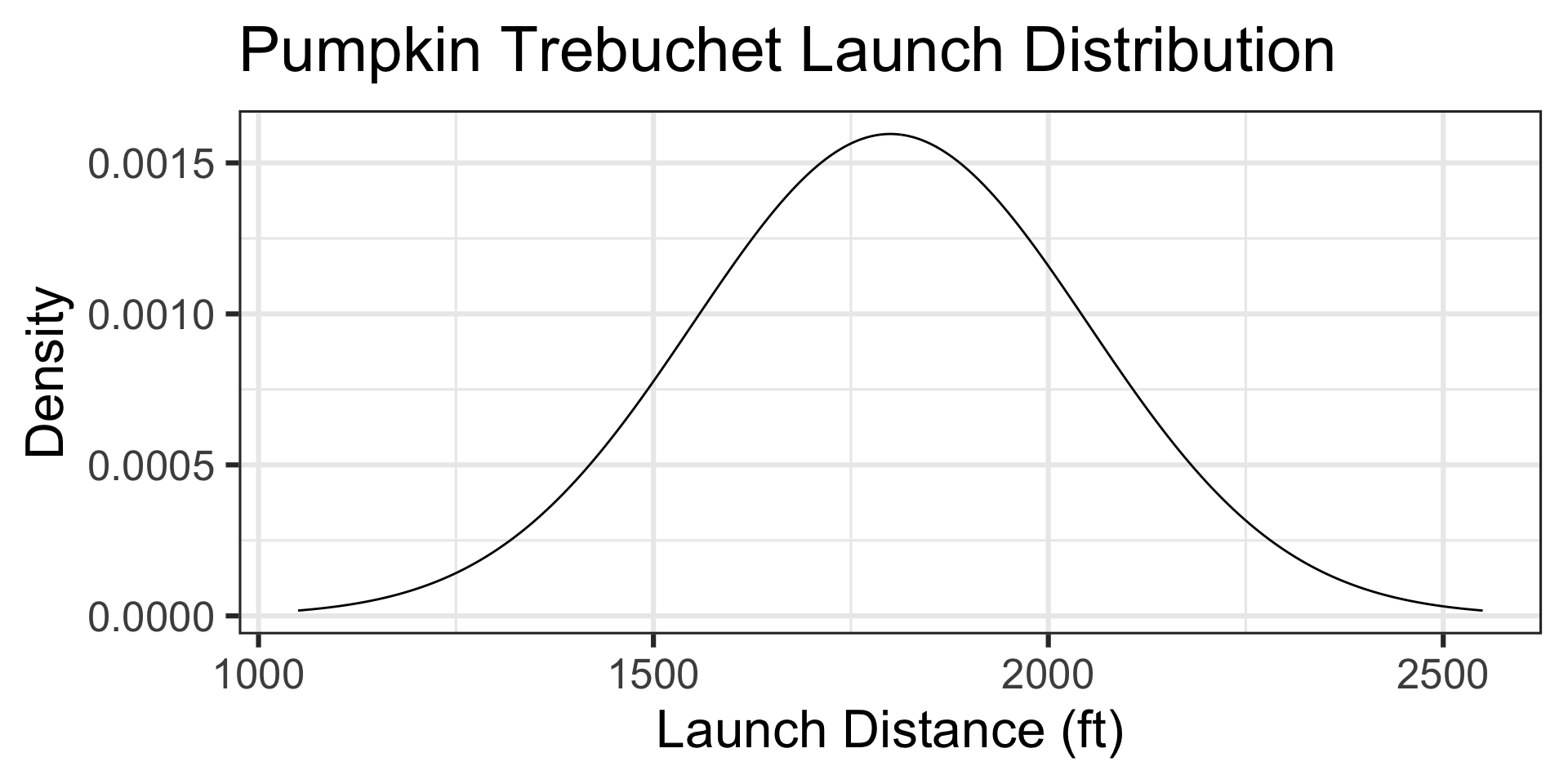
Sampling One Observation at a Time (Population Distribution)
The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. Find the probability that a launched pumpkin exceeds 2000ft.
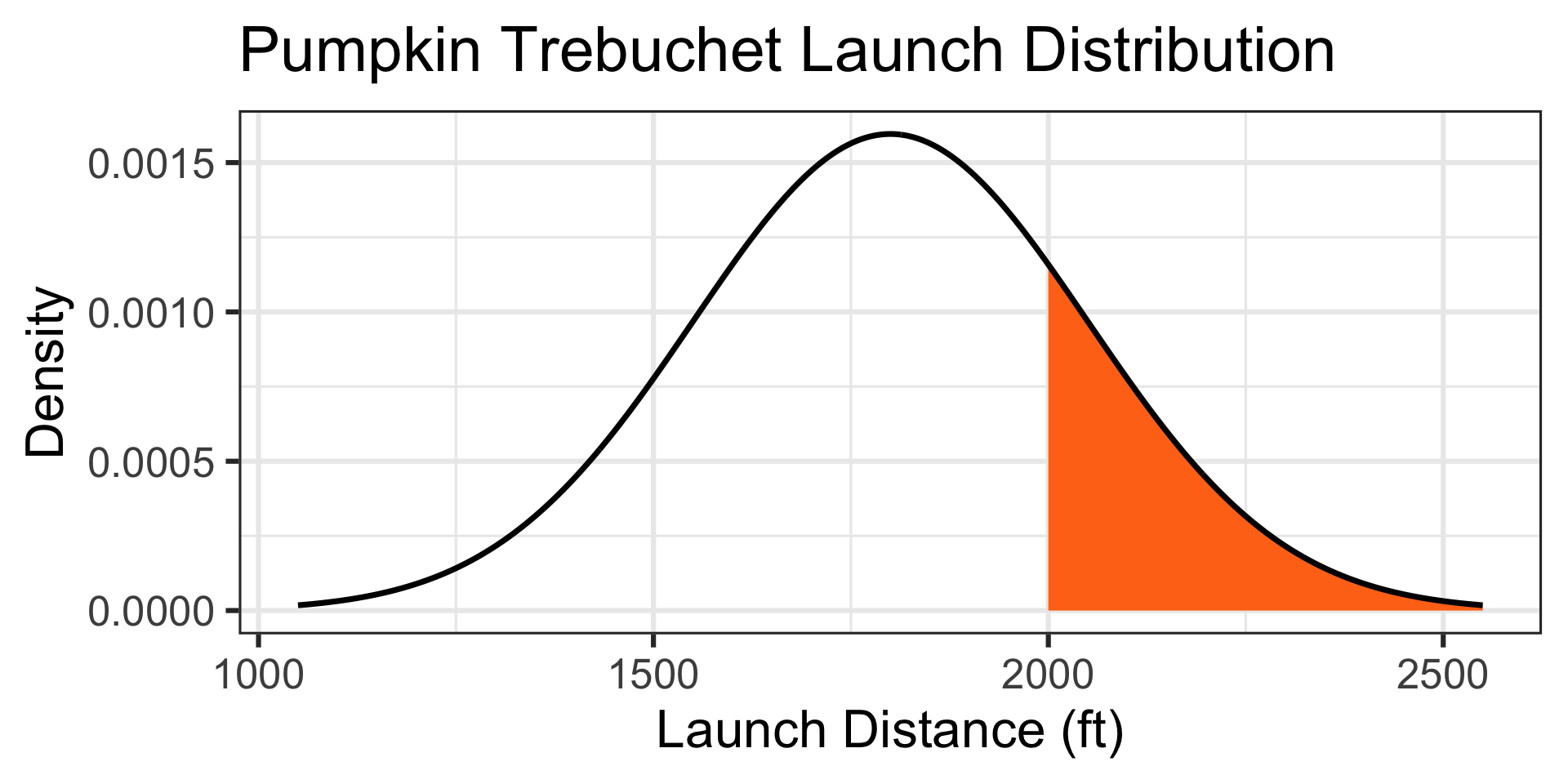
\(\mathbb{P}\left[X > 2000\right] \approx ...\)
Sampling One Observation at a Time (Population Distribution)
The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. Find the probability that a launched pumpkin exceeds 2000ft.
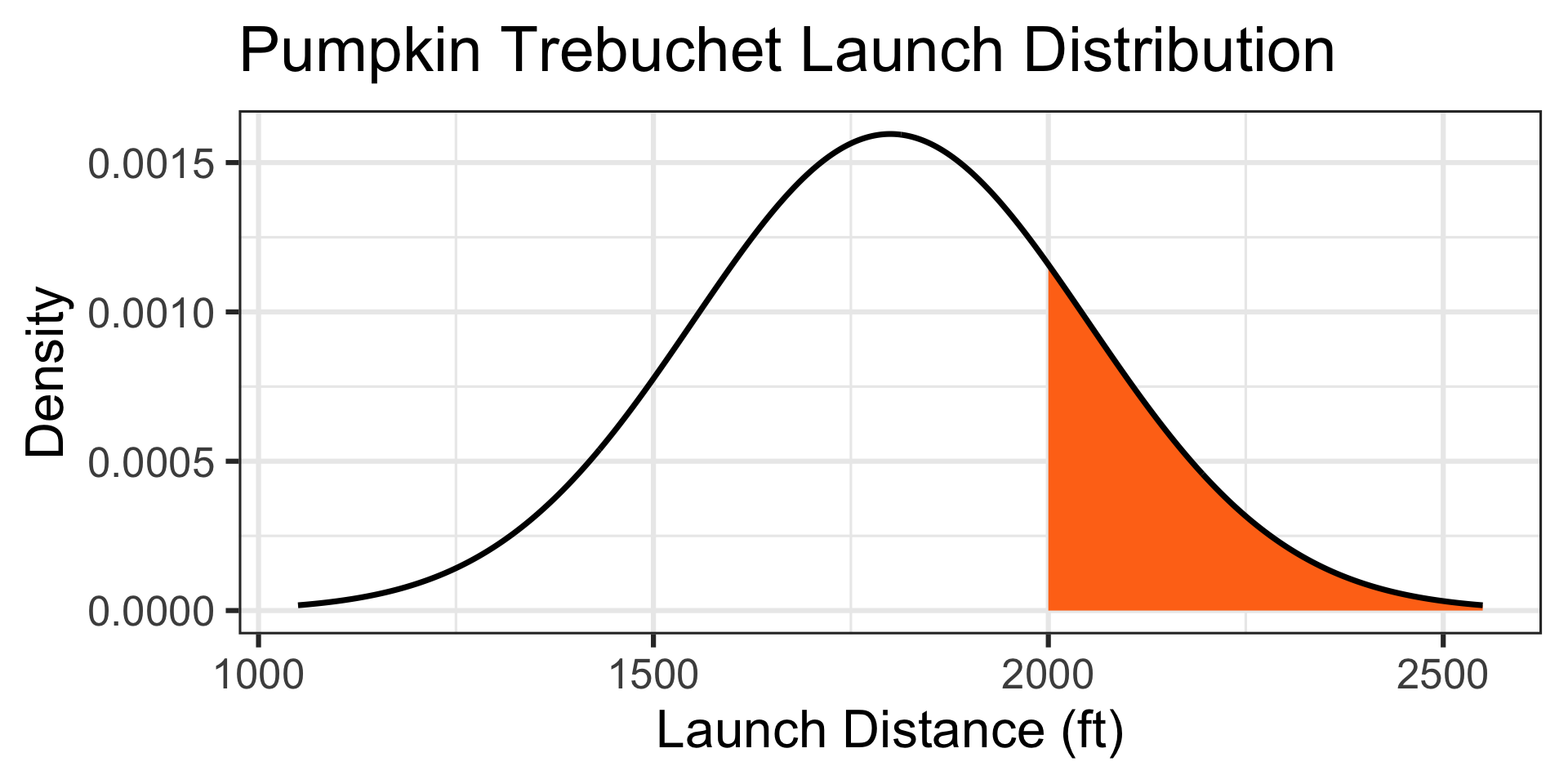
\(\mathbb{P}\left[X > 2000\right] \approx ...\)
1 - pnorm(2000, mean = 1800, sd = 250) \(\approx\) 0.2118554
Sampling One Observation at a Time (Population Distribution)
The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. Find the probability that a launched pumpkin exceeds 2000ft.
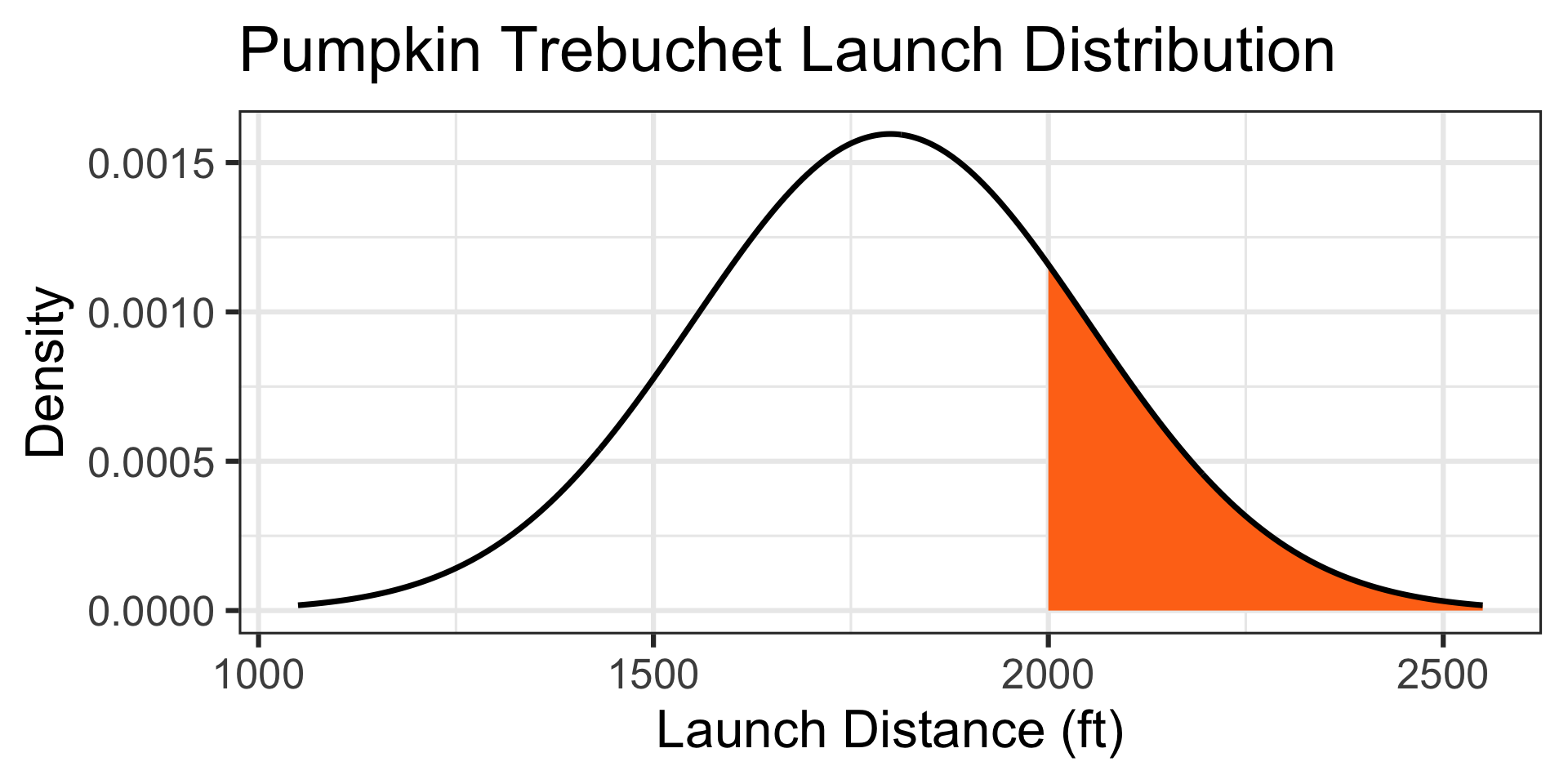
\(\mathbb{P}\left[X > 2000\right] \approx ...\)
1 - pnorm(2000, mean = 1800, sd = 250) \(\approx\) 0.2118554
There’s about a 21.19% chance that a randomly selected pumpkin will be launched further than 2,000ft.
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
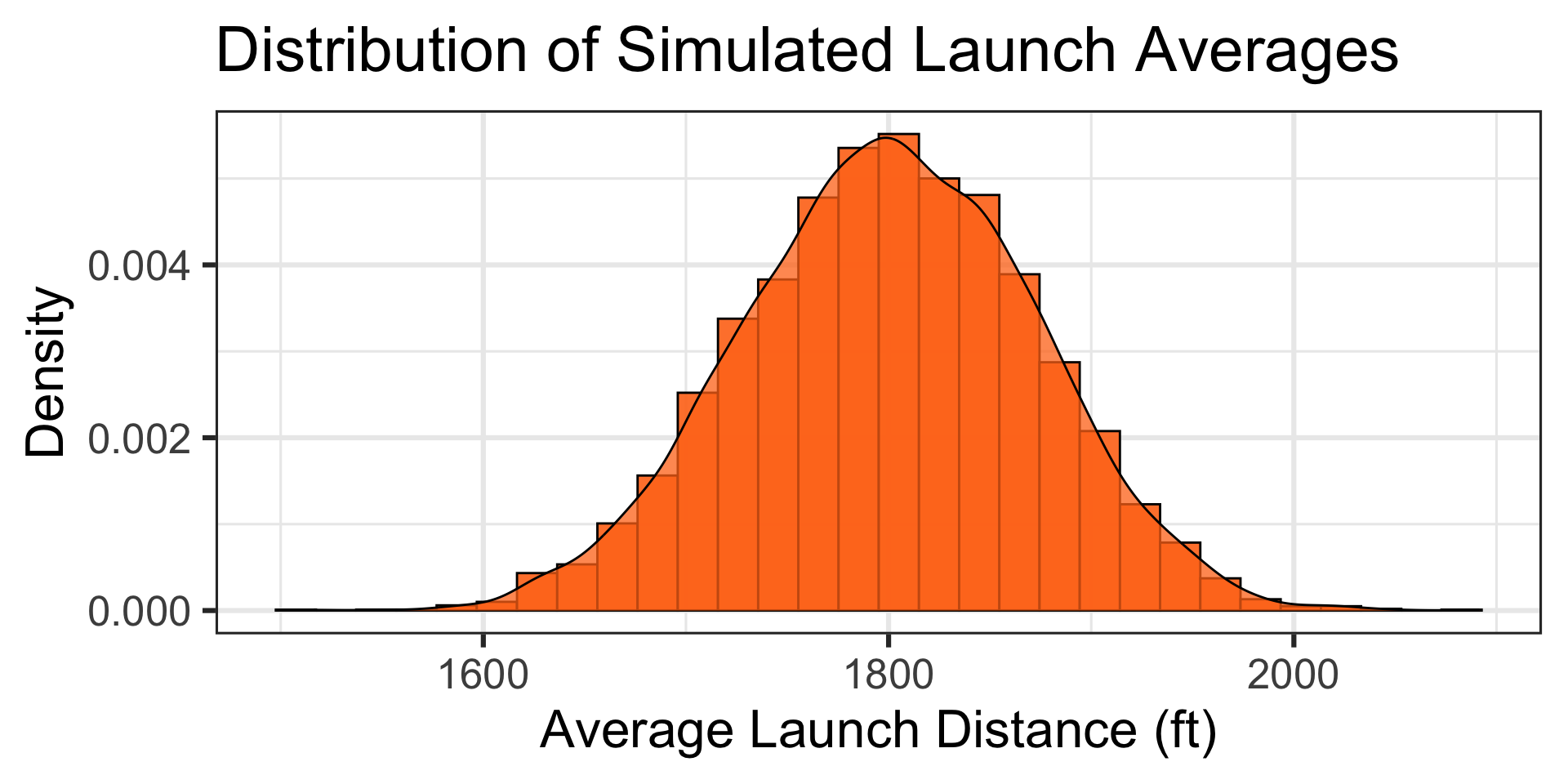
A Simulation: Let’s simulate the launches of 12 randomly selected 10lb pumpkins…
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
A Simulation: Let’s simulate the launches of 12 randomly selected 10lb pumpkins… The simulated launch distances appear below and the launches, along their average launch distance are shown by the vertical lines on the graph to the right.
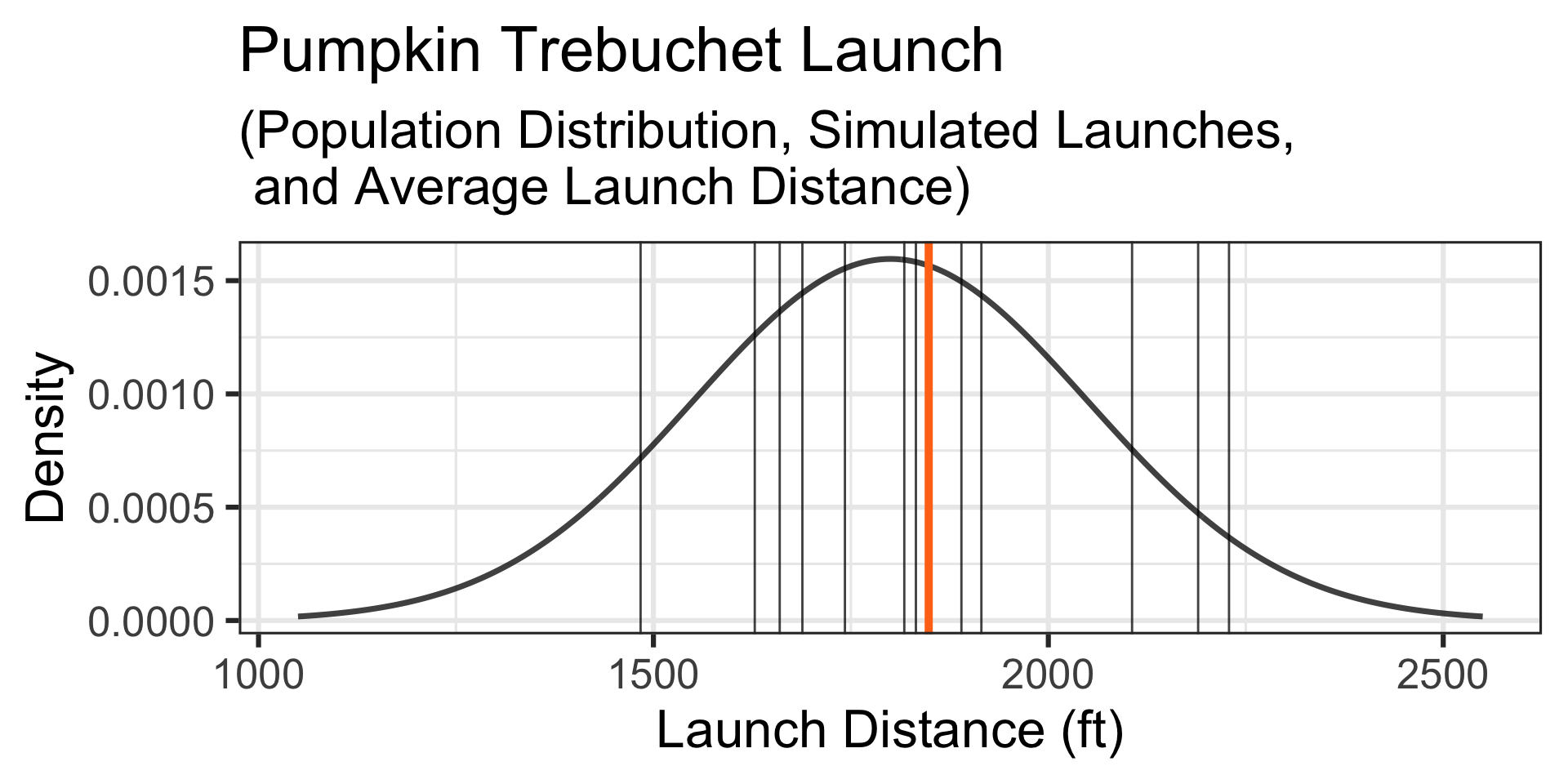
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
A Simulation: Let’s simulate another set of launches of 12 randomly selected 10lb pumpkins… The simulated launch distances appear below and the launches, along their average launch distance and the average launch distance from our first set of launches are shown on the graph to the right.
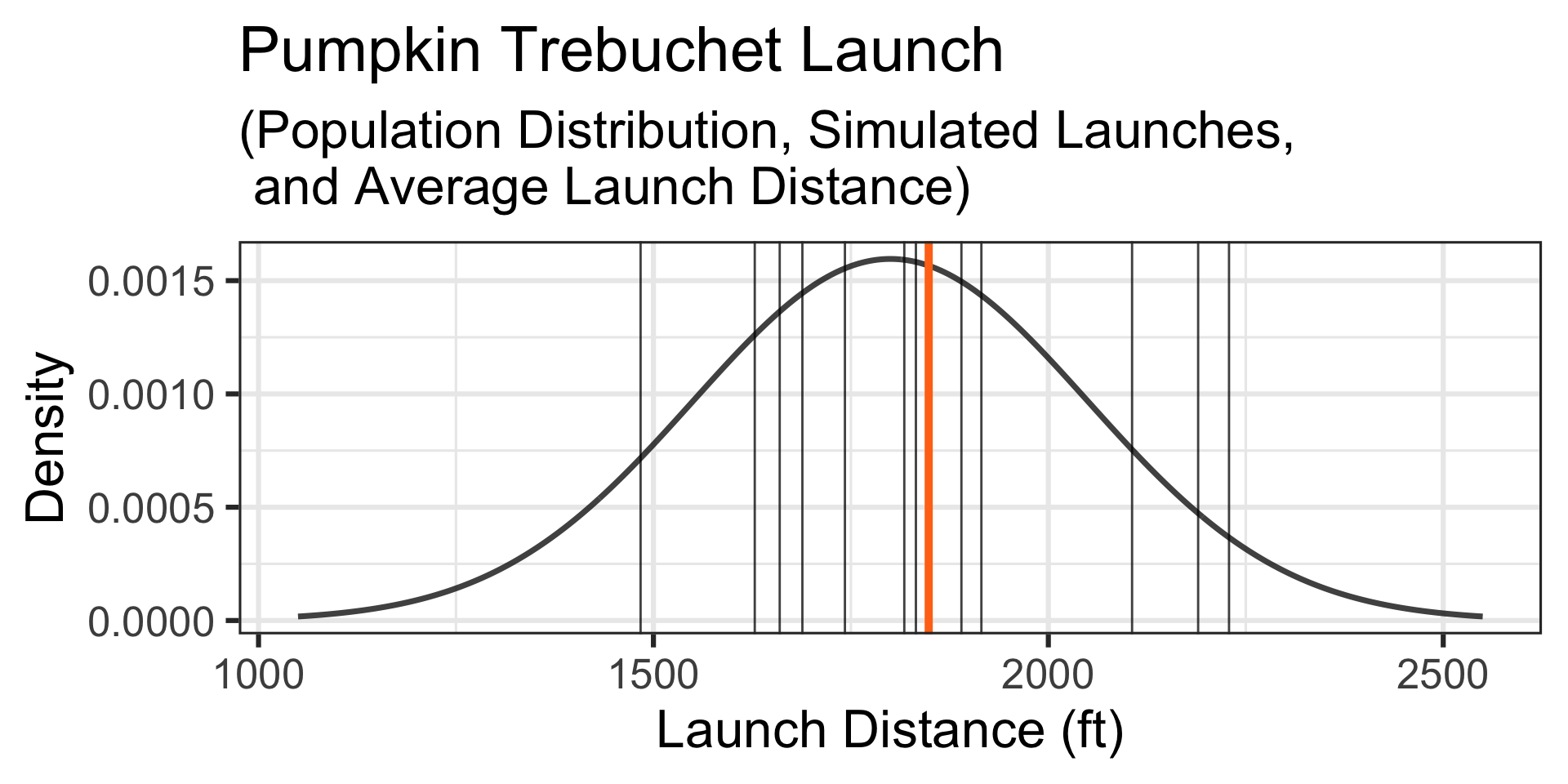
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
A Simulation: Let’s simulate another set of launches of 12 randomly selected 10lb pumpkins… The simulated launch distances appear below and the launches, along their average launch distance and the average launch distance from our first set of launches are shown on the graph to the right.
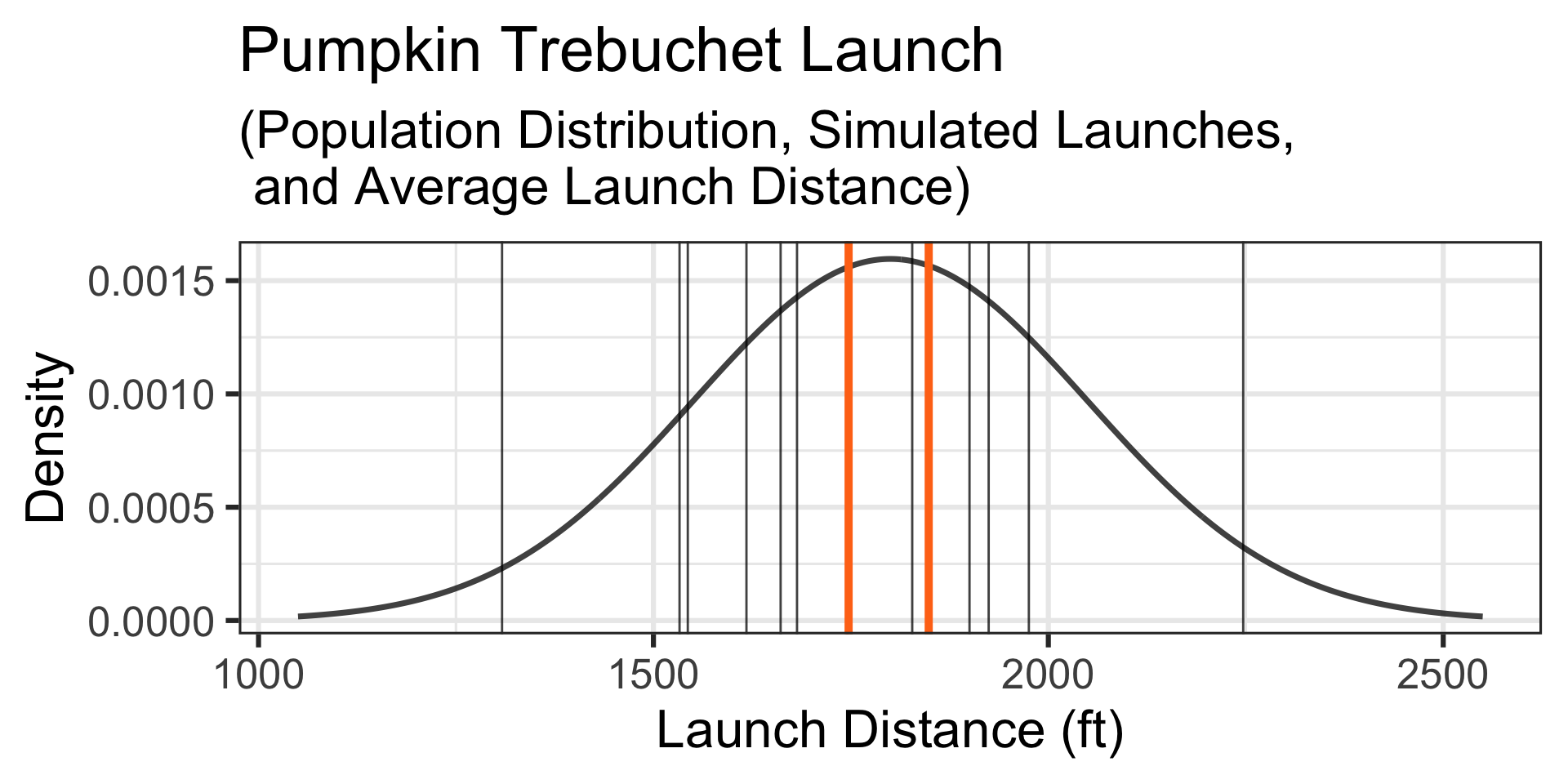
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
A Simulation: Okay – we see how this is working, but it’s going slowly. Let’s simulate 50,000 collections of launches of 12 randomly selected 10lb pumpkins.
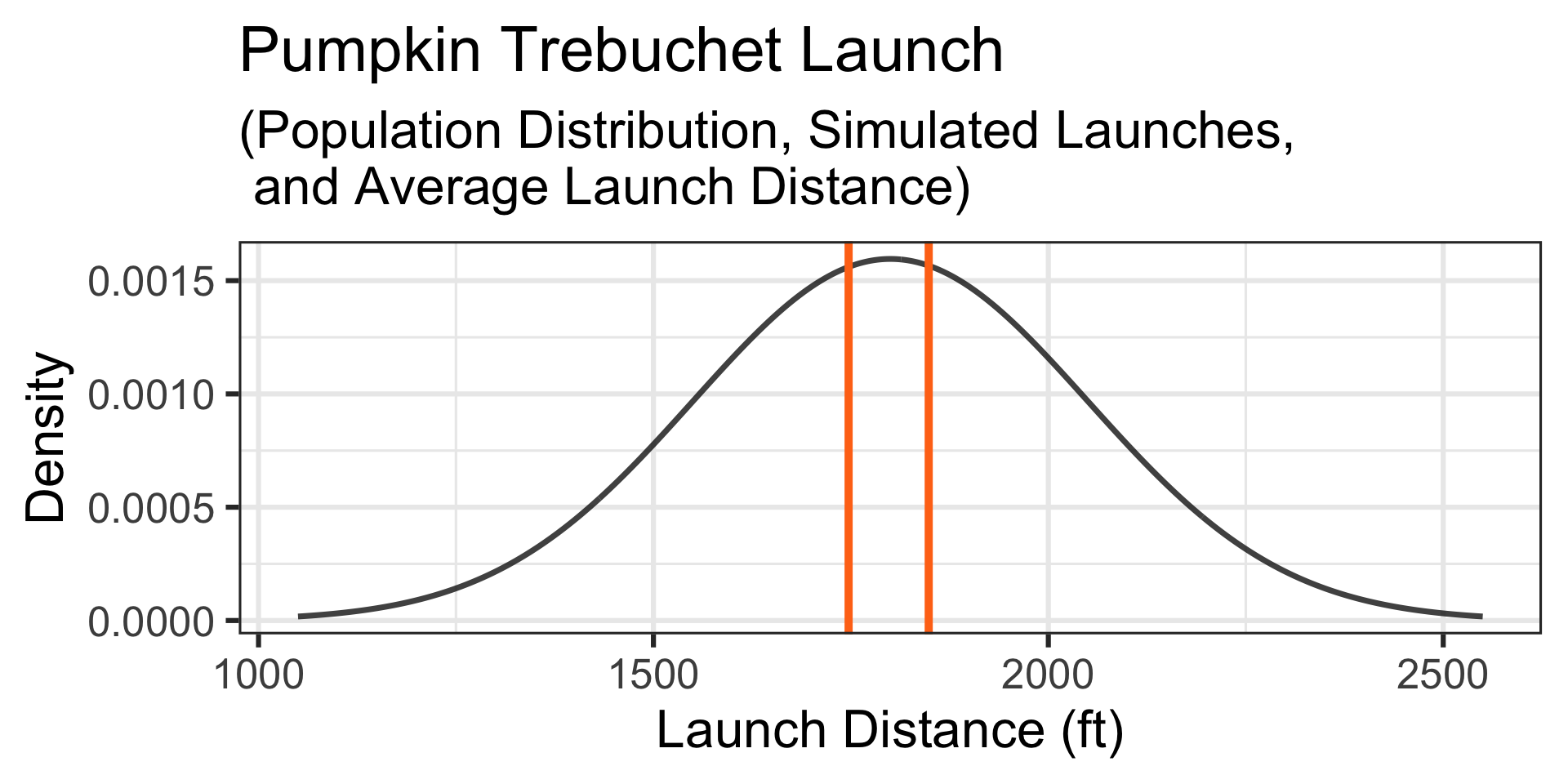
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
A Simulation: Okay – we see how this is working, but it’s going slowly. Let’s simulate 50,000 collections of launches of 12 randomly selected 10lb pumpkins.
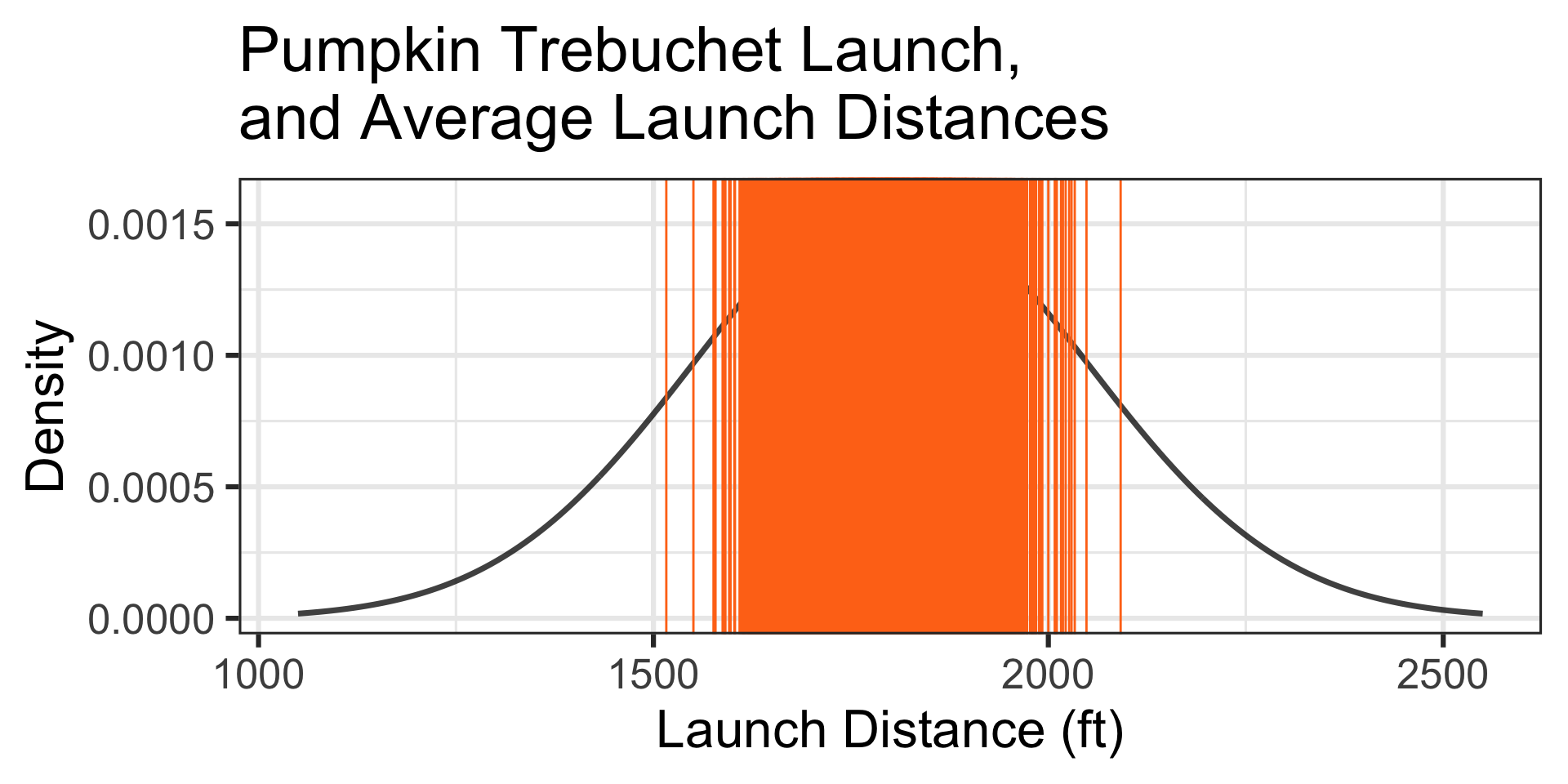
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
A Simulation: Okay – we see how this is working, but it’s going slowly. Let’s simulate 50,000 collections of launches of 12 randomly selected 10lb pumpkins.
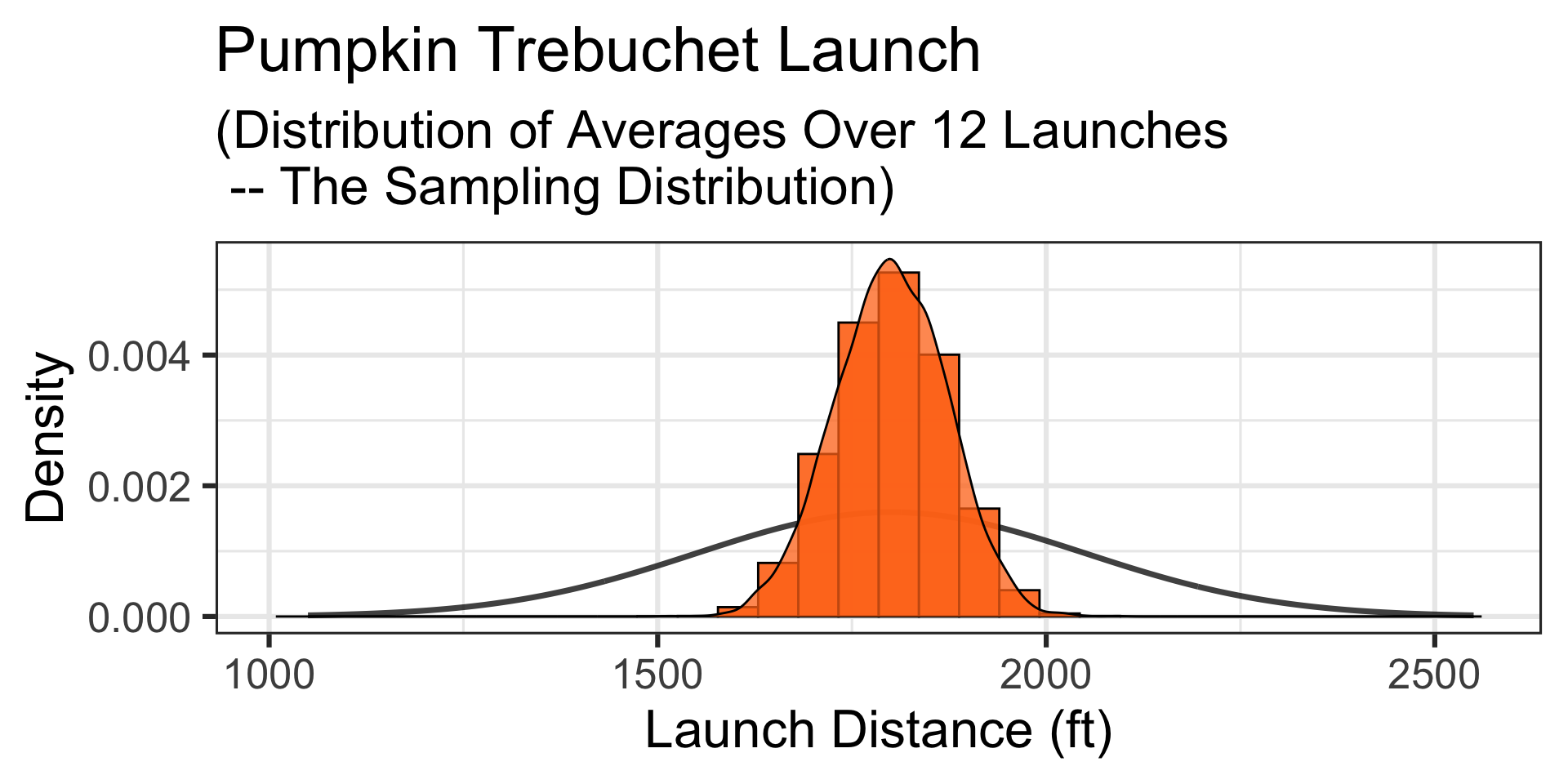
Motivating Example: A Confident Team…
Motivating Example: A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
A Simulation: Okay – we see how this is working, but it’s going slowly. Let’s simulate 50,000 collections of launches of 12 randomly selected 10lb pumpkins.
An average launch distance of 2,028ft is at the green vertical line.
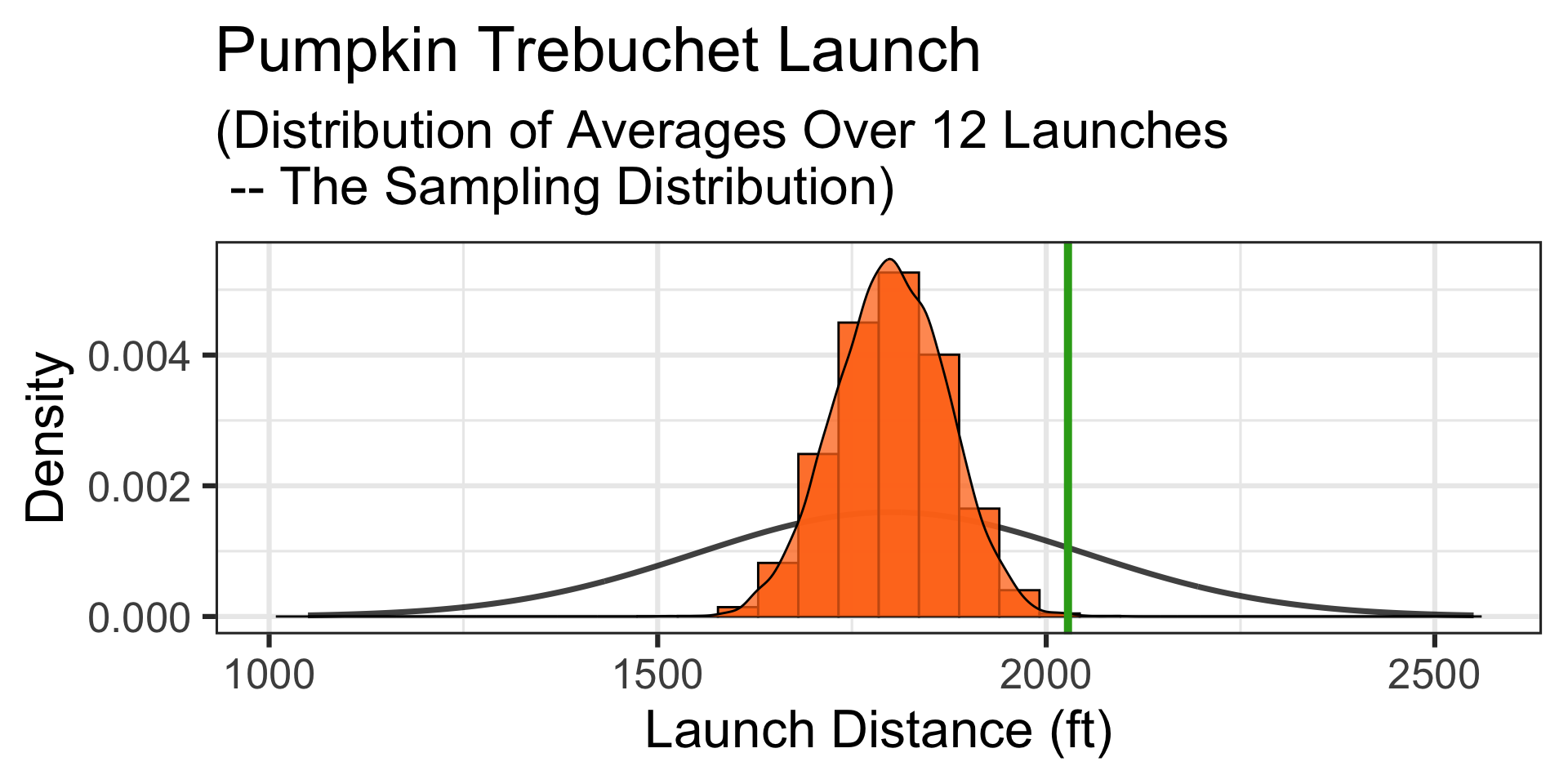
Takeaway: The distribution of averages of 12 launches is much more narrow than the population distribution. The probability of averaging a distance of at least 2,028ft is much lower than the probability of a single launch being at least 2,028ft.
We’ll come back and finish this problem soon, but first we need a detour to talk about this new, more narrow distribution.
Hypothetical Population and Sampling Distributions for Means
Flimps, flomps, and flumps are [fictitious] numerical variables whose population distributions appear below and with corresponding sampling distributions to the right.
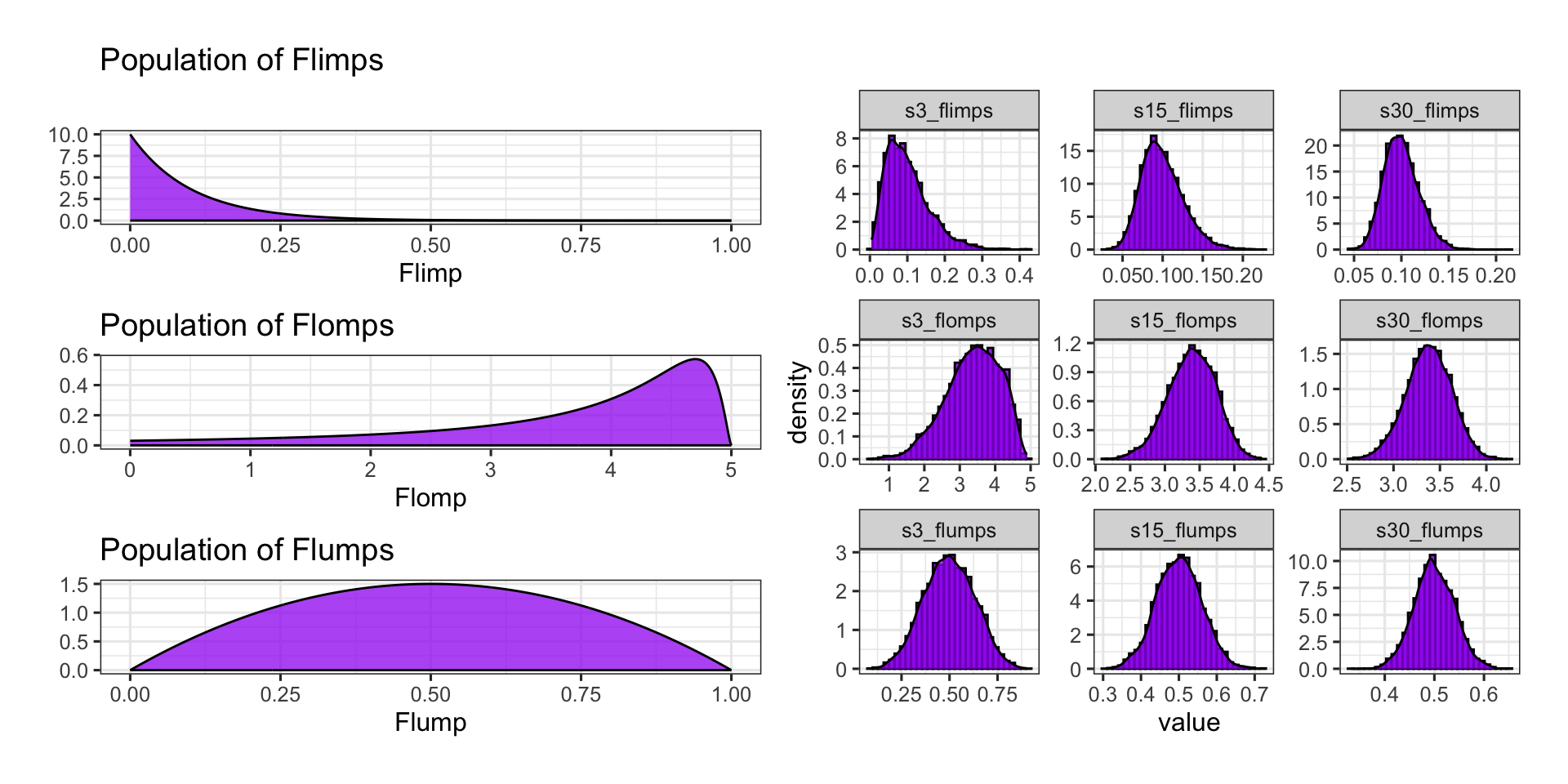
Sampling distributions are shown for samples of three observations (s3_*), fifteen observations (s15_*), and thirty observations (s30_*).
Hypothetical Population and Sampling Distributions for Proportions
Similarly, grimps, gromps, and grumps are [fictitious] categorical variables for which we can define success and failure. The sampling distributions for proportion corresponding to a successful outcome appears below.
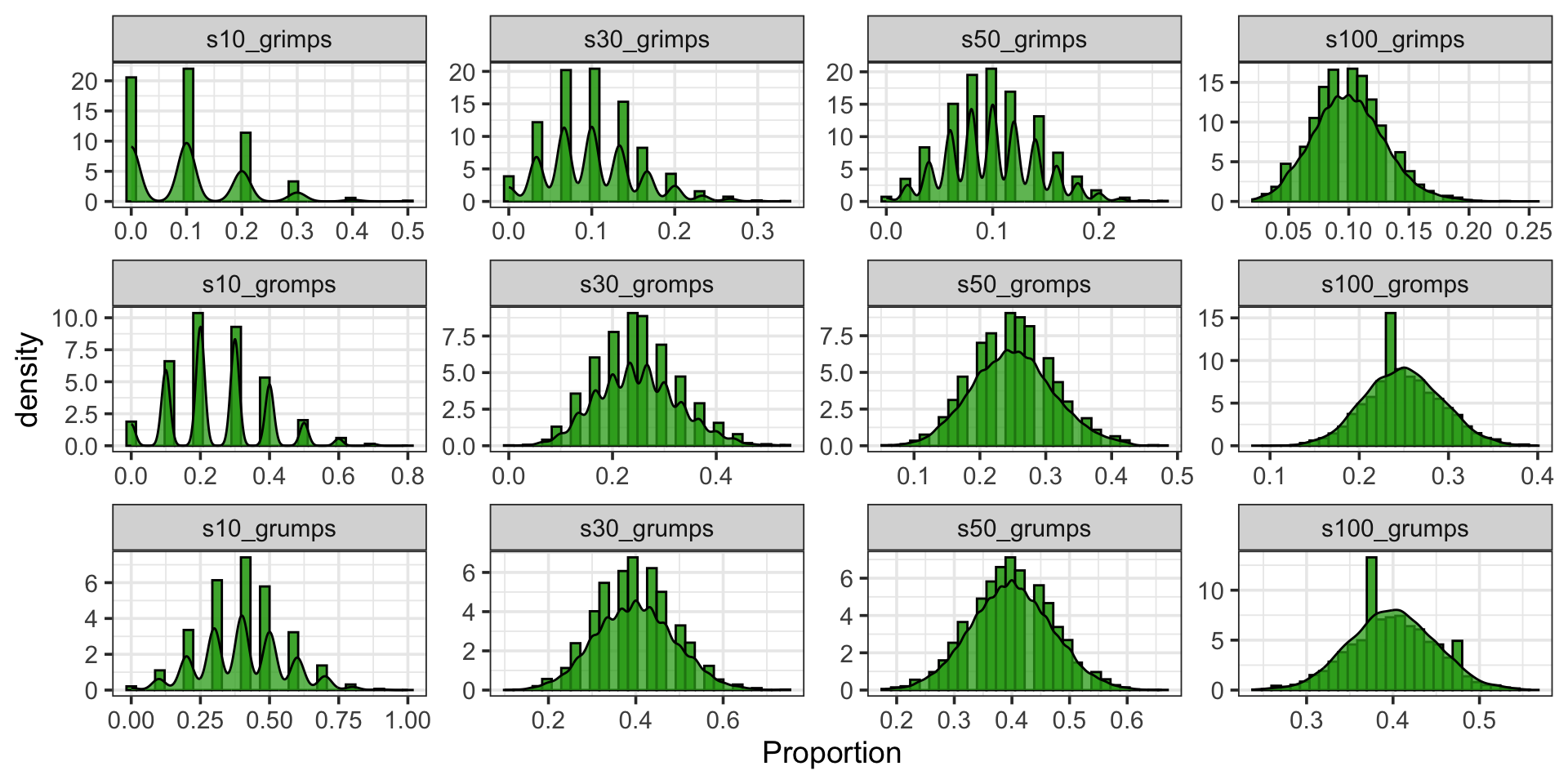
Sampling distributions this time are shown for samples of ten observations (s10_*), thirty observations (s30_*), fifty observations (s50_*), and one hundred observations (s100_*).
When is a Sampling Distribution [Nearly] Normal?
Important: Bringing back our sampling distributions for flimps, flomps, and flumps (numerical variables) we see that the more skewed the population distribution, the larger the sample size required before the sampling distribution is well-approximated by a normal distribution.
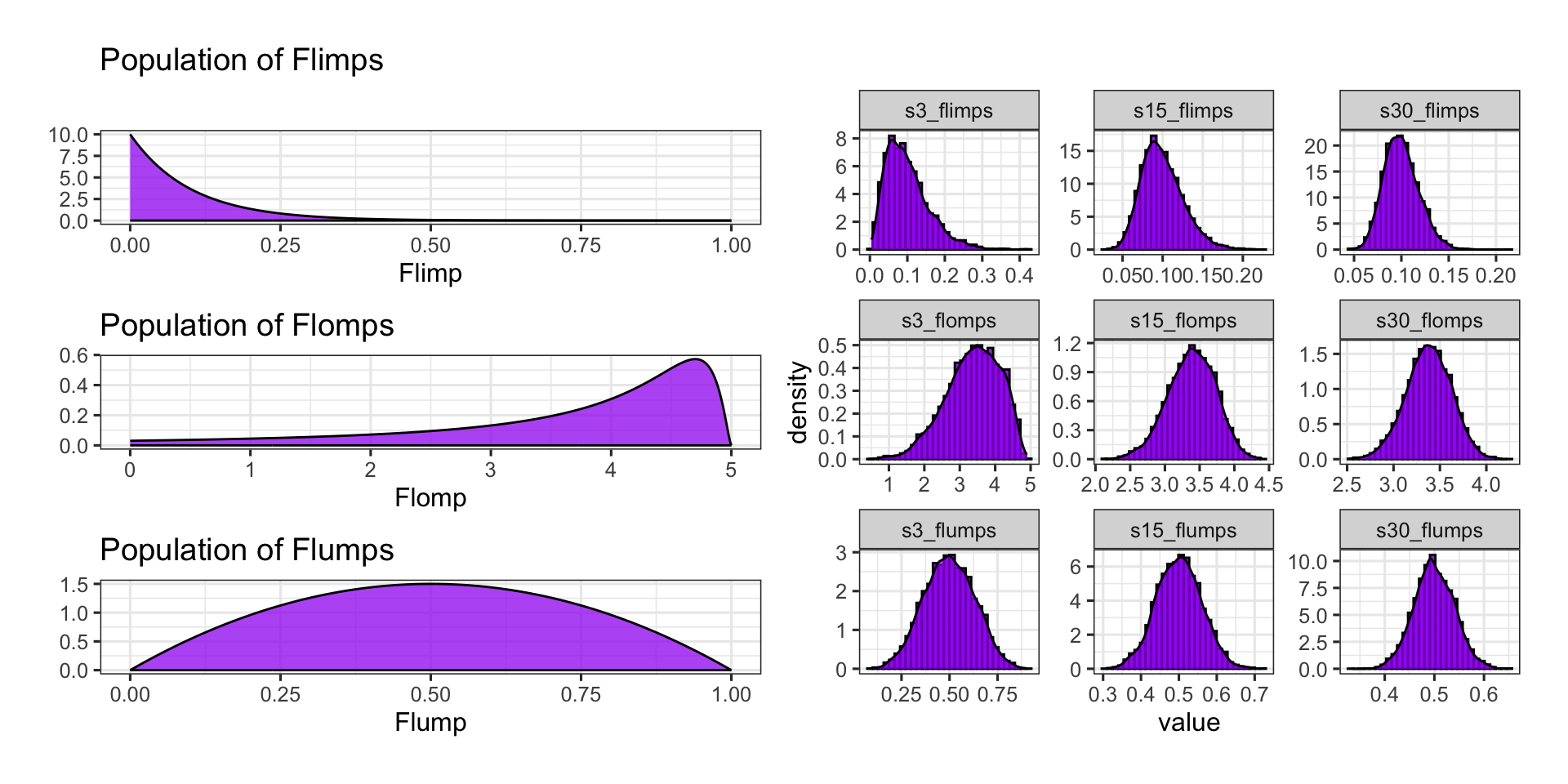
Some people/books recommend \(n\geq 30\), but I advocate against this rule of thumb because of the slightly maintained skew we see in the top two rows of plots.
When is a Sampling Distribution [Nearly] Normal?
Important: Bringing back our sampling distributions for grimps, gromps, and grumps (binary categorical variables) we see that the presence of skew is related to the population proportion and the sample size.
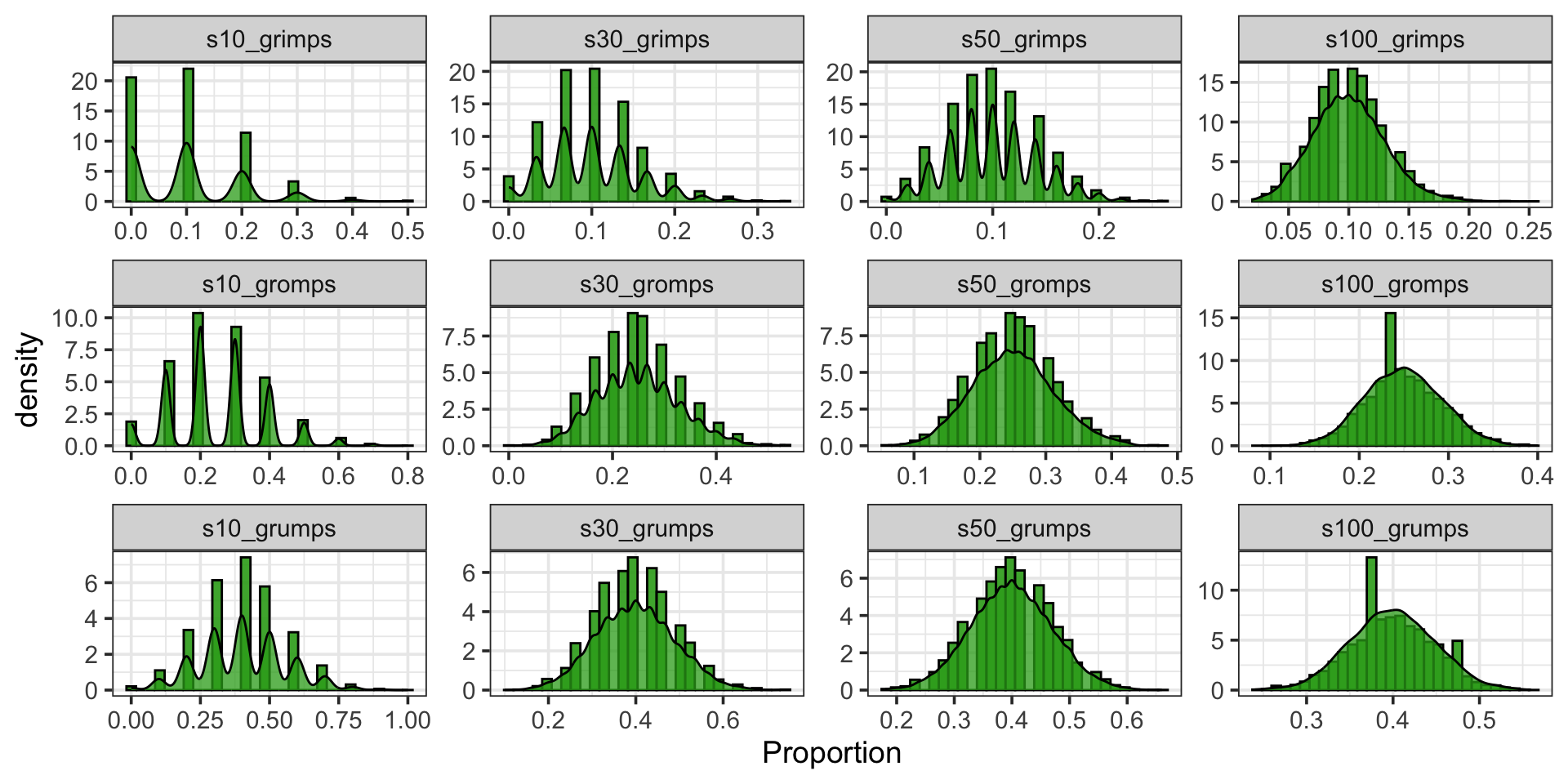
As a rule of thumb, the sampling distribution for the population proportion is nearly normal as long as \(n\cdot p\geq 10\) and \(n\cdot\left(1 - p\right) \geq 10\). That is, we expect at least 10 successes and at least 10 failures.
This is sometimes called the success-failure condition.
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
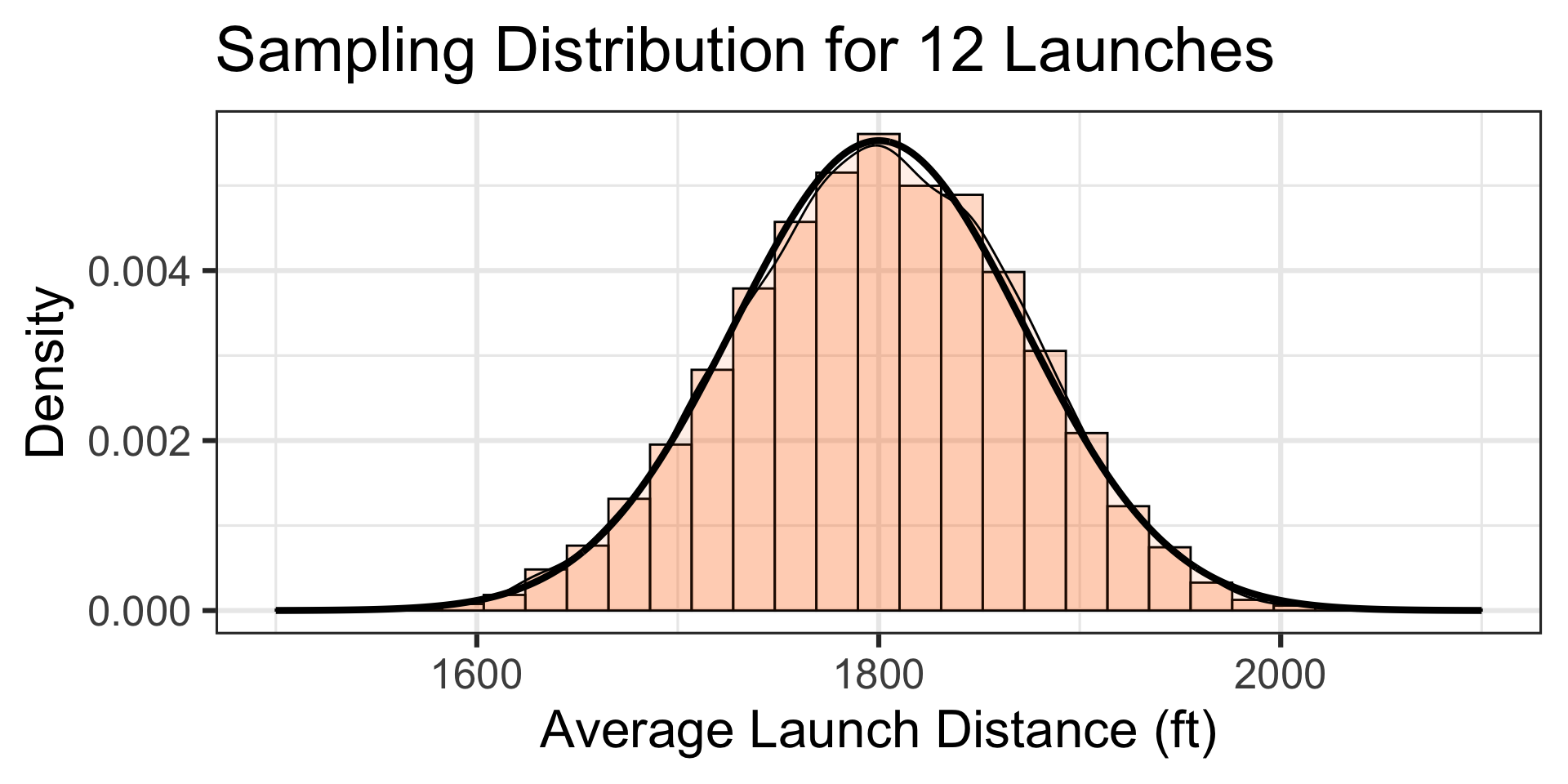
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
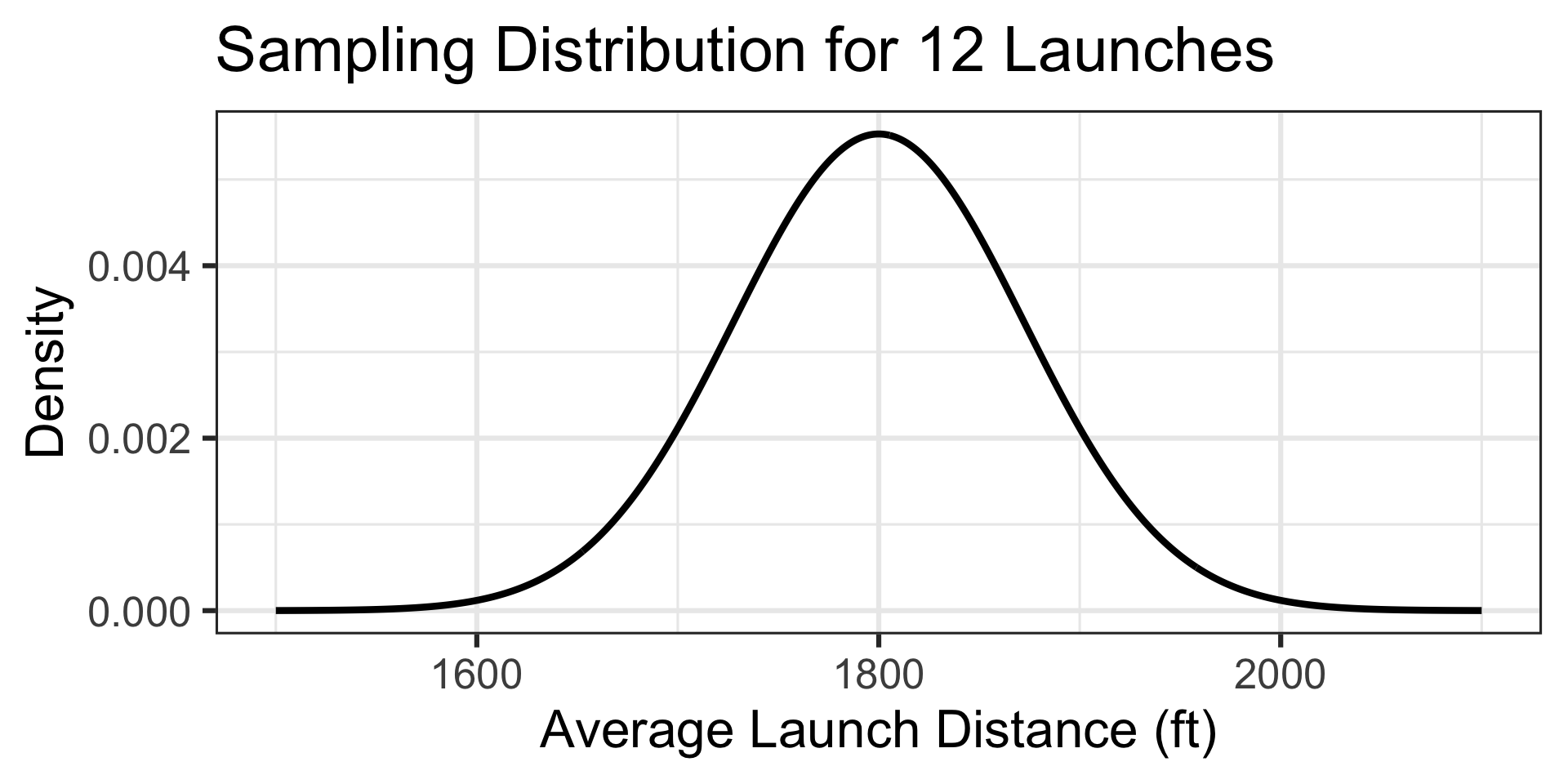
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
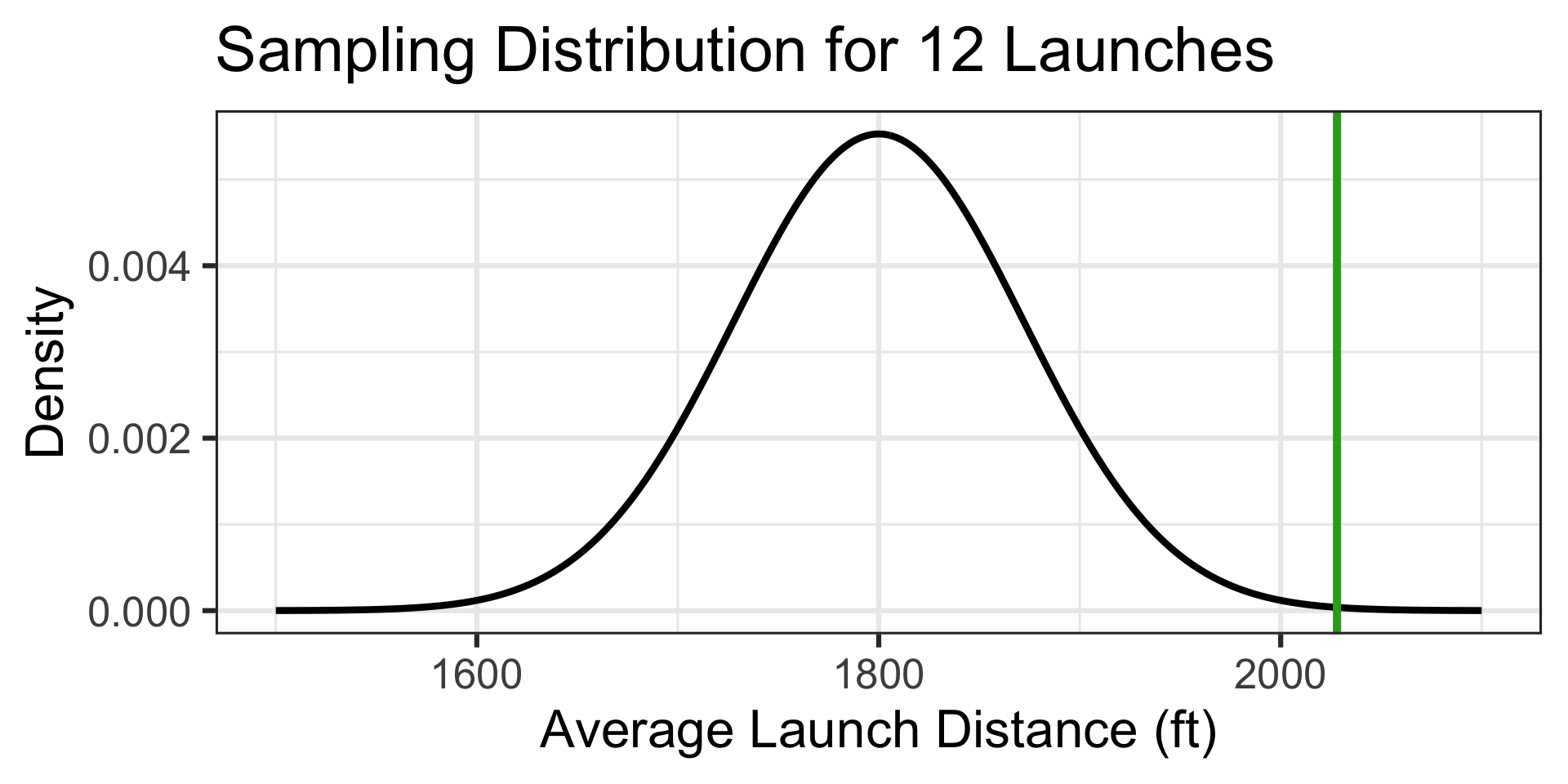
The probability of an average launch distance of at least 2,028ft is…
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
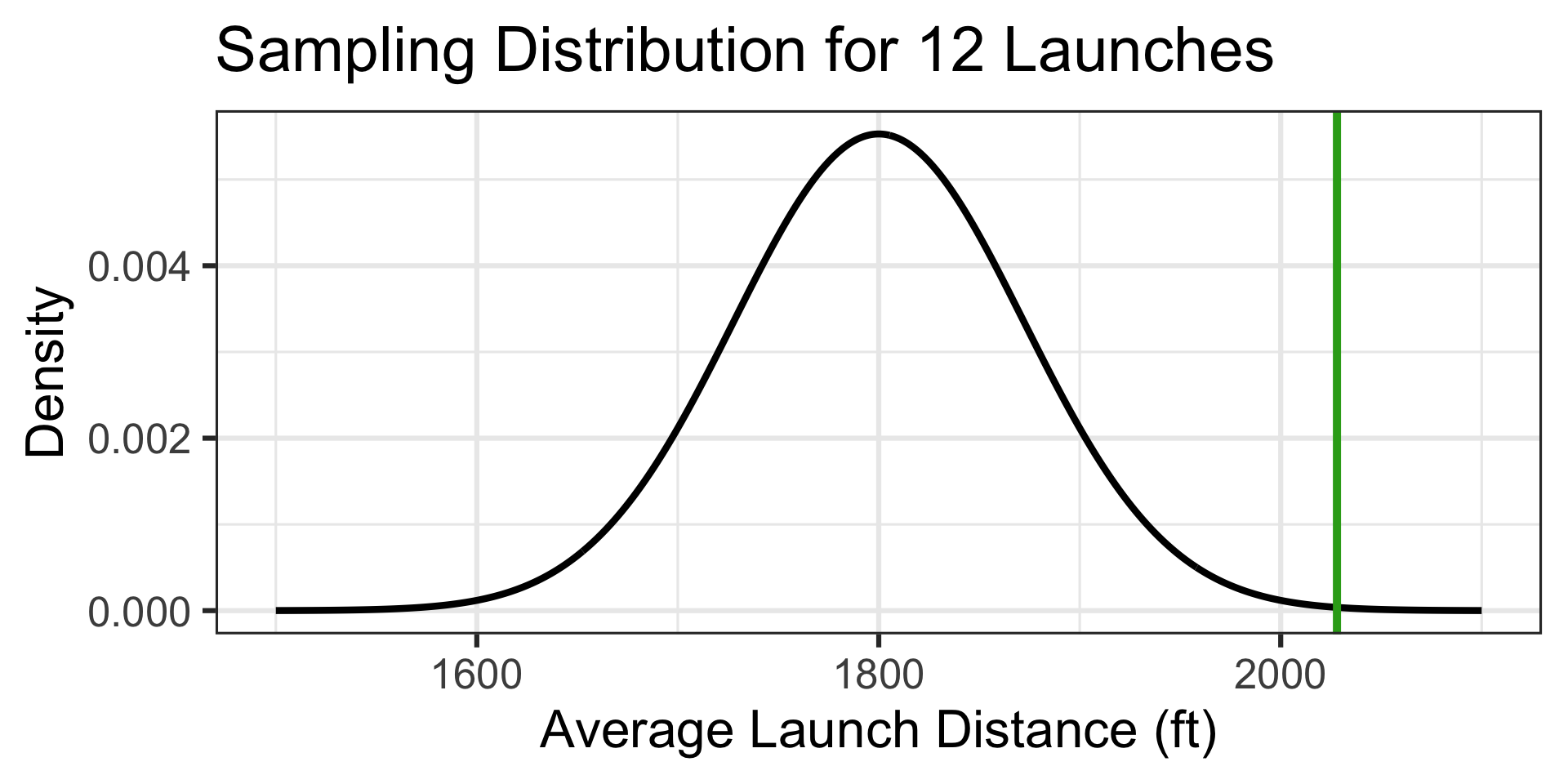
The probability of an average launch distance of at least 2,028ft is…
1 - pnorm(2028, 1800, 250/sqrt(12)) \(\approx\) 0.0008
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
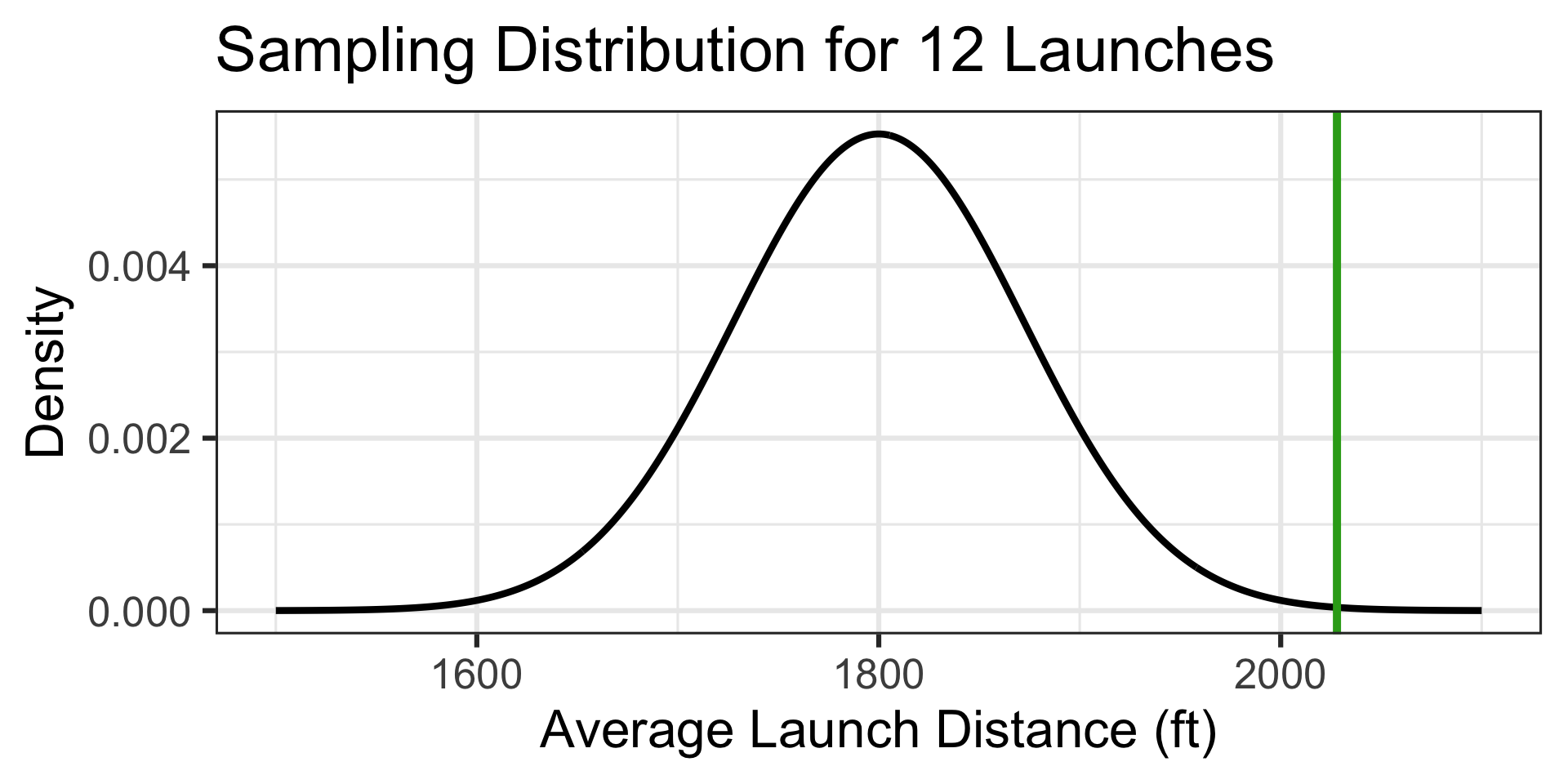
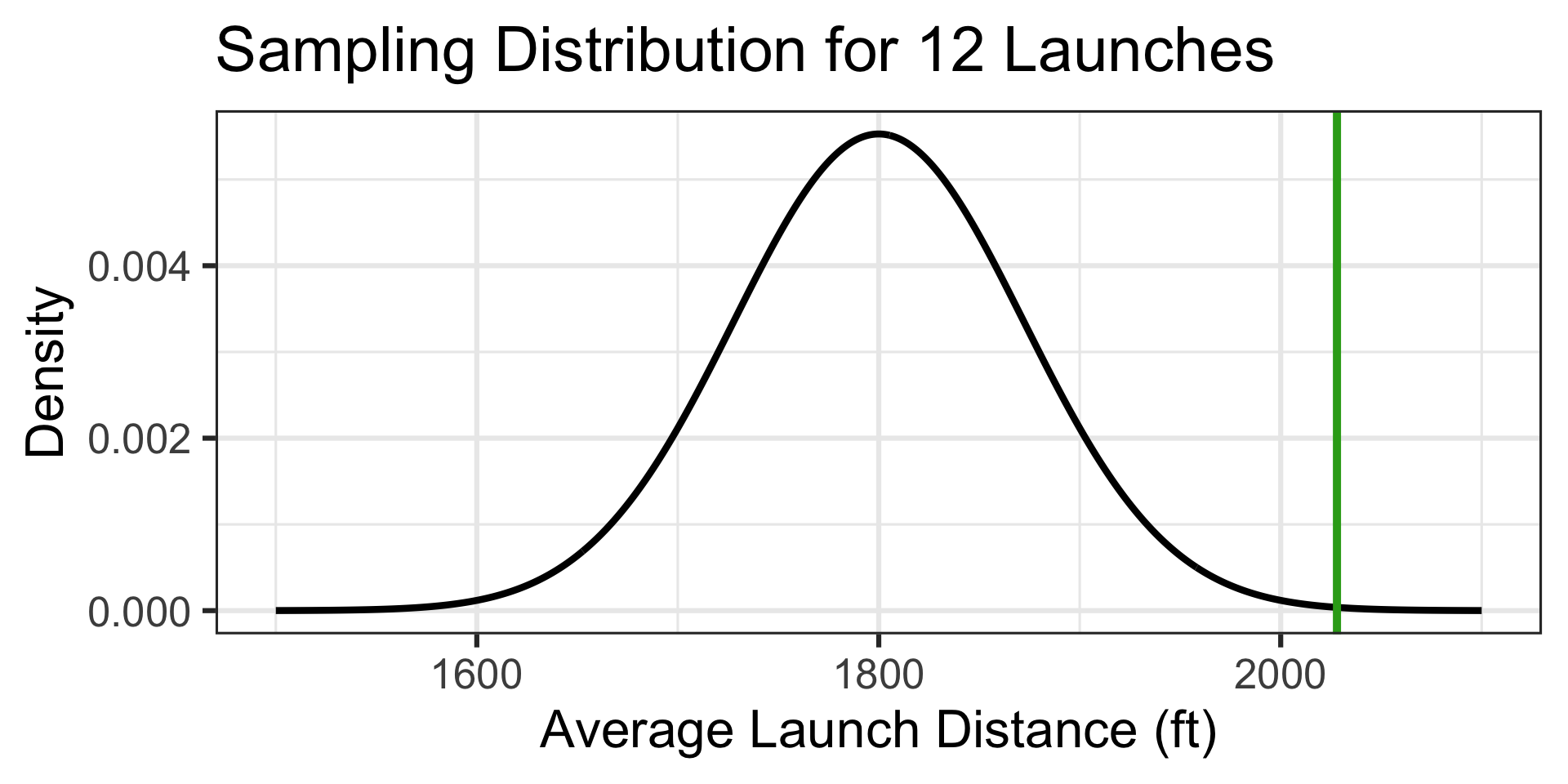
The probability of an average launch distance of at least 2,028ft is…
1 - pnorm(2028, 1800, 250/sqrt(12)) \(\approx\) 0.0008
Observing an average launch distance this long is extremely unlikely if the average launch is really 1,800ft. This team’s trebuchet is likely much stronger than the average trebuchet!
Back to Pumpkin Launching!
Reminder: The distances traveled by a 10lb pumpkin launched via a trebuchet are approximately normally distributed with a mean of 1800ft and a standard deviation of 250ft. A particular team feels that their pumpkin launching trebuchet is much better than average. On a typical day (it’s not extra windy), the team launches a random selection of twelve 10lb pumpkins. Their average launch distance is 2,028ft. What is the probability that a random selection of twelve launches averages 2,028ft or further?
Note that the population distribution of launch distances is not skewed (it is approximately normal).
This means that we have no skew to overcome, and our sampling distribution will be approximately normal.
Launch distance is a numerical variable, and so the sampling distribution for average launch distances of 12 pumpkins will be \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 1800, S_E = 250/\sqrt{12}\right)}\)
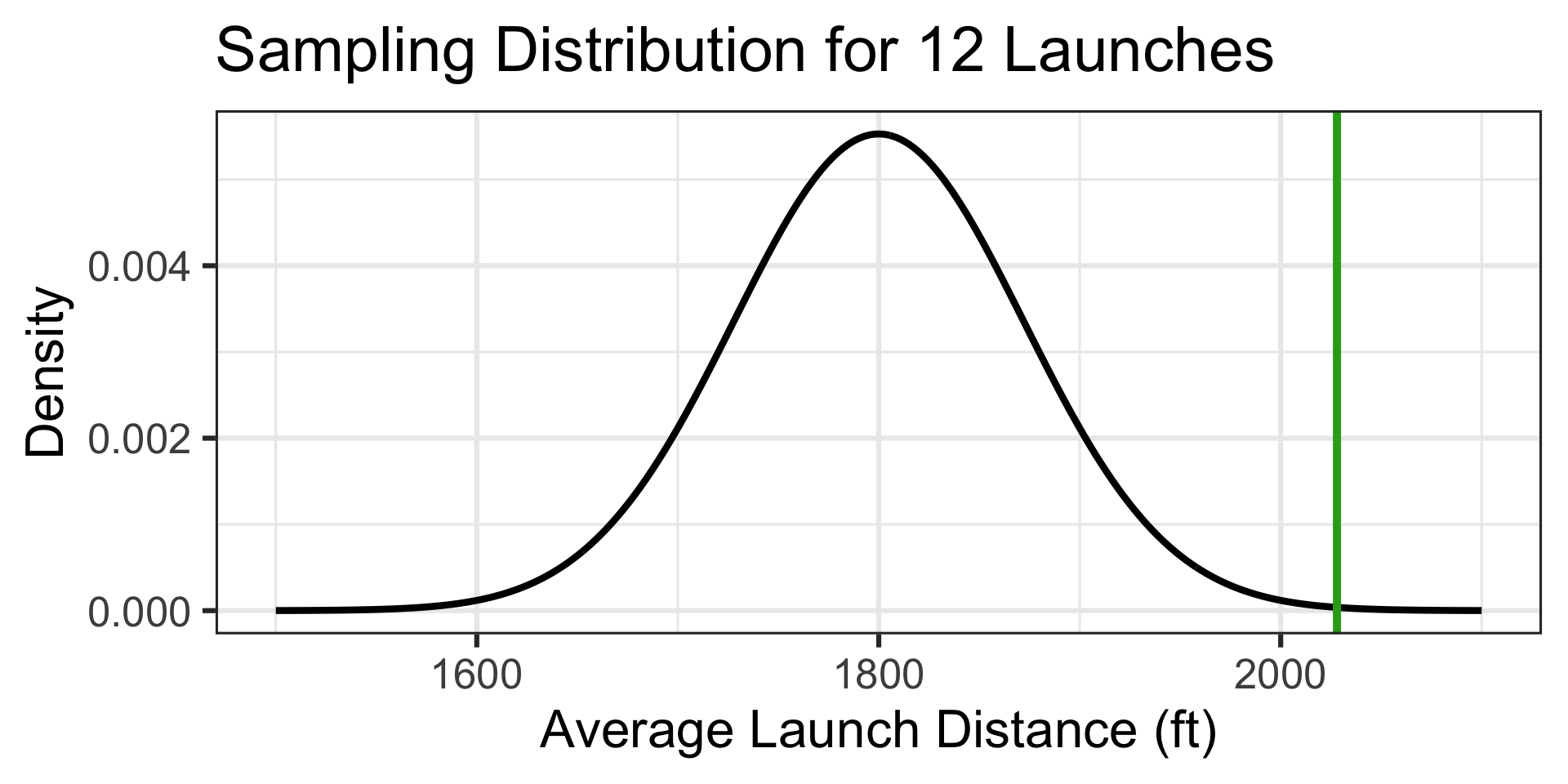
The probability of an average launch distance of at least 2,028ft is…
1 - pnorm(2028, 1800, 250/sqrt(12)) \(\approx\) 0.0008
Observing an average launch distance this long is extremely unlikely if the average launch is really 1,800ft. This team’s trebuchet is likely much stronger than the average trebuchet!
FYI: The current world record is a launch of 4,091ft by a trebuchet named “Chunk Norris”, captained by Mike Powers of Bedford, NH!
Completed Example: On-Time Package Delivery II
Scenario: A major online retailer, let’s call it “Amazonia”, has an internal benchmark to ensure that at least 97% of its packages are delivered on time. A logistics manager has concerns that a particular distribution center has been falling short of this target. The logistics manager takes a new random sample of 500 recent package deliveries. Out of these, 475 were delivered on time. Assuming that the facility is in compliance with the 97% on-time delivery rate, what is the probability that 95% or fewer packages arrive on time in a random sample of 500 deliveries.
Again the variable of interest is a proportion.
Since this is the case, we’ll check the success-failure condition…
\(\begin{array}{lcl} n\cdot p & = & 500\cdot\left(0.97\right) = 485 \geq 10~\checkmark\\ n\cdot \left(1 - p\right) & = & 500\cdot\left(0.03\right) = 15 \geq 10~\checkmark \end{array}\)The success-failure condition is satisfied, so the CLT says that the sampling distribution for the proportion will be \(\displaystyle{N\left(p,~S_E = \sqrt{\frac{p\left(1 - p\right)}{n}}\right)}\)
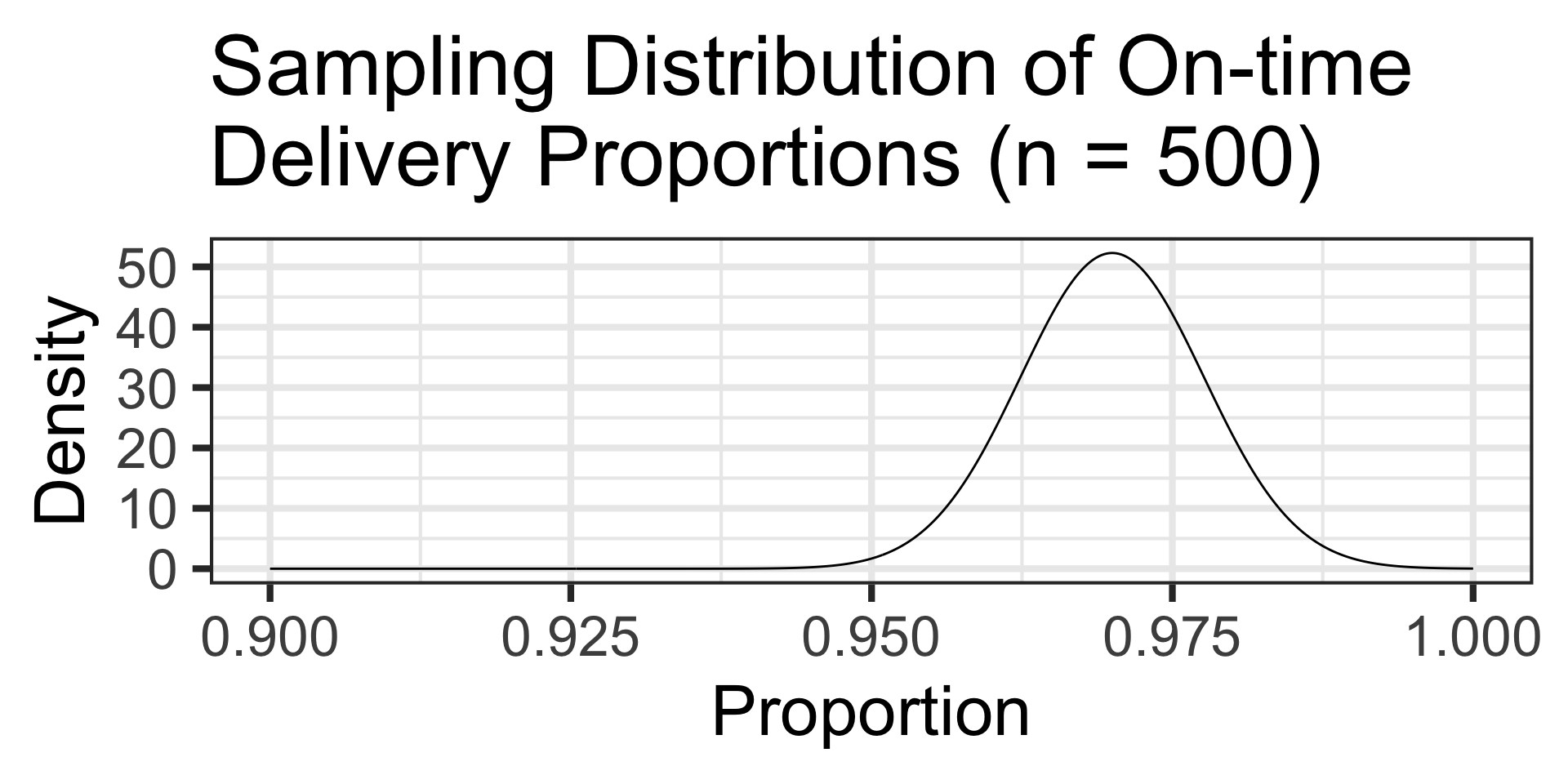
Completed Example: On-Time Package Delivery II
Scenario: A major online retailer, let’s call it “Amazonia”, has an internal benchmark to ensure that at least 97% of its packages are delivered on time. A logistics manager has concerns that a particular distribution center has been falling short of this target. The logistics manager takes a new random sample of 500 recent package deliveries. Out of these, 475 were delivered on time. Assuming that the facility is in compliance with the 97% on-time delivery rate, what is the probability that 95% or fewer packages arrive on time in a random sample of 500 deliveries.
Again the variable of interest is a proportion.
Since this is the case, we’ll check the success-failure condition…
\(\begin{array}{lcl} n\cdot p & = & 500\cdot\left(0.97\right) = 485 \geq 10~\checkmark\\ n\cdot \left(1 - p\right) & = & 500\cdot\left(0.03\right) = 15 \geq 10~\checkmark \end{array}\)The success-failure condition is satisfied, so the CLT
says that the sampling distribution for the proportion
will be \(\displaystyle{N\left(p,~S_E = \sqrt{\frac{p\left(1 - p\right)}{n}}\right)}\)
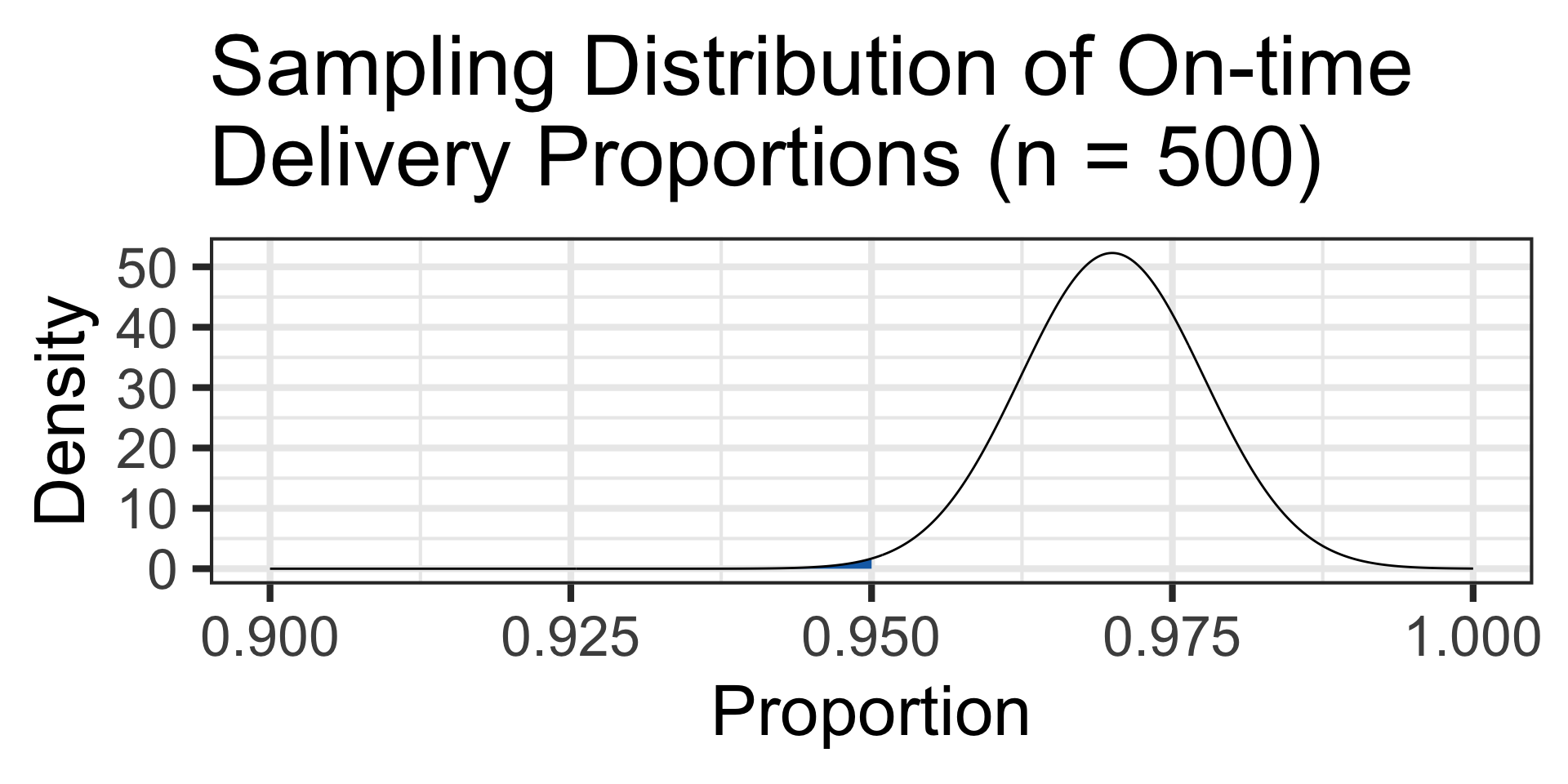
The probability of observing 95% or lower on-time package delivery proportions is…
Completed Example: On-Time Package Delivery II
Scenario: A major online retailer, let’s call it “Amazonia”, has an internal benchmark to ensure that at least 97% of its packages are delivered on time. A logistics manager has concerns that a particular distribution center has been falling short of this target. The logistics manager takes a new random sample of 500 recent package deliveries. Out of these, 475 were delivered on time. Assuming that the facility is in compliance with the 97% on-time delivery rate, what is the probability that 95% or fewer packages arrive on time in a random sample of 500 deliveries.
Again the variable of interest is a proportion.
Since this is the case, we’ll check the success-failure condition…
\(\begin{array}{lcl} n\cdot p & = & 500\cdot\left(0.97\right) = 485 \geq 10~\checkmark\\ n\cdot \left(1 - p\right) & = & 500\cdot\left(0.03\right) = 15 \geq 10~\checkmark \end{array}\)The success-failure condition is satisfied, so the CLT
says that the sampling distribution for the proportion
will be \(\displaystyle{N\left(p,~S_E = \sqrt{\frac{p\left(1 - p\right)}{n}}\right)}\)
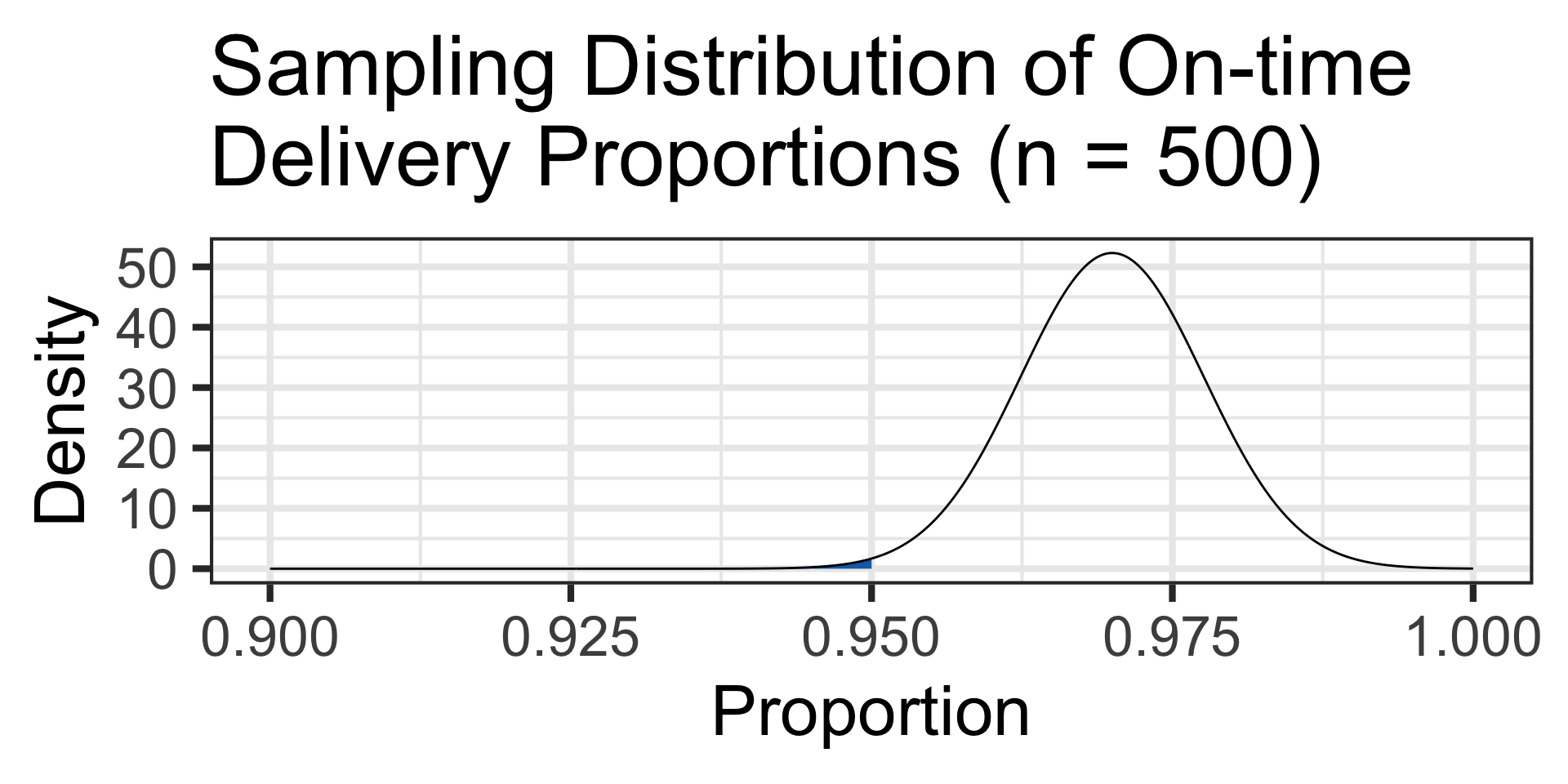
The probability of observing 95% or lower on-time package delivery proportions is…
S_E <- sqrt((0.97*0.03)/500)
pnorm(0.95, 0.97, S_E) \(\approx\) 0.0044
Completed Example: On-Time Package Delivery II
Scenario: A major online retailer, let’s call it “Amazonia”, has an internal benchmark to ensure that at least 97% of its packages are delivered on time. A logistics manager has concerns that a particular distribution center has been falling short of this target. The logistics manager takes a new random sample of 500 recent package deliveries. Out of these, 475 were delivered on time. Assuming that the facility is in compliance with the 97% on-time delivery rate, what is the probability that 95% or fewer packages arrive on time in a random sample of 500 deliveries.
Again the variable of interest is a proportion.
Since this is the case, we’ll check the success-failure condition…
\(\begin{array}{lcl} n\cdot p & = & 500\cdot\left(0.97\right) = 485 \geq 10~\checkmark\\ n\cdot \left(1 - p\right) & = & 500\cdot\left(0.03\right) = 15 \geq 10~\checkmark \end{array}\)The success-failure condition is satisfied, so the CLT
says that the sampling distribution for the proportion
will be \(\displaystyle{N\left(p,~S_E = \sqrt{\frac{p\left(1 - p\right)}{n}}\right)}\)
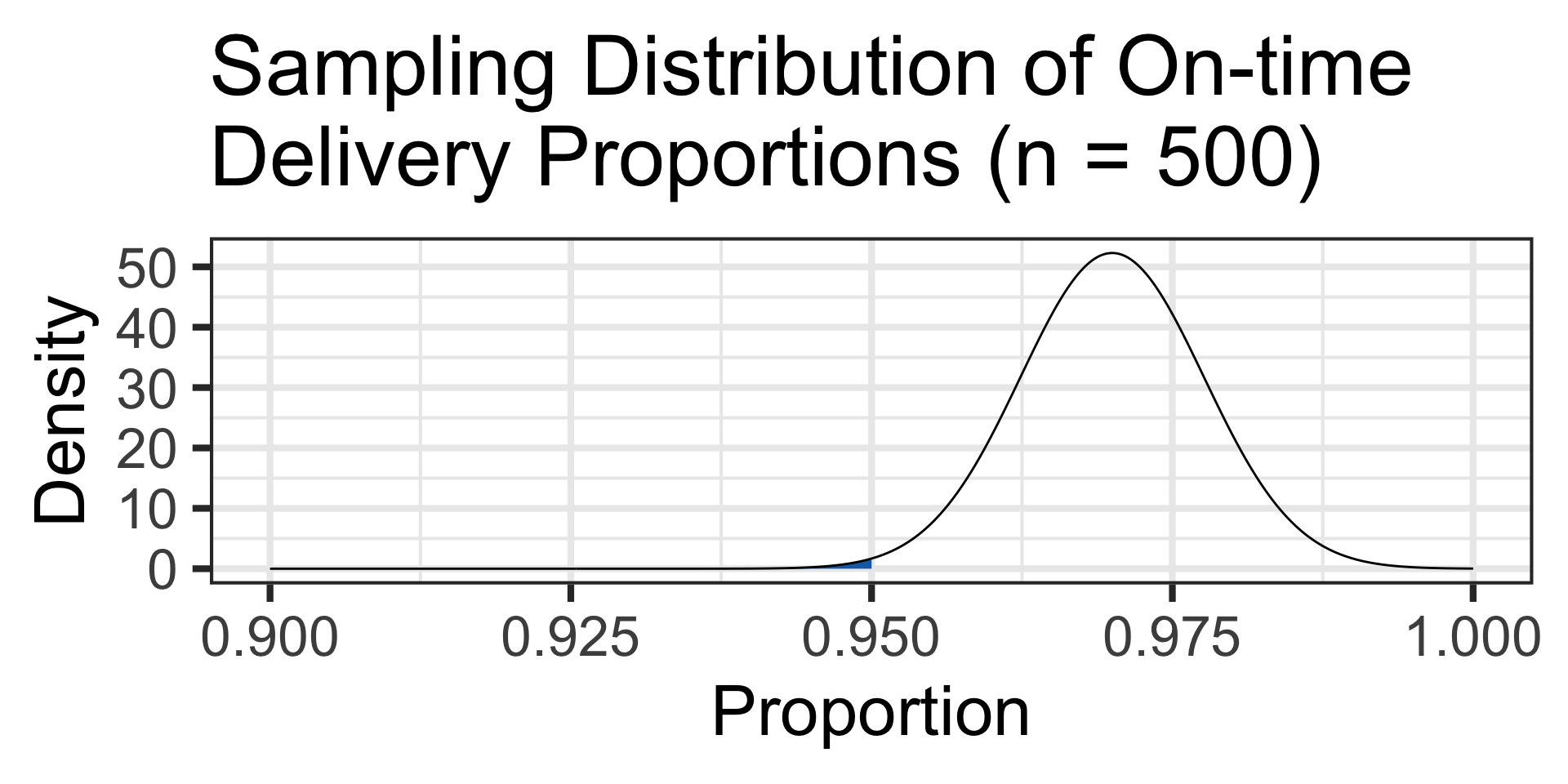
The probability of observing 95% or lower on-time package delivery proportions is…
S_E <- sqrt((0.97*0.03)/500)
pnorm(0.95, 0.97, S_E) \(\approx\) 0.0044
With such a low likelihood of observing only 95% on-time delivery, perhaps this distribution center is underperforming.
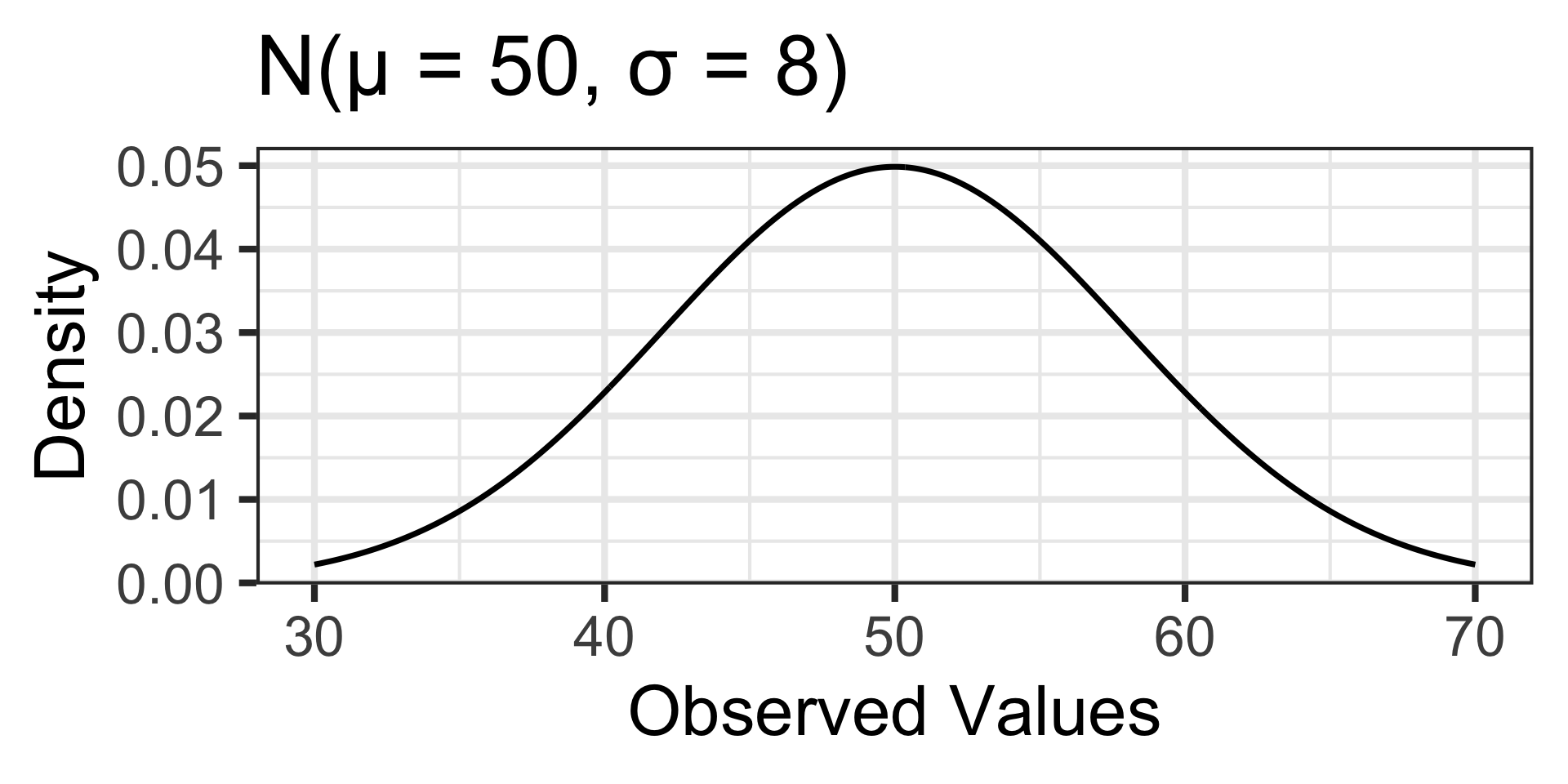
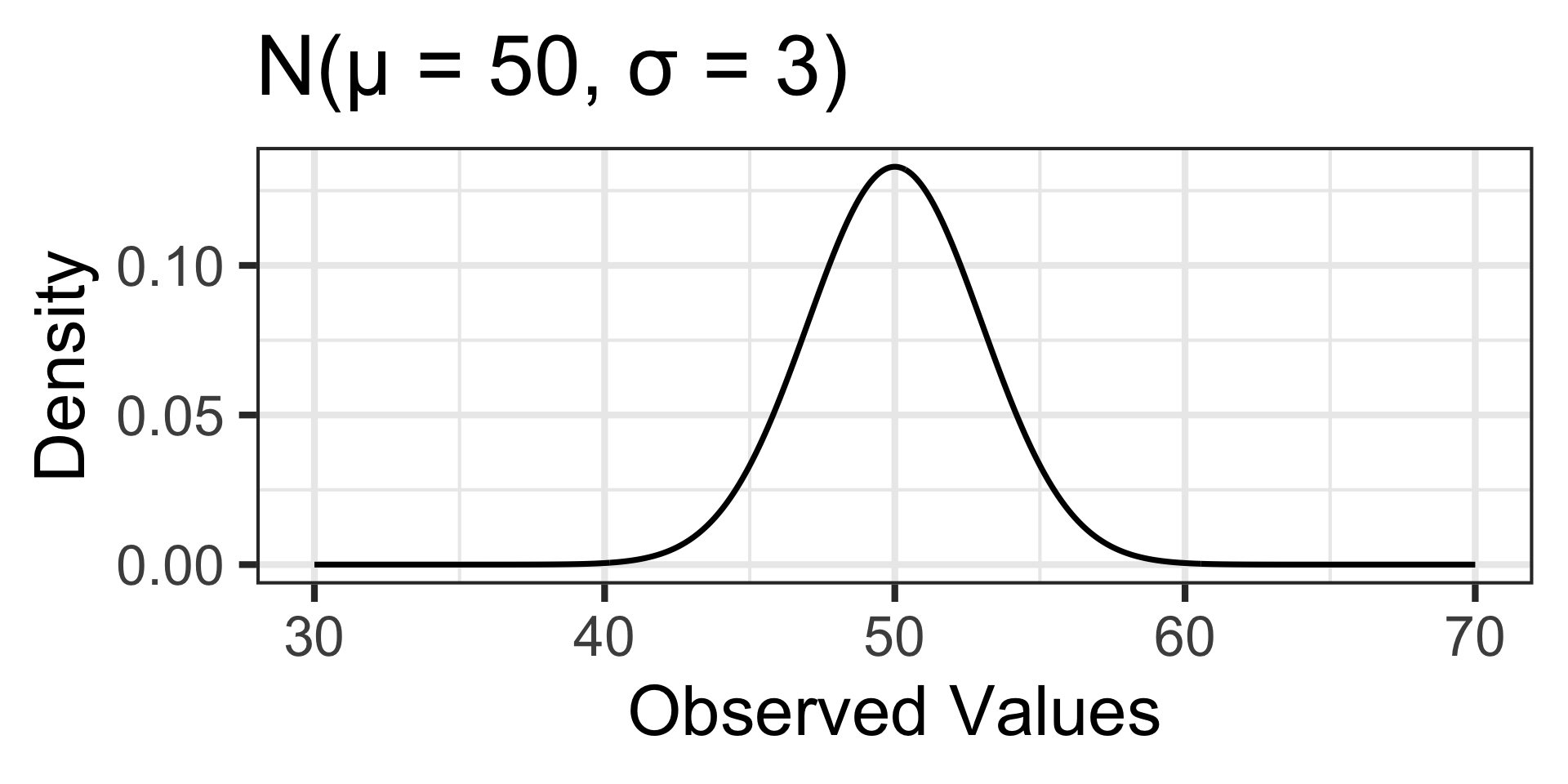
Completed Example: What’s the Buzz About Honey?
Senario: Beekeepers agree that the amount of honey collected from a typical hive over the summer is approximately normally distributed with a mean of 50 pounds and a standard deviation of 8 pounds. A beekeeper overseeing several locations monitors production at a particular site. At the end of the season, the beekeeper measures honey production from 15 randomly selected hives and observes an average of 47 pounds of honey per hive. What is the probability that a random sample of 15 hives would average 47 pounds or less of honey production?
The population distribution of honey production is approximately normal, so we can assume the sampling distribution will also be normal.
Honey production is a numerical variable, so the sampling distribution of the mean honey production from 15 hives is \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 50, S_E = 8/\sqrt{15}\right)}\).
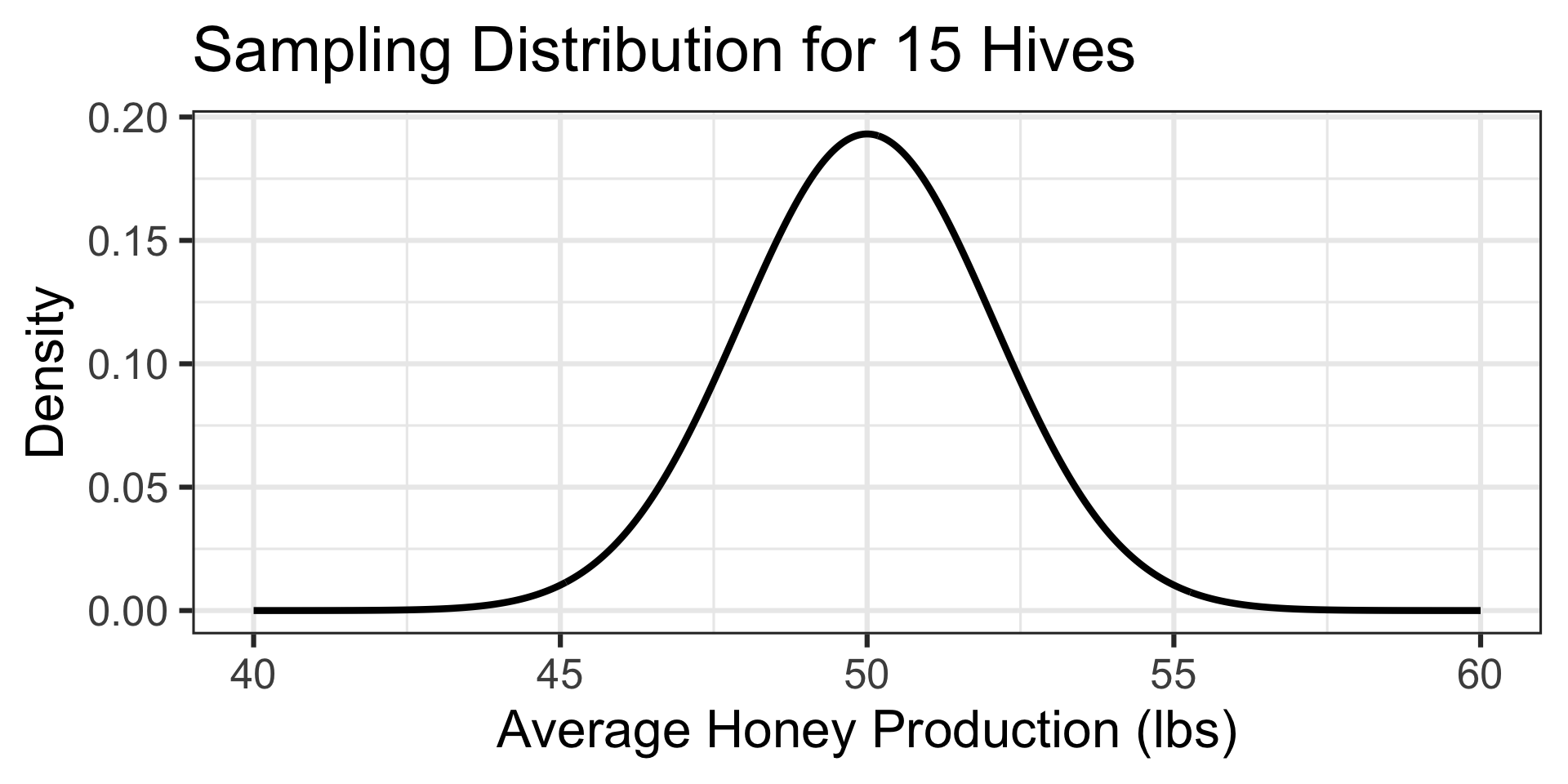
Completed Example: What’s the Buzz About Honey?
Senario: Beekeepers have found that the amount of honey collected from a typical hive over the summer is approximately normally distributed with a mean of 50 pounds and a standard deviation of 8 pounds. A beekeeper overseeing several locations is monitoring their production at a particular site. At the end of the season, the beekeeper measures honey production from 15 randomly selected hives at that site and observes an average of 47 pounds of honey per hive. What is the probability that a random sample of 15 hives would average 47 pounds or less of honey production?
The population distribution of honey production is approximately normal, so we can assume the sampling distribution will also be normal.
Honey production is a numerical variable, so the sampling distribution of the mean honey production from 15 hives is \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 50, S_E = 8/\sqrt{15}\right)}\).
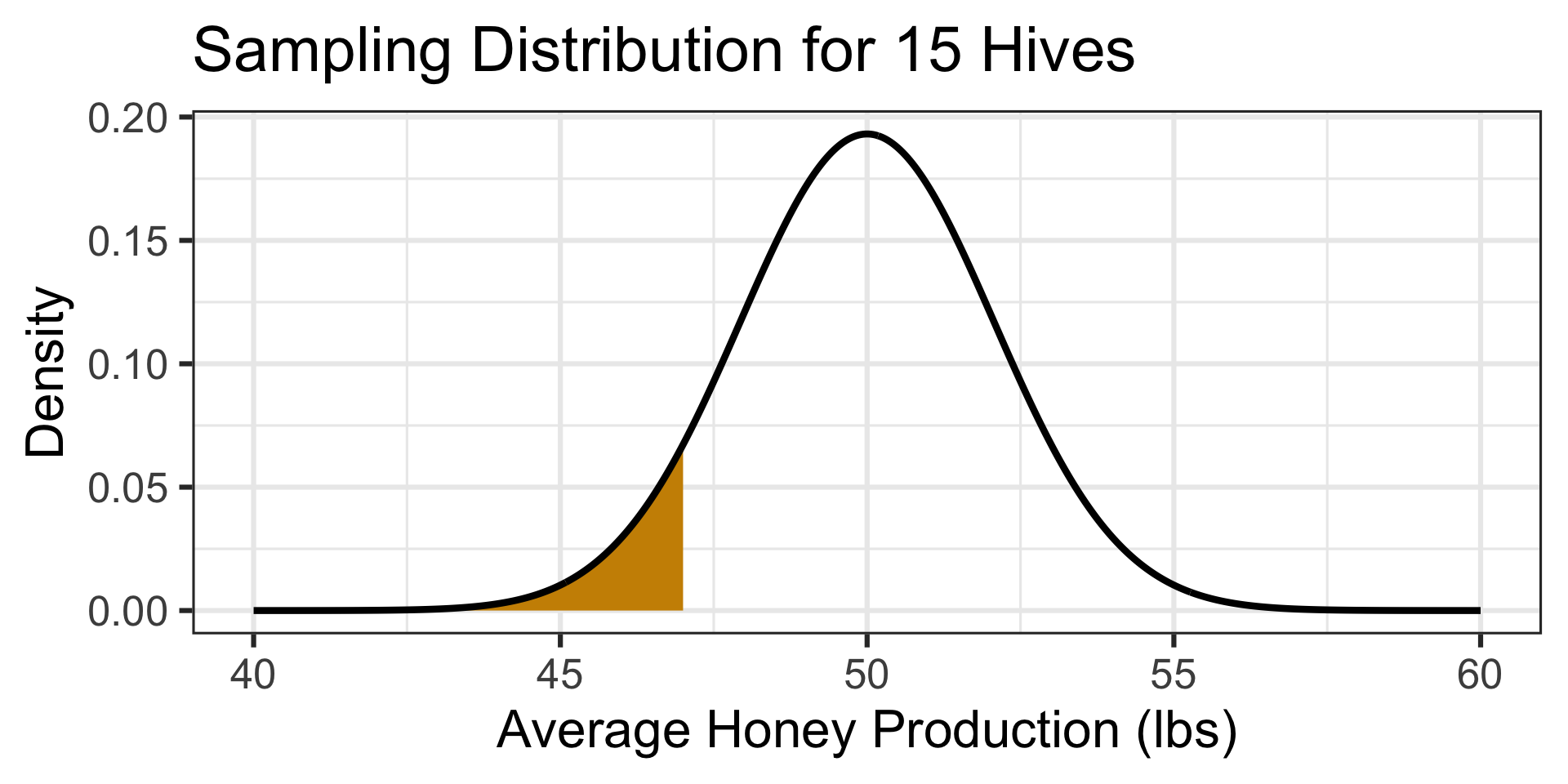
The probability of an average honey production of 47 pounds or less is…
Completed Example: What’s the Buzz About Honey?
Senario: Beekeepers have found that the amount of honey collected from a typical hive over the summer is approximately normally distributed with a mean of 50 pounds and a standard deviation of 8 pounds. A beekeeper overseeing several locations is monitoring their production at a particular site. At the end of the season, the beekeeper measures honey production from 15 randomly selected hives at that site and observes an average of 47 pounds of honey per hive. What is the probability that a random sample of 15 hives would average 47 pounds or less of honey production?
The population distribution of honey production is approximately normal, so we can assume the sampling distribution will also be normal.
Honey production is a numerical variable, so the sampling distribution of the mean honey production from 15 hives is \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 50, S_E = 8/\sqrt{15}\right)}\).
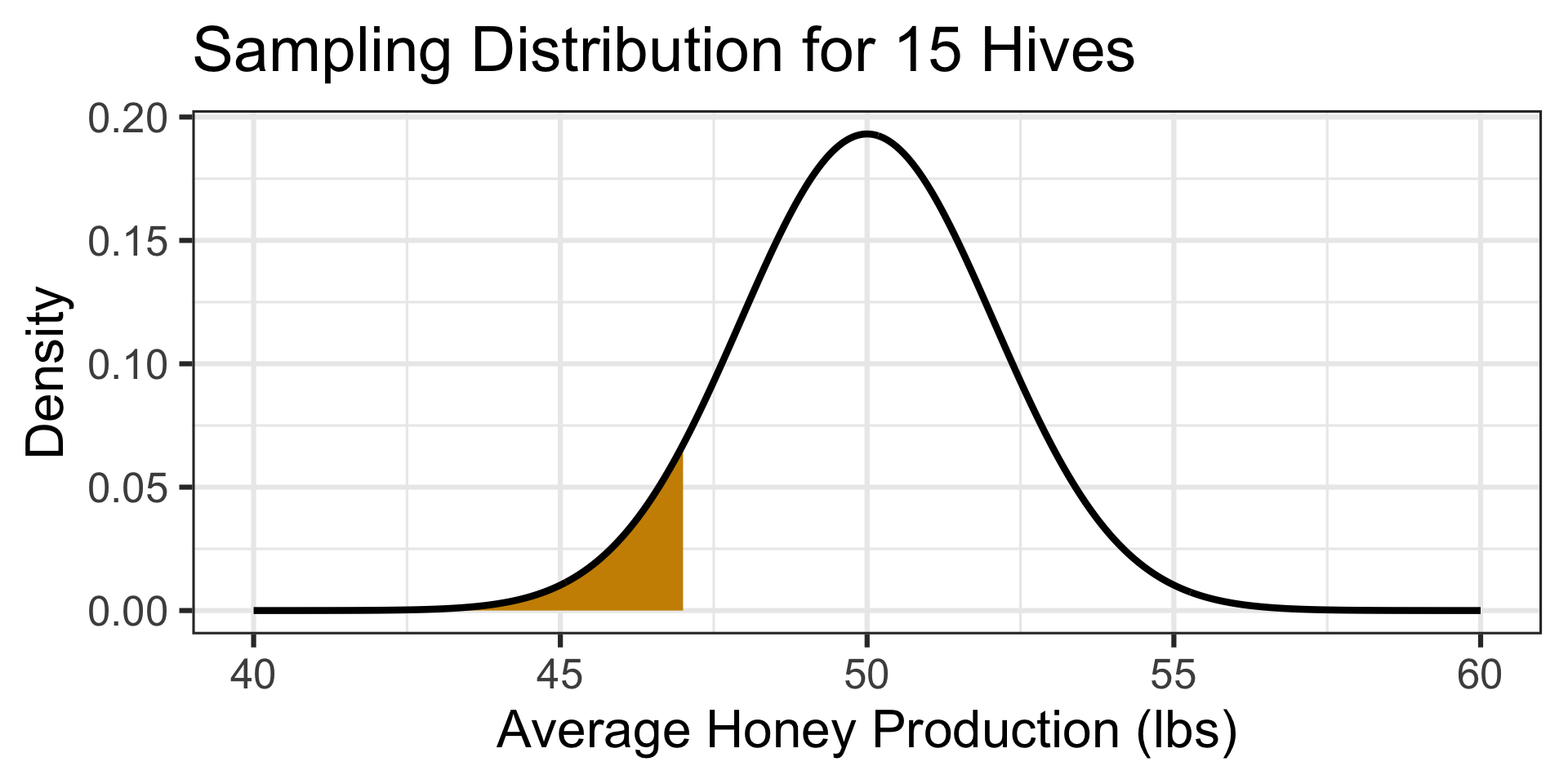
The probability of an average honey production of 47 pounds or less is…
pnorm(47, 50, 8/sqrt(15)) \(\approx\) 0.0732
Completed Example: What’s the Buzz About Honey?
Senario: Beekeepers have found that the amount of honey collected from a typical hive over the summer is approximately normally distributed with a mean of 50 pounds and a standard deviation of 8 pounds. A beekeeper overseeing several locations is monitoring their production at a particular site. At the end of the season, the beekeeper measures honey production from 15 randomly selected hives at that site and observes an average of 47 pounds of honey per hive. What is the probability that a random sample of 15 hives would average 47 pounds or less of honey production?
The population distribution of honey production is approximately normal, so we can assume the sampling distribution will also be normal.
Honey production is a numerical variable, so the sampling distribution of the mean honey production from 15 hives is \(\displaystyle{N\left(\mu, S_E = \sigma/\sqrt{n}\right)}\), which in this case is \(\displaystyle{N\left(\mu = 50, S_E = 8/\sqrt{15}\right)}\).
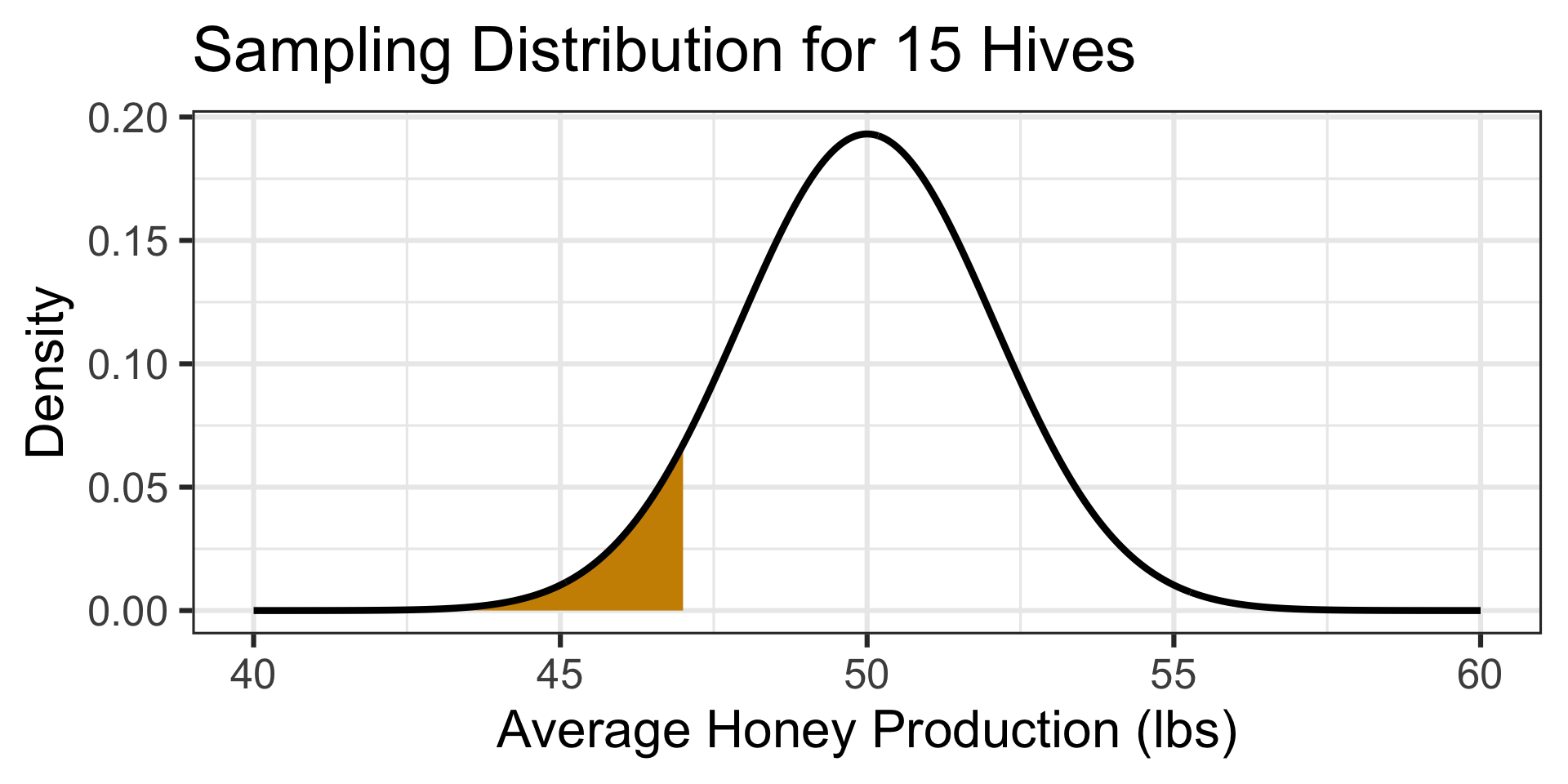
The probability of an average honey production of 47 pounds or less is…
pnorm(47, 50, 8/sqrt(15)) \(\approx\) 0.0732
A 7.32% chance of observing a result as bad as they observed means that such an average is not totally unexpected, but they may want to investigate the environment around this site to see if there are abnormal conditions impacting honey production.
Exit Ticket Task
Navigate to our MAT241 Exit Ticket Form, answer the questions, and complete the task below.
Note. Today’s discussion is listed as 9. The Sampling Distribution

Task: A large bottling facility fills juice bottles that are advertised as containing 20 ounces of juice. Individual bottle fill amounts vary, and the fill amounts are moderately right-skewed, with a population mean of 20 oz and a population standard deviation of 0.5 oz.
A quality control team randomly samples 47 bottles and records the average fill amount.
- Why shouldn’t we use a normal distribution as a model to estimate the probability that a single randomly selected bottle is filled to less than 19.9 oz?
- Describe the appropriate distribution, to use in estimating the probability that the sample mean fill amount (of the 47 bottles) is less than 19.9 oz.
- Calculate the probability that the average fill amount of a random sample of 47 bottles is less than 19.9 oz.